Multi Market Structure TrendOVERVIEW
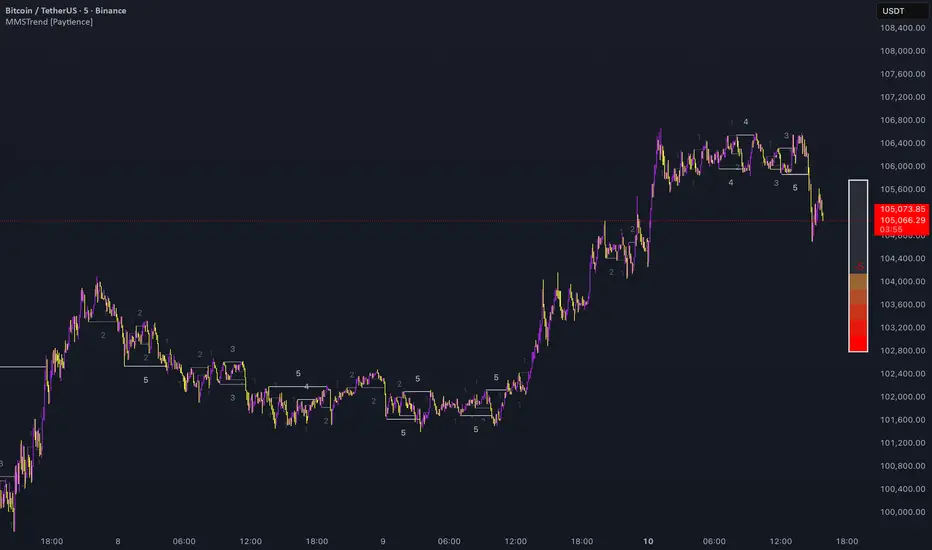
Multi Market Structure Trend is a multi-layered market structure analyzer that detects trend shifts across five independent pivot-based structures . Each pivot uses a different lookback length, offering a comprehensive view of structural momentum from short-term to long-term.
The indicator visually displays the net trend direction using colored candlesticks and a dynamic gauge that tracks how many of the 5 market structure layers are currently bullish or bearish.
⯁ STRUCTURE TRACKING SYSTEM
The indicator tracks five separate market structure layers in parallel using pivot-based breakouts. Each one can be individually enabled or disabled.
Each structure works as follows:
A bullish MSB (Market Structure Break) occurs when price breaks above the most recent swing high.
A bearish MSB occurs when price breaks below the most recent swing low.
Structure breaks are plotted as horizontal lines and labeled with the number (1 to 5) corresponding to their pivot layer.
⯁ CANDLE COLOR GRADIENT SYSTEM
The indicator calculates the average directional bias from all enabled market structures to determine the current trend score.
Each structure contributes a score of +1 for bullish and -1 for bearish.
The total score ranges from -5 (all bearish) to +5 (all bullish) .
Candlesticks are colored using a smooth gradient:
Bright Green: Strong bullish trend (e.g., +5).
Orange: Neutral mixed trend (e.g., 0).
Red: Strong bearish trend (e.g., -5).
⯁ TREND GAUGE PANEL
Displayed at the middle-right side of the chart, the gauge shows the current trend strength in real time.
The bar consists of up to 10 gradient cells (5 up, 5 down).
Each active market structure pushes the score in one direction.
The central cell displays a numeric trend score:
+5 = All 5 market structures bullish
0 = Mixed/neutral trend
-5 = All 5 market structures bearish
Colors of the gauge bars match the candle gradient system.
⯁ USAGE
This indicator is highly effective for traders who want to:
Monitor short- and long-term structure shifts simultaneously on a single chart.
Use structure alignment as a trend confirmation tool — for example, waiting for at least 2 out of 5 structures to align before entering a trade.
Visually filter noise from different time horizons using the gauge and candle gradient.
Track CHoCH (Change of Character) transitions clearly and across multiple scales.
⯁ CONCLUSION
Multi Market Structure Trend offers a unique and powerful way to assess trend direction using stacked market structure logic. With five independently calculated structure layers, colored candle feedback, and a real-time trend gauge, traders can better time entries, filter noise, and confirm multi-timeframe alignment — all within a single chart overlay.
Gradient
Market Spiralyst [Hapharmonic]Hello, traders and creators! 👋
Market Spiralyst: Let's change the way we look at analysis, shall we? I've got to admit, I scratched my head on this for weeks, Haha :). What you're seeing is an exploration of what's possible when code meets art on financial charts. I wanted to try blending art with trading, to do something new and break away from the same old boring perspectives. The goal was to create a visual experience that's not just analytical, but also relaxing and aesthetically pleasing.
This work is intended as a guide and a design example for all developers, born from the spirit of learning and a deep love for understanding the Pine Script™ language. I hope it inspires you as much as it challenged me!
