Adaptive Autonomous Recursive Moving AverageIntroduction
Using conditions in filters is a way to make them adapt to those, i already used this methodology in one of my proposed indicators ARMA which gave a really promising adaptive filter, ARMA tried to have a flat response when dealing with ranging market while following the price when the market where trending or exhibiting volatile movements, the filter was terribly simple which is one of its plus points but its down points where clearly affecting its performance thus making it almost impractical.
Today i propose a new filter A2ARMA which aim to correct all the bad behaviours of ARMA while having a good performance on various markets thanks to the added adaptivity.
Fixes And Changes
ARMA was dealing with terribles over/under-shoots which affected its performance, adding a zero-lag option made the thing even worse, in order to fix those mistakes i first cleaned the code, then i removed the offset for src in d , this choice is optional but the filter is sometimes more accurate this way.
The major change is the use of an adaptive moving average instead of the triangular moving average that smoothed the output, this adaptive moving average is calculated using exponential averaging while using the efficiency ratio as smoothing variable, this choice surprisingly removed the majority of overshoots while adding more adaptivity to the filter.
The Indicator
The Indicator work the same way as ARMA, not reacting during flat market periods while following the price when this one is volatile or trending. length control the smoothing amount while gamma determine how the filter is affected during flat market periods, gamma = 0 is just a double smoothed adaptive moving average, higher values of gamma will filter flat markets with a certain degree.
On Intel Corp with gamma = 0, i want to filter the flat period starting at July 10, gamma = 3 will certainly help us on this task.
Hooray, the problem appear to be solved ! Lower values of gamma also produce desirable effect as shown below :
gamma = 2
So far so good, but gamma or length might have different optimal values depending on the market, also problems still exists as shown here :
Seagate is tricky, gamma at 2.4 might help
The relationship between length and gamma is somewhat complicated.
On Different Markets
While some filters will process market price the same way no matter the market they are affected, A2ARMA will change drastically depending of the market.
On AMD
On EURUSD
On BTCUSD
Comparison With ARMA
ARMA with parameters roughly matching A2RMA, overall most of the problems i wanted to fix where indeed fixed.
Conclusion
A huge thanks for the support i received during this "Blank Page" period i'am suffering, ARMA was an indicator i really wanted to further develop without giving up on the code simplicity and i think this version might provide useful results, we can also notice that the decision making is easier with this version of the indicator thanks to the added coloring (which would have been impossible with ARMA).
My work don't have license attached to it, feel free to modify and share your findings, mentioning is appreciated :)
Thanks for reading !
Smooth

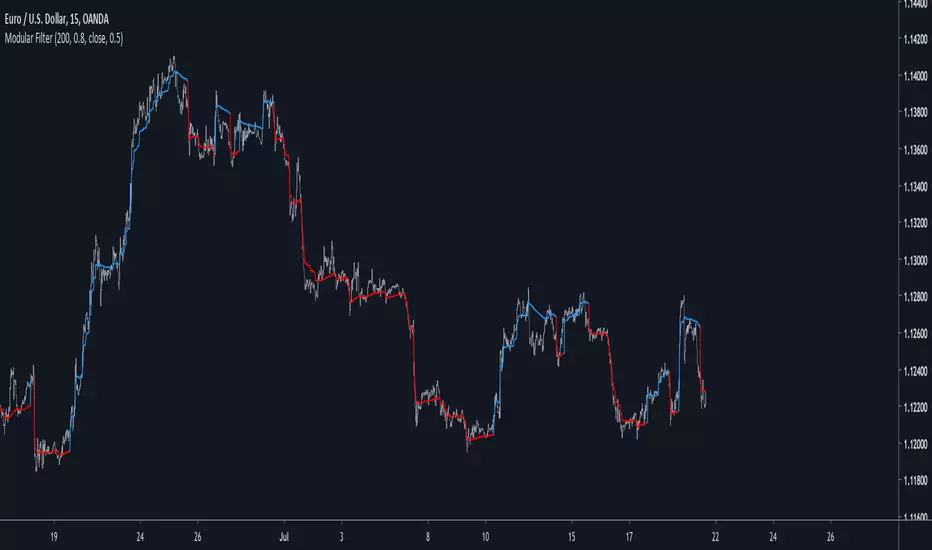
Modular Filter - Spot Trends And Smooth PriceIntroduction
This indicator can have a wide variety of usages, and since it is based on exponential averaging then the whole indicator can be made adaptive, thus ending up with a really promising tool. This indicator who can both smooth price and act as a trailing stop depending on user preferences, i tried to make it as reactive, stable and efficient as possible in order to both smooth and spot trends, lets view it more in depth.
The Indicator
line 8 and 9 create two bands, one upper and one lower, then based on certain conditions the indicator will only return a certain band or an average of both with different weights, this weight is controlled by the beta parameter, values of 1 will return a simple filter while values of 0 will return a classical trailing stop.
beta = 0
The indicator can use output values as input, thus using smoother values as input, in order to do so just check "Feedback", this help the overall output to be smoother as well as giving more long terms signals
The amount of feedback is controlled by the feedback weighting parameter, lower values will weight more the output values thus creating smoother results.
Feedback weighting of 0.2
Using beta = 0 thus having the indicator act as a trailing stop while having the feedback option activated return more long terms signals. Notes that the colors are based on the initial conditions of the indicator.
Conclusion
You can replace length and change alpha for any smoothing variable such as the efficiency ratio or anything with scale (1,0), same goes for beta and the feedback weighting parameter, this is why the indicator is "Modular" in addition of providing different usages. This indicator can look like cluster filters (smooth price monarch, forexguru) , filters with the ability to follow the price quite fine while being stables. I really hope you find an use to it.
Thanks for reading !