🧐 Core Concept: How It Works
Spiralyst is built on two distinct but interconnected engines:
The Generative Art Engine: At its core, this indicator uses a wide range of mathematical formulas—from simple polygons to exotic curves like Torus Knots and Spirographs—to draw beautiful, intricate shapes directly onto your chart. This provides a unique and dynamic visual backdrop for your analysis.
The Market Pulse Engine: This is where analysis meets art. The engine takes real-time data from standard technical indicators (RSI and MACD in this version) and translates their states into a simple, powerful "Pulse Score." This score directly influences the appearance of the "Scatter Points" orbiting the main shape, turning the entire artwork into a living, breathing representation of market momentum.
🎨 Unleash Your Creativity! This Is Your Playground
We've included 25 preset shapes for you... but that's just the starting point !
The real magic happens when you start tweaking the settings yourself. A tiny adjustment can make a familiar shape come alive and transform in ways you never expected.
I'm genuinely excited to see what your imagination can conjure up! If you create a shape you're particularly proud of or one that looks completely unique, I would love to see it. Please feel free to share a screenshot in the comments below. I can't wait to see what you discover! :)
Here's the default shape to get you started:
The Dynamic Scatter Points: Reading the Pulse
This is where the magic happens! The small points scattered around the main shape are not just decorative; they are the visual representation of the Market Pulse Score.
The points have two forms:
A small asterisk (`*`): Represents a low or neutral market pulse.
A larger, more prominent circle (`o`): Represents a high, strong market pulse.
Here’s how to read them:
The indicator calculates the Pulse Strength as a percentage (from 0% to 100%) based on the total score from the active indicators (RSI and MACD). This percentage determines the ratio of circles to asterisks.
High Pulse Strength (e.g., 80-100%): Most of the scatter points will transform into large circles (`o`). This indicates that the underlying momentum is strong and It could be an uptrend. It's a visual cue that the market is gaining strength and might be worth paying closer attention to.
Low Pulse Strength (e.g., 0-20%): Most or all of the scatter points will remain as small asterisks (`*`). This suggests weak, neutral, or bearish momentum.
The key takeaway: The more circles you see, the stronger the bullish momentum is according to the active indicators. Watch the artwork "breathe" as the circles appear and disappear with the market's rhythm!
And don't worry about the shape you choose; the scatter points will intelligently adapt and always follow the outer boundary of whatever beautiful form you've selected.
How to Use
Getting started with Spiralyst is simple:
Choose Your Canvas: Start by going into the settings and picking a `Shape` and `Palette` from the "Shape Selection & Palette" group that you find visually appealing. This is your canvas.
Tune Your Engine: Go to the "Market Pulse Engine" settings. Here, you can enable or disable the RSI and MACD scoring engines. Want to see the pulse based only on RSI? Just uncheck the MACD box. You can also fine-tune the parameters for each indicator to match your trading style.
Read the Vibe: Observe the scatter points. Are they mostly small asterisks or are they transforming into large, vibrant circles? Use this visual feedback as a high-level gauge of market momentum.
Check the Dashboard: For a precise breakdown, look at the "Market Pulse Analysis" table on the top-right. It gives you the exact values, scores, and total strength percentage.
Explore & Experiment: Play with the different shapes and color palettes! The core analysis remains the same, but the visual experience can be completely different.
⚙️ Settings & Customization
Spiralyst is designed to be highly customizable.
Shape Selection & Palette: This is your main control panel. Choose from over 25 unique shapes, select a color palette, and adjust the line extension style ( `extend` ) or horizontal position ( `offsetXInput` ).
scatterLabelsInput: This setting controls the total number of points (both asterisks and circles) that orbit the main shape. Think of it as adjusting the density or visual granularity of the market pulse feedback.
The Market Pulse engine will always calculate its strength as a percentage (e.g., 75%). This percentage is then applied to the `scatterLabelsInput` number you've set to determine how many points transform into large circles.
Example: If the Pulse Strength is 75% and you set this to `100` , approximately 75 points will become circles. If you increase it to `200` , approximately 150 points will transform.
A higher number provides a more detailed, high-resolution view of the market pulse, while a lower number offers a cleaner, more minimalist look. Feel free to adjust this to your personal visual preference; the underlying analytical percentage remains the same.
Market Pulse Engine:
`⚙️ RSI Settings` & `⚙️ MACD Settings`: Each indicator has its own group.
Enable Scoring: Use the checkbox at the top of each group to include or exclude that indicator from the Pulse Score calculation. If you only want to use RSI, simply uncheck "Enable MACD Scoring."
Parameters: All standard parameters (Length, Source, Fast/Slow/Signal) are fully adjustable.
Individual Shape Parameters (01-25): Each of the 25+ shapes has its own dedicated group of settings, allowing you to fine-tune every aspect of its geometry, from the number of petals on a flower to the windings of a knot. Feel free to experiment!
For Developers & Pine Script™ Enthusiasts
If you are a developer and wish to add more indicators (e.g., Stochastic, CCI, ADX), you can easily do so by following the modular structure of the code. You would primarily need to:
Add a new `PulseIndicator` object for your new indicator in the `f_getMarketPulse()` function.
Add the logic for its scoring inside the `calculateScore()` method.
The `calculateTotals()` method and the dashboard table are designed to be dynamic and will automatically adapt to include your new indicator!
One of the core design philosophies behind Spiralyst is modularity and scalability . The Market Pulse engine was intentionally built using User-Defined Types (UDTs) and an array-based structure so that adding new indicators is incredibly simple and doesn't require rewriting the main logic.
If you want to add a new indicator to the scoring engine—let's use the Stochastic Oscillator as a detailed example—you only need to modify three small sections of the code. The rest of the script, including the adaptive dashboard, will update automatically.
Here’s your step-by-step guide:
#### Step 1: Add the User Inputs
First, you need to give users control over your new indicator. Find the `USER INTERFACE: INPUTS` section and add a new group for the Stochastic settings, right after the MACD group.
Create a new group name: `string GRP_STOCH = "⚙️ Stochastic Settings"`
Add the inputs: Create a boolean to enable/disable it, and then add the necessary parameters (`%K`, `%D`, `Smooth`). Use the `active` parameter to link them to the enable/disable checkbox.
// Add this code block right after the GRP_MACD and MACD inputs
string GRP_STOCH = "⚙️ Stochastic Settings"
bool stochEnabledInput = input.bool(true, "Enable Stochastic Scoring", group = GRP_STOCH)
int stochKInput = input.int(14, "%K Length", minval=1, group = GRP_STOCH, active = stochEnabledInput)
int stochDInput = input.int(3, "%D Smoothing", minval=1, group = GRP_STOCH, active = stochEnabledInput)
int stochSmoothInput = input.int(3, "Smooth", minval=1, group = GRP_STOCH, active = stochEnabledInput)
#### Step 2: Integrate into the Pulse Engine (The "Factory")
Next, go to the `f_getMarketPulse()` function. This function acts as a "factory" that builds and configures the entire market pulse object. You need to teach it how to build your new Stochastic indicator.
Update the function signature: Add the new `stochEnabledInput` boolean as a parameter.
Calculate the indicator: Add the `ta.stoch()` calculation.
Create a `PulseIndicator` object: Create a new object for the Stochastic, populating it with its name, parameters, calculated value, and whether it's enabled.
Add it to the array: Simply add your new `stochPulse` object to the `array.from()` list.
Here is the complete, updated `f_getMarketPulse()` function :
// Factory function to create and calculate the entire MarketPulse object.
f_getMarketPulse(bool rsiEnabled, bool macdEnabled, bool stochEnabled) =>
// 1. Calculate indicator values
float rsiVal = ta.rsi(rsiSourceInput, rsiLengthInput)
= ta.macd(close, macdFastInput, macdSlowInput, macdSignalInput)
float stochVal = ta.sma(ta.stoch(close, high, low, stochKInput), stochDInput) // We'll use the main line for scoring
// 2. Create individual PulseIndicator objects
PulseIndicator rsiPulse = PulseIndicator.new("RSI", str.tostring(rsiLengthInput), rsiVal, na, 0, rsiEnabled)
PulseIndicator macdPulse = PulseIndicator.new("MACD", str.format("{0},{1},{2}", macdFastInput, macdSlowInput, macdSignalInput), macdVal, signalVal, 0, macdEnabled)
PulseIndicator stochPulse = PulseIndicator.new("Stoch", str.format("{0},{1},{2}", stochKInput, stochDInput, stochSmoothInput), stochVal, na, 0, stochEnabled)
// 3. Calculate score for each
rsiPulse.calculateScore()
macdPulse.calculateScore()
stochPulse.calculateScore()
// 4. Add the new indicator to the array
array indicatorArray = array.from(rsiPulse, macdPulse, stochPulse)
MarketPulse pulse = MarketPulse.new(indicatorArray, 0, 0.0)
// 5. Calculate final totals
pulse.calculateTotals()
pulse
// Finally, update the function call in the main orchestration section:
MarketPulse marketPulse = f_getMarketPulse(rsiEnabledInput, macdEnabledInput, stochEnabledInput)
#### Step 3: Define the Scoring Logic
Now, you need to define how the Stochastic contributes to the score. Go to the `calculateScore()` method and add a new case to the `switch` statement for your indicator.
Here's a sample scoring logic for the Stochastic, which gives a strong bullish score in oversold conditions and a strong bearish score in overbought conditions.