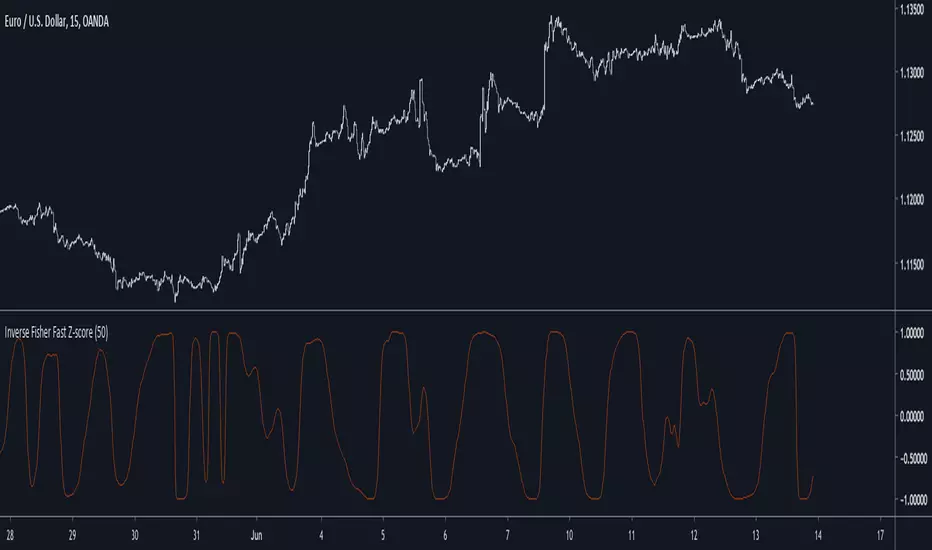
Inverse Fisher Fast Z-scoreIntroduction
The fast z-score is a modification of the classic z-score that allow for smoother and faster results by using two least squares moving averages, however oscillators of this kind can be hard to read and modifying its shape to allow a better interpretation can be an interesting thing to do.
The Indicator
I already talked about the fisher transform, this statistical transform is originally applied to the correlation coefficient, the normal transform allow to get a result similar to a smooth z-score if applied to the correlation coefficient, the inverse transform allow to take the z-score and rescale it in a range of (1,-1), therefore the inverse fisher transform of the fast z-score can rescale it in a range of (1,-1).
inverse = (exp(k*fz) - 1)/(exp(k*fz) + 1)
Here k will control the squareness of the output, an higher k will return heavy side step shapes while a lower k will preserve the smoothness of the output.
Conclusion
The fisher transform sure is useful to kinda filter visual information, it also allow to draw levels since the rescaling is in a specific range, i encourage you to use it.
Notes
During those almost 2 weeks i was even lazier and sadder than ever before, so i think its no use to leave, i also have papers to publish and i need tv for that.
Thanks for reading !
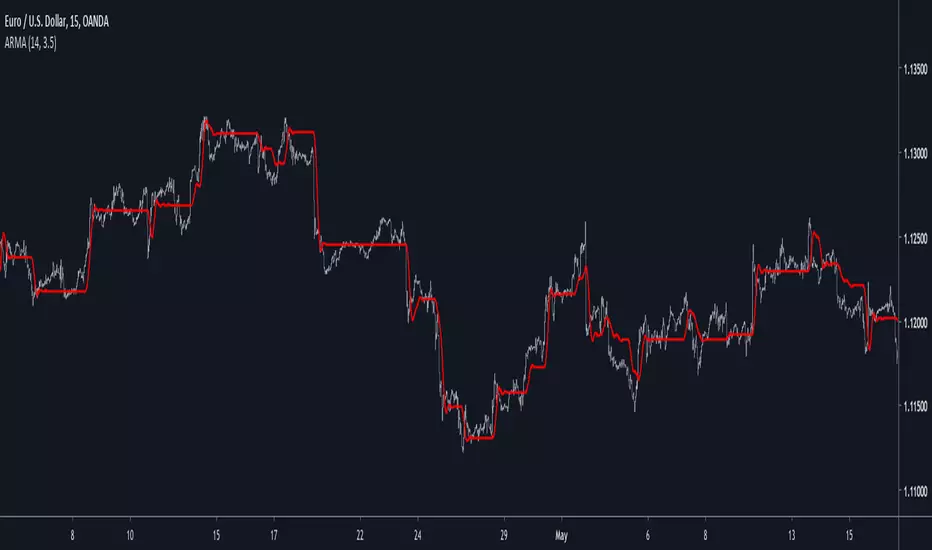
Autonomous Recursive Moving AverageIntroduction
People often ask me what is my best indicators, i can't really respond to this question with a straight answer but i would say you to check this indicator. The Autonomous Recursive Moving Average (ARMA) is an adaptive moving average that try to minimize the sum of squares thanks to a ternary operator, this choice can seem surprising since most of the adaptive moving averages adapt to a smoothing variable thanks to exponential averaging, but there are lot of downsides to this method, i really wanted to have a flat filter during flat markets and this is what i achieved.
The Indicator
length control the amount of smoothing during trending periods, gamma is the trend sensitivity threshold, higher values of gamma will make an overall flat filter, adjust gamma to skip ranging markets.
gamma = 2, we can adjust to 3 while preserving smoothing reactivity with trading periods.
gamma = 3
low length and higher gamma create more boxy result, the filter add overshoots directly in the output, its unfortunate.
The Zero-Lag option can reduce the lag as well as getting additional flat results without changing gamma.
Conclusion
The indicator need work, but i can't leave without publishing it, the overshoots are a big problems, changing sma for another stable filter can help. I hope you find an use to it, i really like this indicator.
Thanks for reading
Simple CycleIntroduction
A simple and really clean cycle oscillator, in fact its quite precise even if the script use recursion which can sometime produce totally uncorrelated results.
On The Code
The calculations start with a who is a smoothing/averaging constant. Then comes src who is the input and is defined as the sum of the closing price with the output, then the output is high-pass filtered in b , after that the output is just the weighted average of the input change with b .
All those recursions and detrending steps make the indicator able to highlights cycles.