Here is the complete, updated `calculateScore()` method :
// Method to calculate the score for this specific indicator.
method calculateScore(PulseIndicator this) =>
if not this.isEnabled
this.score := 0
else
this.score := switch this.name
"RSI" => this.value > 65 ? 2 : this.value > 50 ? 1 : this.value < 35 ? -2 : this.value < 50 ? -1 : 0
"MACD" => this.value > this.signalValue and this.value > 0 ? 2 : this.value > this.signalValue ? 1 : this.value < this.signalValue and this.value < 0 ? -2 : this.value < this.signalValue ? -1 : 0
"Stoch" => this.value > 80 ? -2 : this.value > 50 ? 1 : this.value < 20 ? 2 : this.value < 50 ? -1 : 0
=> 0
this
#### That's It!
You're done. You do not need to modify the dashboard table or the total score calculation.
Because the `MarketPulse` object holds its indicators in an array , the rest of the script is designed to be adaptive:
The `calculateTotals()` method automatically loops through every indicator in the array to sum the scores and calculate the final percentage.
The dashboard code loops through the `enabledIndicators` array to draw the table. Since your new Stochastic indicator is now part of that array, it will appear automatically when enabled!
---
Remember, this is your playground! I'm genuinely excited to see the unique shapes you discover. If you create something you're proud of, feel free to share it in the comments below.
Happy analyzing, and may your charts be both insightful and beautiful! 💛

Market Cap Landscape 3DHello, traders and creators! 👋
Market Cap Landscape 3D. This project is more than just a typical technical analysis tool; it's an exploration into what's possible when code meets artistry on the financial charts. It's a demonstration of how we can transcend flat, two-dimensional lines and step into a vibrant, three-dimensional world of data.
This project continues a journey that began with a previous 3D experiment, the T-Virus Sentiment, which you can explore here:
The Market Cap Landscape 3D builds on that foundation, visualizing market data—particularly crypto market caps—as a dynamic 3D mountain range. The entire landscape is procedurally generated and rendered in real-time using the powerful drawing capabilities of polyline.new() and line.new() , pushed to their creative limits.
This work is intended as a guide and a design example for all developers, born from the spirit of learning and a deep love for understanding the Pine Script™ language.
---
🧐 Core Concept: How It Works
The indicator synthesizes multiple layers of information into a single, cohesive 3D scene:
The Surface: The mountain range itself is a procedurally generated 3D mesh. Its peaks and valleys create a rich, textured landscape that serves as the canvas for our data.
Crypto Data Integration: The core feature is its ability to fetch market cap data for a list of cryptocurrencies you provide. It then sorts them in descending order and strategically places them onto the 3D surface.
The Summit: The highest point on the mountain is reserved for the asset with the #1 market cap in your list, visually represented by a flag and a custom emblem.
The Mountain Labels: The other assets are distributed across the mountainside, with their rank determining their general elevation. This creates an intuitive visual hierarchy.
The Leaderboard Pole: For clarity, a dedicated pole in the back-right corner provides a clean, ranked list of the symbols and their market caps, ensuring the data is always easy to read.
---
🧐 Example of adjusting the view
To evoke the feeling of flying over mountains
To evoke the feeling of looking at a mountain peak on a low plain
🧐 Example of predefined colors
---
🚀 How to Use
Getting started with the Market Cap Landscape 3D:
Add to Chart: Apply the "Market Cap Landscape 3D" indicator to your active chart.
Open Settings: Double-click anywhere on the 3D landscape or click the "Settings" icon next to the indicator's name.
Customize Your Crypto List: The most important setting is in the Crypto Data tab. In the "Symbols" text area, enter a comma-separated list of the crypto tickers you want to visualize (e.g., BTC,ETH,SOL,XRP ). The indicator supports up to 40 unique symbols.
> Important Note: This indicator exclusively uses TradingView's `CRYPTOCAP` data source. To find valid symbols, use the main symbol search bar on your chart. Type `CRYPTOCAP:` (including the colon) and you will see a list of available options. For example, typing `CRYPTOCAP:BTC` will confirm that `BTC` is a valid ticker for the indicator's settings. Using symbols that do not exist in the `CRYPTOCAP` index will result in a script error. or, to display other symbols, simply type CRYPTOCAP: (including the colon) and you will see a list of available options.
Adjust Your View: Use the settings in the Camera & Projection tab to rotate ( Yaw ), tilt ( Pitch ), and scale the landscape until you find a view you love.
Explore & Customize: Play with the color palettes, flag design, and other settings to make the landscape truly your own!
---
⚙️ Settings & Customization
This indicator is highly customizable. Here’s a breakdown of what each setting does:
#### 🪙 Crypto Data
Symbols: Enter the crypto tickers you want to track, separated by commas. The script automatically handles duplicates and case-insensitivity.