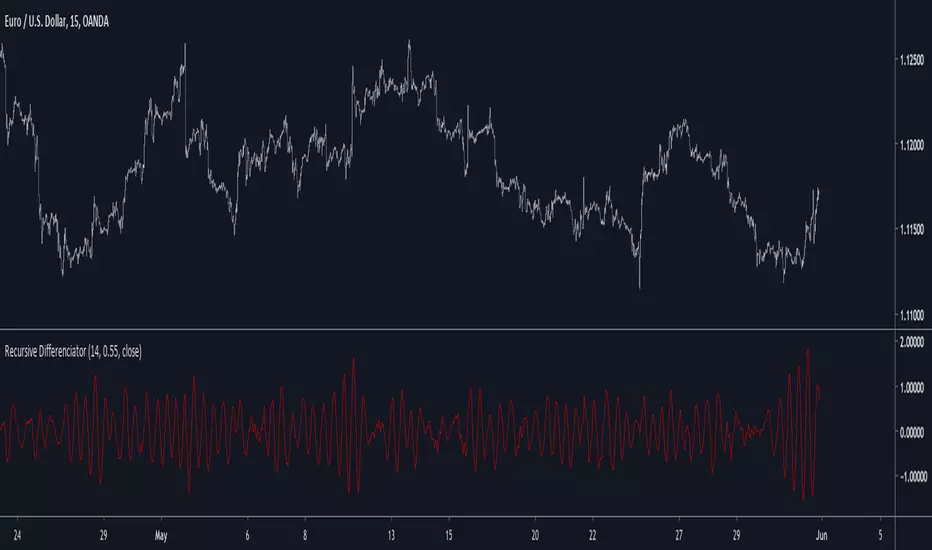
Recursive DifferenciatorIntroduction
Cycles can be spotted by using a wide range of methods, most of them will involve bandpass filtering, here i will show a method using recursion with the change() function.
The Indicator
As i explained in other indicators using recursion i posted rescaling the input is important, i will use the rsi of an exponential moving average as input. alpha control the amount of output the indicator will use as input, values closer to 0.5 will use more input resulting in more periodic results.
Lowering alpha when length is higher can help get more periodic results.
Conclusion
I have showed a new cycle indicator using recursion. Recursion with oscillators can highlights cycles in price thus being easier to predict.
Thanks for reading !
Zero-Lag Smoothed CycleOld indicator ! But its a simple trick to have a zero-lag smoothing effect, i think i did it because the smoothing was kinda asymmetrical with the detrended line. So even if the result appear quite good take into account that the detrended line isn't always correlated with the price.

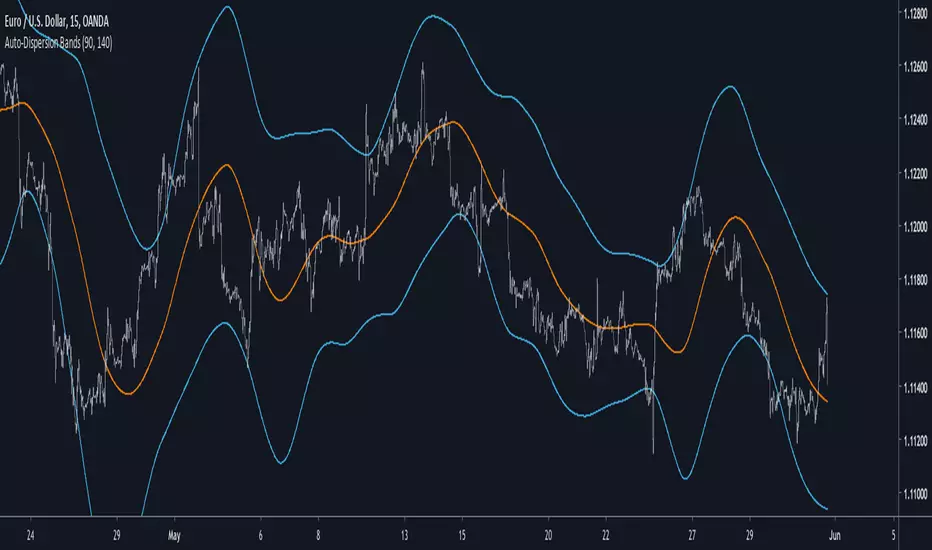
Auto-Dispersion BandsIntroduction
A really old indicator as well, thus i have no much ideas of what is going on with it, but i know that those bands returns good reversals points. The indicator don't use standard deviation, instead its a simple differencing of the price and the price length bars back who will provide a dispersion measurement, thus the name auto-dispersion.
The Indicator
The smooth parameter allow the band to cross the price, if smooth is low the chance of crosses are lower.
smooth = 3
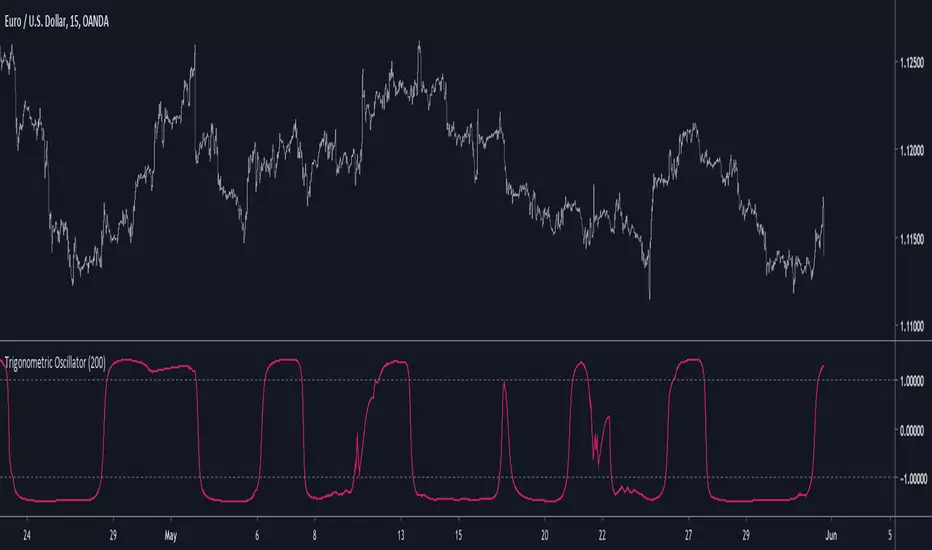
Trigonometric OscillatorIts a pretty old script and i have absolutely no idea how i did it, the code kinda look like the phase wrapping/unwrapping formula. This indicator is an oscillator, sometimes its reactivity is impressive so i think its a good idea to post it, feel free to experiment with it.
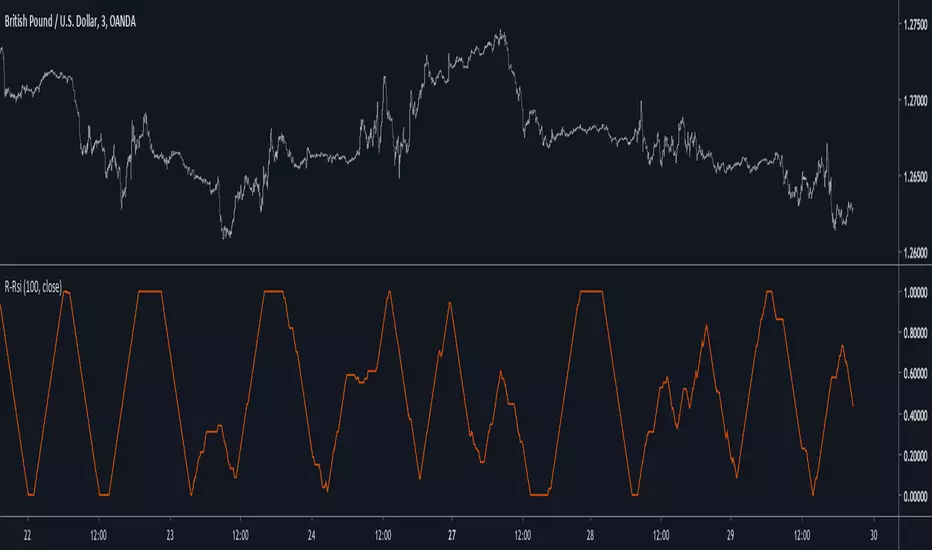
Recursive RsiIntroduction
I have already posted a classic indicator using recursion, it was the stochastic oscillator and recursion helped to get a more predictive and smooth result. Here i will do the same thing with the rsi oscillator but with a different approach. As reminder when using recursion you just use a fraction of the output of a function as input of the same function, i say a fraction because if you feedback the entire output you will just have a periodic function, this is why you average the output with the input.
The Indicator
The indicator will use 50% of the output and 50% of the input, remember that when using feedback always rescale your input, else the effect might be different depending on the market you are in. You can interpret the indicator like a normal rsi except if you plan to use the 80/20 level, depending on length the scale might change, if you need a fixed scale you can always rescale b by using an rsi or stochastic oscillator.
Conclusion
I have presented an rsi oscillator using a different type of recursion structure than the recursive stochastic i posted in the past, the result might be more predictive than the original rsi. Hope you like it and thanks for reading !
Turbo TriggerSome Words
This indicator is a collaboration between me and Himeyuri, i encourage you to check her profile and follow her www.tradingview.com
Introduction
A lot of indicators include a "trigger" line, it can be a smoothed version of another input, in this case the trigger will generate signals from his crosses with the input. The purpose of this indicator is to provide a fast trigger line to generate earlier signals as well as avoiding some whipsaw.
The Indicator
There are two lines, a bull line (blue) and the trigger (orange) , when the trigger cross over the bull line a buy signal is generated, when the trigger cross under the bull line a sell signal is generated. The trigger is made from the smoothed difference between the bull and bear line.
smooth control the smoothness of the output. The Bull/Bear Mode is an idea proposed by Himeyuri that involve plotting the bear line instead of the trigger.
Bull/Bear Mode, the lines are somewhat asymmetrical from each others.
Conclusion
We have showcased a new indicator who use a really fast trigger line to generate earlier signals, if some are way to earlier you can still increase smooth in order to correct reactivity. I hope you find a use to it.
Thanks for reading !
A big thanks to Himeyuri who is a great student and great pinescripter.

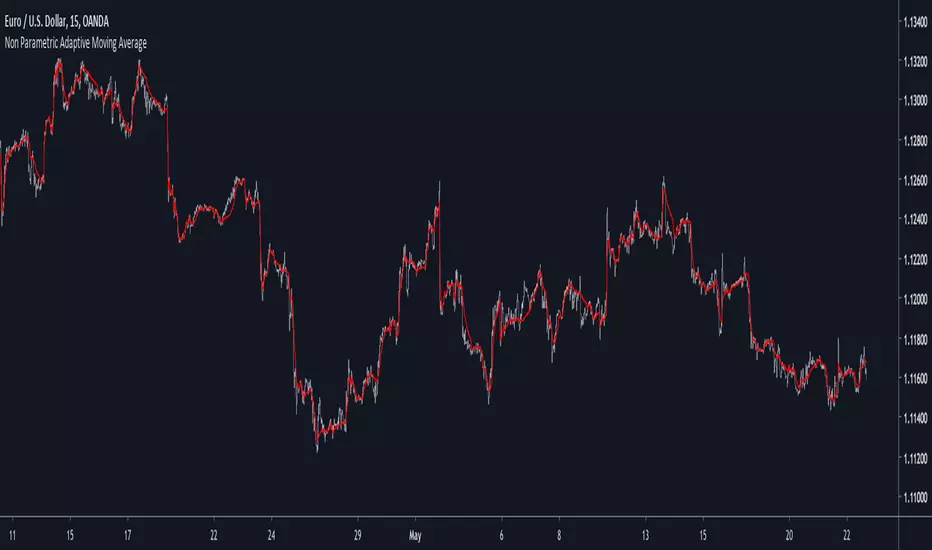
Non Parametric Adaptive Moving AverageIntroduction
Not be confused with non-parametric statistics, i define a "non-parametric" indicator as an indicator who does not have any parameter input. Such indicators can be useful since they don't need to go through parameter optimization. I present here a non parametric adaptive moving average based on exponential averaging using a modified ratio of open-close to high-low range indicator as smoothing variable.
The Indicator
The ratio of open-close to high-low range is a measurement involving calculating the ratio between the absolute close/open price difference and the range (high - low) , now the relationship between high/low and open/close price has been studied in econometrics for some time but there are no reason that the ohlc range ratio may be an indicator of volatility, however we can make the hypothesis that trending markets contain less indecision than ranging market and that indecision is measured by the high/low movements, this is an idea that i've heard various time.
Since the range is always greater than the absolute close/open difference we have a scaled smoothing variable in a range of 0/1, this allow to perform exponential averaging. The ratio of open-close to high-low range is calculated using the vwap of the close/high/low/open price in order to increase the smoothing effect. The vwap tend to smooth more with low time frames than higher ones, since the indicator use vwap for the calculation of its smoothing variable, smoothing may differ depending on the time frame you are in.