Show Market Cap on Mountain: When checked, it displays the full market cap value next to the symbol on the mountain. When unchecked, it shows a cleaner look with just the symbol and a colored circle background.
#### 📷 Camera & Projection
Yaw (°): Rotates the camera view horizontally (side to side).
Pitch (°): Tilts the camera view vertically (up and down).
Scale X, Y, Z: Stretches or compresses the landscape in width, depth, and height, respectively. Fine-tune these to get the perfect perspective.
#### 🏞️ Grid / Surface
Grid X/Y resolution: Controls the detail level of the 3D mesh. Higher values create a smoother surface but may use more resources.
Fill surface strips: Toggles the beautiful color gradient on the surface.
Show wireframe lines: Toggles the visibility of the grid lines.
Show nodes (markers): Toggles the small dots at each grid intersection point.
#### 🏔️ Peaks / Mountains
Fill peaks volume: Draws vertical lines on high peaks, giving them a sense of volume.
Fill peaks surface: Draws a cross-hatch pattern on the surface of high peaks.
Peak height threshold: Defines the minimum height for a peak to receive the fill effect.
Peak fill color/density: Customizes the appearance of the fill lines.
#### 🚩 Flags (3D)
Show Flag on Summit: A master switch to show or hide the flag and emblem entirely.
Flag height, width, etc.: Provides full control over the dimensions and orientation of the flag on the highest peak.
#### 🎨 Color Palette
Base Gradient Palette: Choose from 13 stunning, pre-designed color themes for the landscape, from the classic SUNSET_WAVE to vibrant themes like NEON_DREAM and OCEANIC .
#### 🛡️ Emblem / Badge Controls
This section gives you granular control over every element of the custom emblem on the flag. Tweak rotation, offsets, and scale to design your unique logo.
---
👨💻 Developer's Corner: Modifying the Core Logic
If you're a developer and wish to customize the indicator's core data source, this section is for you. The script is designed to be modular, making it easy to change what data is being ranked and visualized.
The heart of the data retrieval and ranking logic is within the f_getSortedCryptoData() function. Here’s how you can modify it:
1. Changing the Data Source (from Market Cap to something else):
The current logic uses request.security("CRYPTOCAP:" + syms.get(i), ...) to fetch market capitalization data. To change this, you need to modify this line.
Example: Ranking by RSI (14) on the Daily timeframe.
First, you'll need a function to calculate RSI. Add this function to the script:
f_getRSI(symbol, timeframe, length) =>
request.security(symbol, timeframe, ta.rsi(close, length))
Then, inside f_getSortedCryptoData() , find the `for` loop that populates the `caps` array and replace the `request.security` call:
// OLD LINE:
// caps.set(i, request.security("CRYPTOCAP:" + syms.get(i), timeframe.period, close))
// NEW LINE for RSI:
// Note: You'll need to decide how to format the symbol name (e.g., "BINANCE:" + syms.get(i) + "USDT")
caps.set(i, f_getRSI("BINANCE:" + syms.get(i) + "USDT", "D", 14))
2. Changing the Data Formatting:
The ranking values are formatted for display using the f_fmtCap() function, which currently formats large numbers into "M" (millions), "B" (billions), etc.
If you change the data source to something like RSI, you'll want to change the formatting. You can modify f_fmtCap() or create a new formatting function.
Example: Formatting for RSI.
// Modify f_fmtCap or create f_fmtRSI
f_fmtRSI(float v) =>
str.tostring(v, "#.##") // Simply format to two decimal places
Remember to update the calls to this function in the main drawing loop where the labels are created (e.g., str.format("{0}: {1}", crypto.symbol, f_fmtCap(crypto.cap)) ).
By modifying these key functions ( f_getSortedCryptoData and f_fmtCap ), you can adapt the Market Cap Landscape 3D to visualize and rank almost any dataset you can imagine, from technical indicators to fundamental data.
---
We hope you enjoy using the Market Cap Landscape 3D as much as we enjoyed creating it. Happy charting! ✨

Icy-Hot Visual Indicator [SciQua]🧊 Icy-Hot Visual Indicator
This indicator colors your price bars and/or chart background based on a normalized & smoothed transform of any price-based input (default: close). It gives you a quick “temperature map” of market momentum or volatility—cool blues for low readings, hot reds for high readings—without cluttering your chart.
🔍 Key Features
1. Dual Visual Layers
Candle Gradient: Applies a smooth, multi-color gradient to candle bodies and wicks based on normalized, smoothed input data
Background Gradient: Adds a semi-transparent gradient behind the candles to highlight broader trend zones or volatility regimes
2. Advanced Customization
Normalization Types: bounded, unbounded, z-score, MAD, percentile, sigmoid, tanh, rank, robust, and more
Smoothing Methods: EMA, SMA, WMA, RMA, HMA, TEMA, VWMA, Gaussian, LinReg, ExpReg, and others (12+ options)
3. Gradient Control: Choose 2–7 color stops, reverse direction, adjust display length
Flexible Source Inputs
Use any built-in price series (close, hl2, volume, etc.)