1 minute tf
1 hour tf
Conclusion
Making non parametric indicators is quite efficient, but they wont necessarily outperform classical parametric indicators. I also presented a modified version of the ratio of open-close to high-low range who can provide a smoothing variable for exponential averaging. I hope the indicator can help you in any way.
Thanks for reading !
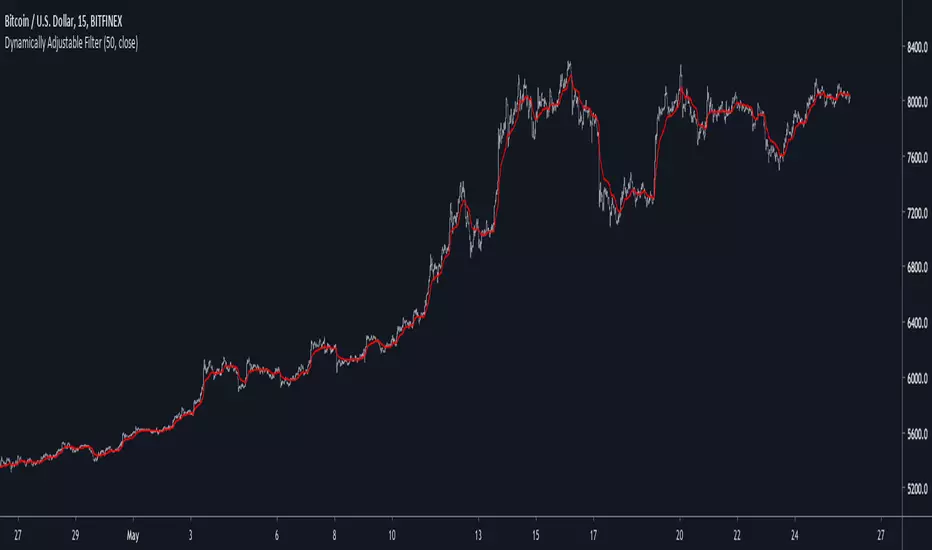
Dynamically Adjustable FilterIntroduction
Inspired from the Kalman filter this indicator aim to provide a good result in term of smoothness and reactivity while letting the user the option to increase/decrease smoothing.
Optimality And Dynamical Adjustment
This indicator is constructed in the same manner as many adaptive moving averages by using exponential averaging with a smoothing variable, this is described by :
x= x_1 + a(y - x_1)
where y is the input price (measurements) and a is the smoothing variable, with Kalman filters a is often replaced by K or Kalman Gain , this Gain is what adjust the estimate to the measurements. In the indicator K is calculated as follow :
K = Absolute Error of the estimate/(Absolute Error of the estimate + Measurements Dispersion * length)
The error of the estimate is just the absolute difference between the measurements and the estimate, the dispersion is the measurements standard deviation and length is a parameter controlling smoothness. K adjust to price volatility and try to provide a good estimate no matter the size of length . In order to increase reactivity the price input (measurements) has been summed with the estimate error.
Now this indicator use a fraction of what a Kalman filter use for its entire calculation, therefore the covariance update has been discarded as well as the extrapolation part.
About parameters length control the filter smoothness, the lag reduction option create more reactive results.
Conclusion
You can create smoothing variables for any adaptive indicator by using the : a/(a+b) form since this operation always return values between 0 and 1 as long as a and b are positive. Hope it help !
Thanks for reading !
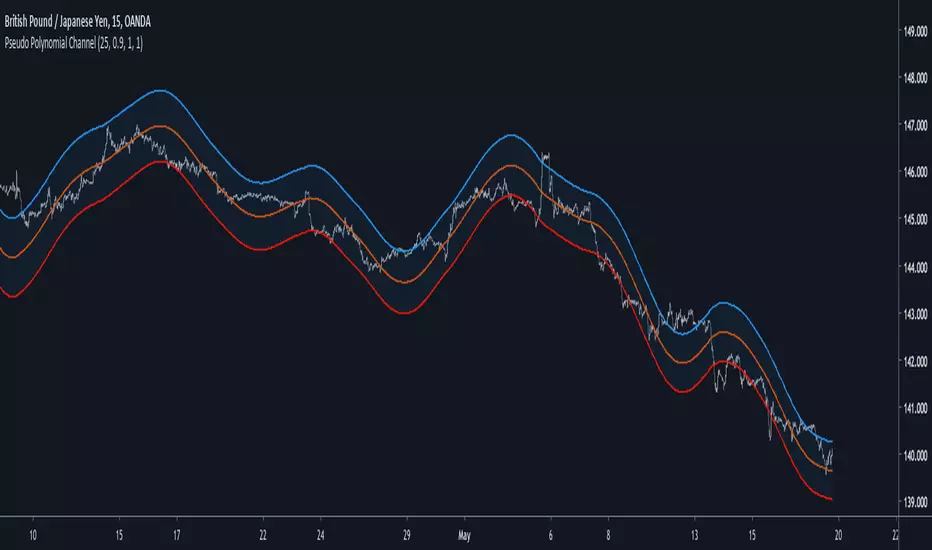
Pseudo Polynomial ChannelIntroduction
Back when i started using pine i made a script called periodic channel who aimed to rescale an average correlated sine wave to the price...don't worked very well. So i tried to fix problems induced by the indicator without much success, i had to redo it from scratch while abandoning the idea of rescaling correlated smooth functions to the price, at that time i also received requests regarding polynomial channel, some plateformes included this indicator, this led me to the idea to estimate it in order to both respond to the periodic channel problems and the requests i received, i have tried many many things and recently i tweaked a linear extrapolation to have an approximation.
Linear Extrapolation To Pseudo Polynomial Regression
I could be wrong but a polynomial regression must use constant parameters in order to provide a really smooth output, at least constant for a set of time. The moving averages forms (Savitzky-Golay moving average) who smooth polynomials across a window to the data don't have such smoothness, so how to estimate a polynomial regression while having a parameter providing control over the smoothness, a response to this is by using a recursive linear extrapolation. I posted a linear extrapolation indicator long ago, i used the same formula while adding a function to morph the output and the input in the form of :
morph * output + (1-morph) * input
How can this provide an estimate of a polynomial regression ? Well i'm not even sure myself but if you use the output as input (morph = 1) for the linear extrapolation function you should get a rough estimate of a line, this is what i thought at first and it proved to be right
Based on this observation i thought that it would be possible to get polynomial results by lowering morph, and as expected it worked well but showed a periodic pattern, this is why i smooth k in line 10.
0.9 for morph work well, higher values create sometimes smoother results but damage heavily the estimation.
Parameters
Morph have been introduced earlier, it control the amount of output and input the linear extrapolation should process, lower values create rougher but more stables results, if you see that the estimation is going nuts lower morph or change length, also lower length if you increase morph .
High overshoot, morph to 0.8 can help have a better estimation at the cost of less smoothness.
Length control the indicator smoothing, this parameter differ heavily from other filters, therefore low values can create mid/long term smoothing, it can also depend on which market instrument you are applying it, so there are no fixed optimal length.
Mult control how spread the bands are, to do so mult multiply the cumulative mean error, you can change this error measurement by anything you want like standard deviation/atr/range but take into account that you may create a separate parameter to control the error instead of length . Mult can be a float and like length can have different optimal values depending on the market the indicator is applied to.
Flatten do exactly what is name imply, it flatten the overall output to have a better estimation, can be a float. The result is less smooth.
Flatten = 2
More Exemples
BTCUSD length = 25 and mult = 4
XPDUSD length = 25 and mult = 1
ALPHABET length = 6 and morph = 0.99
Conclusion
I tried to estimate a polynomial channel by using recursion in the linear extrapolation function. This build is way more stable than the periodic channel but its still a bit inaccurate in my opinion. I hope this code can still help someone build something really nice, if so share your results :)
I apologize for those expecting a legit polynomial channel build but i really don't know how to do that, as i said parameters for the regression must be constants, i hope it still fine :)
Thanks for reading !
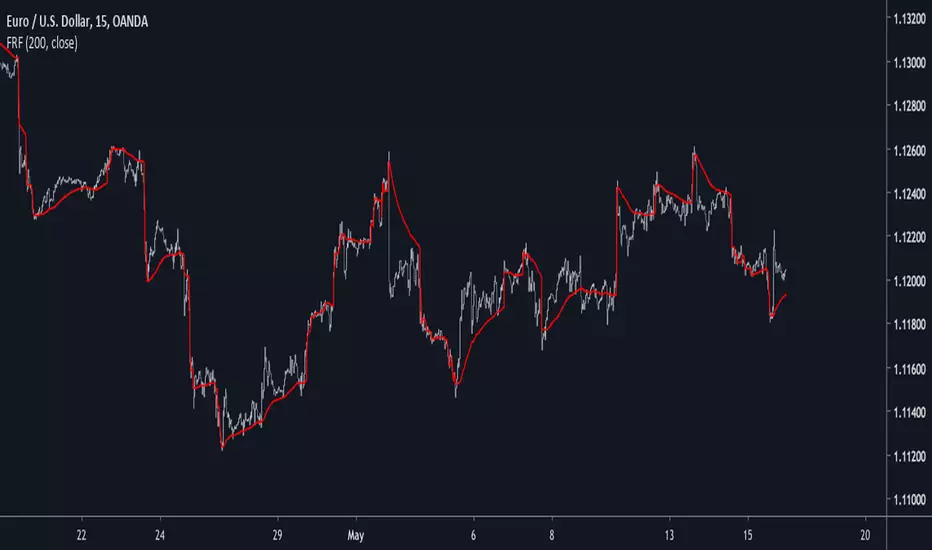
Falling-Rising FilterIntroduction
This is a modification of an old indicator i made. This filter aim to adapt to market trend by creating a smoothing constant using highest and lowest functions. This filter is visually similar to the edge-preserving filter, this similarity can make this filter quite good for MA cross strategies.
On The Filter Code
a = nz(a ) + alpha*nz(error ) + beta*nz(error )
The first 3 terms describe a simple exponential filter where error = price - a , beta introduce the adaptive part. beta is equal to 1 when the price is greater or lower than any past price over length period, else beta is equal to alpha , someone could ask why we use two smoothing variable (alpha, beta) instead of only beta thus having :
a = nz(a ) + beta*nz(error )
well alpha make the filter converge faster to the price thus having a better estimation.
In blue the filter using only beta and in red the filter using alpha and beta with both length = 200 , the red filter converge faster to the price, if you need smoother results but less precise estimation only use beta .
Conclusion
I have presented a simple indicator using rising/falling functions to calculate an adaptive filter, this also show that when you create an exponential filter you can use more terms instead of only a = a + alpha*(price - a ) . I hope you find this indicator useful.
Thanks for reading !
Savitzky-Golay Smoothing FilterThe Savitzky-Golay Filter is a polynomial smoothing filter.
This version implements 3rd degree polynomials using coefficients from Savitzky and Golay's table, specifically the coefficients for a 5-, 7-, 9-, 15- and 25-point window moving averages.
The filters are offset to the left by the number of coefficients (n-1)/2 so it smooths on top of the actual curve.
You can turn off some of the smoothing curves, as it can get cluttered displaying all at once.
Any feedback is very welcome.

Smoothed Delta's Ratio OscillatorIntroduction
Scaled and smoothed oscillators can provide easy to read/use information regarding price, therefore i will introduce a new oscillator who create smooth results and use a fast and practical scaling method. In order to allow for even more smoothness the option to smooth the input with a lsma has been added.
Scaling Using Changes
In this indicator scaling in a range of (1,-1) is achieved through the following calculations :
a = sma(abs(change(src,length)),length)
b = change(sma(src,length),length)
c = b/a
where src is our input. The two elements a and b are quite similar, a smooth the absolute change of the input over length period while b calculate the change of the smoothed input over length period, this make a > b and able us to perform scaling in a range of (1,-1).
The Indicator Parameters
Length control the differencing/smoothing period of the indicator, greater values create smoother and less volatile results, this mean that the oscillator will tend to be equal to 1 or -1 in a longer period of time if length is high. The smooth option allow for even smoother results by enabling the input to be smoothed by a lsma of length period.