Feed outputs from external indicators (RSI, custom oscillators, moving averages) into either layer
❓How It Works
Inputs are normalized (z-score, bounded, etc.) then smoothed (EMA, LinReg, etc.) in the order you choose. The result is clamped to 0–1 and passed through a multi-stop gradient engine for precise color mapping.
✨ What Makes It Original
While many indicators apply colors or smoothing, this script combines multi-stage normalization, adaptive smoothing, and a modular gradient rendering engine in a highly customizable dual-layer system. It’s built using proprietary functions from the SciQua suite that are not available in public libraries and allow for advanced visual encoding without relying on alerts, signals, or extra panes.
This makes it original in both design and execution—offering a visual-first approach with unique depth, clarity, and flexibility.
🔐 Why This Script Is Closed-Source
While the underlying functions are published in the open-source SciQua library, this indicator’s specific implementation, configuration architecture, and visual behavior are proprietary. It combines multiple library utilities into a dual-layer adaptive system that handles advanced gradient rendering, multi-stage normalization, and smoothing pipelines in a unique way.
The source is closed to protect the design logic, interface abstraction, and fine-tuned behaviors that make this indicator commercially valuable. The building blocks are open to the Pine community, but this assembled product is not meant for replication or redistribution.
How to Use It
1. Highlight Trend Strength
Source: RSI percentile
Setup: 200-bar look-back, mild smoothing
Result: Warm tones when momentum is peaking; cool when it’s fading. Use as a quick filter for entries in the direction of the trend.
2. Visualize Volatility Regimes
Source: ATR or True Range
Setup: Bounded normalization with tighter smoothing bar color off, bg color on.
Result: Background bands that shade when volatility spikes. Helps you avoid low-volatility breakouts or throttle position sizing in choppy markets.
3. Combine with Other Indicators
Source: Output of your custom indicator (e.g., a Keltner Band width)
Setup: Match normalization period to your strategy’s timeframe
Result: Bars colored by your own logic—no extra panes, just enhanced candles.
4. Background Only Heatmap
Turn off bar coloring and dial in semi-transparent background shades—keeps candles crisp while still giving you a context heat-map behind price.
Color█ OVERVIEW
This library is a Pine Script® programming tool for advanced color processing. It provides a comprehensive set of functions for specifying and analyzing colors in various color spaces, mixing and manipulating colors, calculating custom gradients and schemes, detecting contrast, and converting colors to or from hexadecimal strings.
█ CONCEPTS
Color
Color refers to how we interpret light of different wavelengths in the visible spectrum . The colors we see from an object represent the light wavelengths that it reflects, emits, or transmits toward our eyes. Some colors, such as blue and red, correspond directly to parts of the spectrum. Others, such as magenta, arise from a combination of wavelengths to which our minds assign a single color.
The human interpretation of color lends itself to many uses in our world. In the context of financial data analysis, the effective use of color helps transform raw data into insights that users can understand at a glance. For example, colors can categorize series, signal market conditions and sessions, and emphasize patterns or relationships in data.
Color models and spaces
A color model is a general mathematical framework that describes colors using sets of numbers. A color space is an implementation of a specific color model that defines an exact range (gamut) of reproducible colors based on a set of primary colors , a reference white point , and sometimes additional parameters such as viewing conditions.
There are numerous different color spaces — each describing the characteristics of color in unique ways. Different spaces carry different advantages, depending on the application. Below, we provide a brief overview of the concepts underlying the color spaces supported by this library.
RGB
RGB is one of the most well-known color models. It represents color as an additive mixture of three primary colors — red, green, and blue lights — with various intensities. Each cone cell in the human eye responds more strongly to one of the three primaries, and the average person interprets the combination of these lights as a distinct color (e.g., pure red + pure green = yellow).
The sRGB color space is the most common RGB implementation. Developed by HP and Microsoft in the 1990s, sRGB provided a standardized baseline for representing color across CRT monitors of the era, which produced brightness levels that did not increase linearly with the input signal. To match displays and optimize brightness encoding for human sensitivity, sRGB applied a nonlinear transformation to linear RGB signals, often referred to as gamma correction . The result produced more visually pleasing outputs while maintaining a simple encoding. As such, sRGB quickly became a standard for digital color representation across devices and the web. To this day, it remains the default color space for most web-based content.