Conclusions
I presented a smooth oscillator using a new rescaling technique. Parameters can be separated to provide different results, i believe the code is simple enough for everyone to modify it in order to provide interesting creations.

Japanese Correlation CoefficientIntroduction
This indicator was asked and named by a trading meetup participant in Sevilla. The original question was "How to estimate the correlation between the price and a line as easy as possible", a question who got little attention. I previously proposed a correlation estimate using a modification of the standard score (see at the end of the post) for the estimation of a Savitzky-Golay moving average (LSMA) of order 1, however something faster could maybe be done and this is why i accepted the challenge.
Japanese Correlation
Correlation is defined as the linear relationship between two variables x and y , if x and y follow the same direction then the correlation increase else decrease. The correlation coefficient is always equal or below 1 and equal or above -1, it also have to be taken into account that this coefficient is quite smooth. Smoothing is not a problem, scaling however require more attention, high price > closing price > low price, therefore scaling can be done. First we smooth the closing/high/low price with a simple moving average of period p/2 , then we take the difference of the smoothed close with the smoothed close p/2 bars back, this result is then divided by the difference between the highest smoothed high's with the lowest smoothed low's over period p/2 .
Since we use information provided by candlesticks (close/high/low) i have been asked to publish this estimator with the name Japanese correlation coefficient , this name don't imply the use of data from Japanese markets, "Japanese" is used because of the candlestick method coming from Japan.
Comparison
I compare this estimation with the correlation coefficient provided in pinescript by the correlation function.
The estimation in orange with the original correlation coefficient using n as independent variable in blue with both length = 50.
comparison with length = 200.
Conclusion
I have shown that it is possible to roughly estimate the correlation coefficient between price and a linear function by using different price information. Correlation can be further estimated by using homogeneous bridge OHLC volatility estimators thus making able the use of different independent variables. I really hope you like this indicator and thanks to the meetup participant asking the question, i had a lot of fun making the indicator.
An alternative method

Linear Quadratic Convergence Divergence OscillatorIntroduction
I inspired myself from the MACD to present a different oscillator aiming to show more reactive/predictive information. The MACD originally show the relationship between two moving averages by subtracting one of fast period and another one of slow period. In my indicator i will use a similar concept, i will subtract a quadratic least squares moving average with a linear least squares moving average of same period, since the quadratic least squares moving average is faster than the linear one and both methods have low-lag this will result in a reactive oscillator.
LQCD In Details
A quadratic least squares moving average try to fit a quadratic function (parabola) to the price by using the method of least squares, the linear least squares moving average try to fit a line. Non-linear fit tend to minimize the sum of squares in non-linear data, this is why a quadratic method is more reactive. The difference of both filters give us an oscillator, then we apply a simple moving average to this oscillator to provide the signal line, subtracting the oscillator and its signal line give us the histogram, those two last steps are the same used in the MACD.
Length control the period of the quadratic/linear moving average. While the MACD use a signal line for plotting the histogram i also added the option to plot the momentum of the quadratic moving average instead, the result is smoother and reduce irregularities, in order to do so just check the differential option in the parameter box.
The period of the signal line and the momentum are both controlled by the signal parameter.
A predictive approach can be made by subtracting the histogram with the signal line, this process make the histogram way more predictive, in order to do so just check the predictive histogram option in the parameter box.
Predictive histogram with simple histogram option. The differential mode can also be used with the predictive parameter, this result in a smoother but less reactive prediction.
Information Interpretation
The amount of information the MACD can give us is high. We can use the histogram as signal generator, or the if the oscillator is over/under 0, combine the oscillator/signal line with histogram, combinations can provide various systems. Some traders use the histogram as signal generator and use the cross between the histogram and the signal line as a stop signal, this method can avoid some whipsaw trades. The study of divergences with the price is also another method.
Conclusion
This oscillator aim to show the same amount of information as the MACD with a similar calculation method but using different kind of filters as well as eliminating the need to use two separates periods for the moving averages calculation, its still possible to use different periods for the quadratic/linear moving average but the results can be less accurate. This indicator can be used like the MACD.

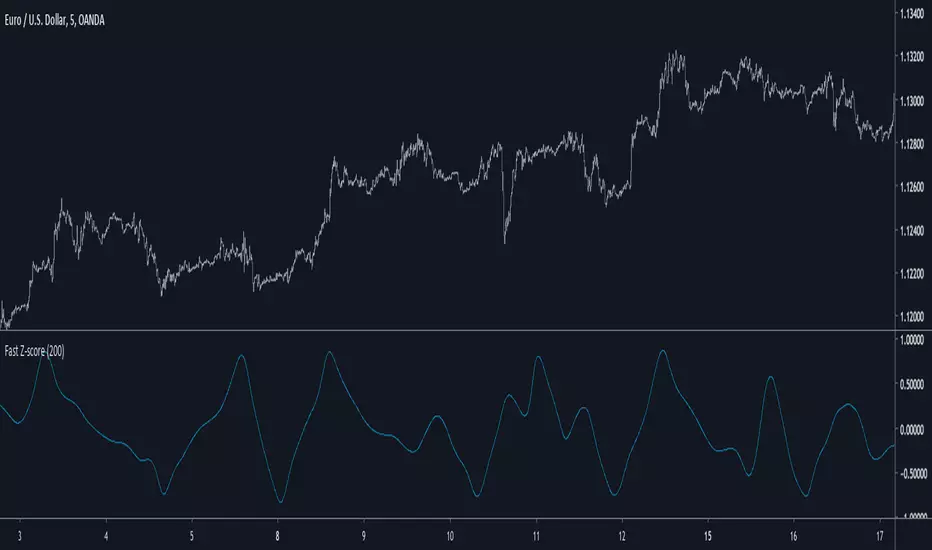
Fast Z-ScoreIntroduction
The ability of the least squares moving average to provide a great low lag filter is something i always liked, however the least squares moving average can have other uses, one of them is using it with the z-score to provide a fast smoothing oscillator.
The Indicator
The indicator aim to provide fast and smooth results. length control the smoothness.
The calculation is inspired from my sample correlation coefficient estimation described here
Instead of using the difference between a moving average of period length/2 and a moving average of period length , we use the difference between a lsma of period length/2 and a lsma of period length , this difference is then divided by the standard deviation. All those calculations use the price smoothed by a moving average as source.