TradingView charts and Pine Script `color.*` built-ins process color data in sRGB. The red, green, and blue channels range from 0 to 255, where 0 represents no intensity, and 255 represents maximum intensity. Each combination of red, green, and blue values represents a distinct color, resulting in a total of 16,777,216 displayable colors.
CIE XYZ and xyY
The XYZ color space, developed by the International Commission on Illumination (CIE) in 1931, aims to describe all color sensations that a typical human can perceive. It is a cornerstone of color science, forming the basis for many color spaces used today. XYZ, and the derived xyY space, provide a universal representation of color that is not tethered to a particular display. Many widely used color spaces, including sRGB, are defined relative to XYZ or derived from it.
The CIE built the color space based on a series of experiments in which people matched colors they perceived from mixtures of lights. From these experiments, the CIE developed color-matching functions to calculate three components — X, Y, and Z — which together aim to describe a standard observer's response to visible light. X represents a weighted response to light across the color spectrum, with the highest contribution from long wavelengths (e.g., red). Y represents a weighted response to medium wavelengths (e.g., green), and it corresponds to a color's relative luminance (i.e., brightness). Z represents a weighted response to short wavelengths (e.g., blue).
From the XYZ space, the CIE developed the xyY chromaticity space, which separates a color's chromaticity (hue and colorfulness) from luminance. The CIE used this space to define the CIE 1931 chromaticity diagram , which represents the full range of visible colors at a given luminance. In color science and lighting design, xyY is a common means for specifying colors and visualizing the supported ranges of other color spaces.
CIELAB and Oklab
The CIELAB (L*a*b*) color space, derived from XYZ by the CIE in 1976, expresses colors based on opponent process theory. The L* component represents perceived lightness, and the a* and b* components represent the balance between opposing unique colors. The a* value specifies the balance between green and red , and the b* value specifies the balance between blue and yellow .
The primary intention of CIELAB was to provide a perceptually uniform color space, where fixed-size steps through the space correspond to uniform perceived changes in color. Although relatively uniform, the color space has been found to exhibit some non-uniformities, particularly in the blue part of the color spectrum. Regardless, modern applications often use CIELAB to estimate perceived color differences and calculate smooth color gradients.
In 2020, a new LAB-oriented color space, Oklab , was introduced by Björn Ottosson as an attempt to rectify the non-uniformities of other perceptual color spaces. Similar to CIELAB, the L value in Oklab represents perceived lightness, and the a and b values represent the balance between opposing unique colors. Oklab has gained widespread adoption as a perceptual space for color processing, with support in the latest CSS Color specifications and many software applications.
Cylindrical models
A cylindrical-coordinate model transforms an underlying color model, such as RGB or LAB, into an alternative expression of color information that is often more intuitive for the average person to use and understand.
Instead of a mixture of primary colors or opponent pairs, these models represent color as a hue angle on a color wheel , with additional parameters that describe other qualities such as lightness and colorfulness (a general term for concepts like chroma and saturation). In cylindrical-coordinate spaces, users can select a color and modify its lightness or other qualities without altering the hue.
The three most common RGB-based models are HSL (Hue, Saturation, Lightness), HSV (Hue, Saturation, Value), and HWB (Hue, Whiteness, Blackness). All three define hue angles in the same way, but they define colorfulness and lightness differently. Although they are not perceptually uniform, HSL and HSV are commonplace in color pickers and gradients.
For CIELAB and Oklab, the cylindrical-coordinate versions are CIELCh and Oklch , which express color in terms of perceived lightness, chroma, and hue. They offer perceptually uniform alternatives to RGB-based models. These spaces create unique color wheels, and they have more strict definitions of lightness and colorfulness. Oklch is particularly well-suited for generating smooth, perceptual color gradients.
Alpha and transparency
Many color encoding schemes include an alpha channel, representing opacity . Alpha does not help define a color in a color space; it determines how a color interacts with other colors in the display. Opaque colors appear with full intensity on the screen, whereas translucent (semi-opaque) colors blend into the background. Colors with zero opacity are invisible.
In Pine Script, there are two ways to specify a color's alpha:
• Using the `transp` parameter of the built-in `color.*()` functions. The specified value represents transparency (the opposite of opacity), which the functions translate into an alpha value.
• Using eight-digit hexadecimal color codes. The last two digits in the code represent alpha directly.
A process called alpha compositing simulates translucent colors in a display. It creates a single displayed color by mixing the RGB channels of two colors (foreground and background) based on alpha values, giving the illusion of a semi-opaque color placed over another color. For example, a red color with 80% transparency on a black background produces a dark shade of red.
Hexadecimal color codes
A hexadecimal color code (hex code) is a compact representation of an RGB color. It encodes a color's red, green, and blue values into a sequence of hexadecimal ( base-16 ) digits. The digits are numerals ranging from `0` to `9` or letters from `a` (for 10) to `f` (for 15). Each set of two digits represents an RGB channel ranging from `00` (for 0) to `ff` (for 255).