The yellow version don't divide the difference by a standard deviation, you can that it is less reactive. Both version have length = 200
Conclusion
I presented a smooth and responsive version of a z-score, the result could be used to estimate an even faster lsma by using the line rescaling technique and our indicator as correlation coefficient.
Hope you like it, feel free to modify it and share your results ! :)
Notes
I have been requested a lot of indicators lately, from mt4 translations to more complex time series analysis methods, this accumulation of work made that it is impossible for me to publish those within a short period of time, also some are really complex. I apologize in advance for the inconvenience, i will try to do my best !
Absolute Strength MTF IndicatorIntroduction
The non-signal version of the absolute strength indicator from fxcodebase.com requested by ernie76 . This indicator originally from mt4 aim to estimate the bullish/bearish force of the market by using various methods.
The Indicator
Two lines are plotted, a bull line (blue) representing the bullish/buying force and a bear one (red) representing the bearish/selling force, when the bull line is greater than the bear line the market is considered to be strongly bullish, else strongly bearish.
The indicator use various method, Rsi, stochastic, adx. The Rsi method is the one by default.
The stochastic method is less reactive but smoother
The Adx method is way different, while the other two methods make the bull and bear lines somewhat uncorrelated, the adx method focus more on the overall market strength than individual buyer/seller strength.
The smoothing method use 3 different filters, SMA, EMA and LSMA, LSMA is more reactive than the two previous one while EMA is just more computer efficient.
It is possible to use price data of different time frames for the calculation of the indicator.
Stochastic method with 4 hour price close as source.
Conclusion
A classic indicator who can be derived into a lot of ways using a more adaptive architecture or recursion. Hope you find it a use :)
A big thanks to ernie76 for the request and the support/testing of the indicator
Feel free to pm me for any request.

Multi Poles Zero-Lag Exponential Moving AverageIntroduction
Based on the exponential averaging method with lag reduction, this filter allow for smoother results thanks to a multi-poles approach. Translated and modified from the Non-Linear Kalman Filter from Mladen Rakic 01/07/19 www.mql5.com
The Indicator
length control the amount of smoothing, the poles can be from 1 to 3, higher values create smoother results.
Difference With Classic Exponential Smoothing
A classic 1 depth recursion (Single smoothing) exponential moving average is defined as y = αx + (1 - α)y which can be derived into y = y + α(x - y )
2 depth recursion (Double smoothing) exponential moving average sum y with b in order to reduce the error with x , this method is calculated as follow :
y = αx + (1 - α)(y + b)
b = β(y - y ) + (1-β)b
The initial value for y is x while its 0 for b with α generally equal to 2/(length + 1)
The filter use a different approach, from the estimation of α/β/γ to the filter construction.The formula is similar to the one used in the double exponential smoothing method with a difference in y and b
y = αx + (1 - α)y
d = x - y
b = (1-β)b + d
output = y + b
instead of updating y with b the two components are directly added in a separated variable. Poles help the transition band of the frequency response to get closer to the cutoff point, the cutoff of an exponential moving average is defined as :
Cf = F/2π acos(1 - α*α/(2(1 - α)))
Also in order to minimize the overshoot of the filter a correction has been added to the output now being output = y + 1/poles * b
While this information is far being helpful to you it simply say that poles help you filter a great amount of noise thus removing irregularities of the filter.
Conclusion
The filter is interesting and while being similar to multi-depth recursion smoothing allow for more varied results thanks to its 3 poles.
Feel free to send suggestions :)
Thanks for reading
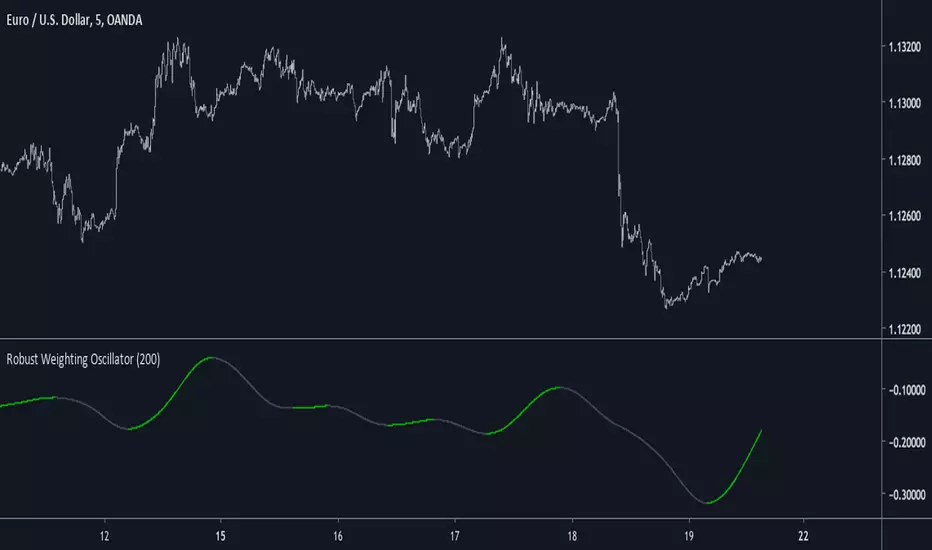
Robust Weighting OscillatorIntroduction
A simple oscillator using a modified lowess architecture, good in term of smoothness and reactivity.
Lowess Regression
Lowess or local regression is a non-parametric (can be used with data not fitting a normal distribution) smoothing method. This method fit a curve to the data using least squares.
In order to have a lowess regression one must use tricube kernel for the weightings w , the weightings are determined using a k-nearest-neighbor model.
lowess is then calculated like so :
Σ (wG(y-a-bx)^2)
Our indicator use G , a , b and remove the square as well as replacing x by y
Conclusion
The oscillator is simple and nothing revolutionary but its still interesting to have new indicators.
Lowess would be a great method to be made on pinescript, i have an estimate but its not that good. Some codes use a simple line equation in order to estimate a lowess smoother, i can describe it as ax + b where a is a smooth oscillator, b some kind of filter defined by lp + bp with lp a smooth low pass filter and bp a bandpass filter, x is a variable dependent of the smoothing span.