Pine scripts can natively define colors using hex codes in the format `#rrggbbaa`. The first set of two digits represents red, the second represents green, and the third represents blue. The fourth set represents alpha . If unspecified, the value is `ff` (fully opaque). For example, `#ff8b00` and `#ff8b00ff` represent an opaque orange color. The code `#ff8b0033` represents the same color with 80% transparency.
Gradients
A color gradient maps colors to numbers over a given range. Most color gradients represent a continuous path in a specific color space, where each number corresponds to a mix between a starting color and a stopping color. In Pine, coders often use gradients to visualize value intensities in plots and heatmaps, or to add visual depth to fills.
The behavior of a color gradient depends on the mixing method and the chosen color space. Gradients in sRGB usually mix along a straight line between the red, green, and blue coordinates of two colors. In cylindrical spaces such as HSL, a gradient often rotates the hue angle through the color wheel, resulting in more pronounced color transitions.
Color schemes
A color scheme refers to a set of colors for use in aesthetic or functional design. A color scheme usually consists of just a few distinct colors. However, depending on the purpose, a scheme can include many colors.
A user might choose palettes for a color scheme arbitrarily, or generate them algorithmically. There are many techniques for calculating color schemes. A few simple, practical methods are:
• Sampling a set of distinct colors from a color gradient.
• Generating monochromatic variants of a color (i.e., tints, tones, or shades with matching hues).
• Computing color harmonies — such as complements, analogous colors, triads, and tetrads — from a base color.
This library includes functions for all three of these techniques. See below for details.
█ CALCULATIONS AND USE
Hex string conversion
The `getHexString()` function returns a string containing the eight-digit hexadecimal code corresponding to a "color" value or set of sRGB and transparency values. For example, `getHexString(255, 0, 0)` returns the string `"#ff0000ff"`, and `getHexString(color.new(color.red, 80))` returns `"#f2364533"`.
The `hexStringToColor()` function returns the "color" value represented by a string containing a six- or eight-digit hex code. The `hexStringToRGB()` function returns a tuple containing the sRGB and transparency values. For example, `hexStringToColor("#f23645")` returns the same value as color.red .
Programmers can use these functions to parse colors from "string" inputs, perform string-based color calculations, and inspect color data in text outputs such as Pine Logs and tables.
Color space conversion
All other `get*()` functions convert a "color" value or set of sRGB channels into coordinates in a specific color space, with transparency information included. For example, the tuple returned by `getHSL()` includes the color's hue, saturation, lightness, and transparency values.
To convert data from a color space back to colors or sRGB and transparency values, use the corresponding `*toColor()` or `*toRGB()` functions for that space (e.g., `hslToColor()` and `hslToRGB()`).
Programmers can use these conversion functions to process inputs that define colors in different ways, perform advanced color manipulation, design custom gradients, and more.
The color spaces this library supports are:
• sRGB
• Linear RGB (RGB without gamma correction)
• HSL, HSV, and HWB
• CIE XYZ and xyY
• CIELAB and CIELCh
• Oklab and Oklch
Contrast-based calculations
Contrast refers to the difference in luminance or color that makes one color visible against another. This library features two functions for calculating luminance-based contrast and detecting themes.
The `contrastRatio()` function calculates the contrast between two "color" values based on their relative luminance (the Y value from CIE XYZ) using the formula from version 2 of the Web Content Accessibility Guidelines (WCAG) . This function is useful for identifying colors that provide a sufficient brightness difference for legibility.
The `isLightTheme()` function determines whether a specified background color represents a light theme based on its contrast with black and white. Programmers can use this function to define conditional logic that responds differently to light and dark themes.
Color manipulation and harmonies
The `negative()` function calculates the negative (i.e., inverse) of a color by reversing the color's coordinates in either the sRGB or linear RGB color space. This function is useful for calculating high-contrast colors.
The `grayscale()` function calculates a grayscale form of a specified color with the same relative luminance.
The functions `complement()`, `splitComplements()`, `analogousColors()`, `triadicColors()`, `tetradicColors()`, `pentadicColors()`, and `hexadicColors()` calculate color harmonies from a specified source color within a given color space (HSL, CIELCh, or Oklch). The returned harmonious colors represent specific hue rotations around a color wheel formed by the chosen space, with the same defined lightness, saturation or chroma, and transparency.
Color mixing and gradient creation
The `add()` function simulates combining lights of two different colors by additively mixing their linear red, green, and blue components, ignoring transparency by default. Users can calculate a transparency-weighted mixture by setting the `transpWeight` argument to `true`.
The `overlay()` function estimates the color displayed on a TradingView chart when a specific foreground color is over a background color. This function aids in simulating stacked colors and analyzing the effects of transparency.
The `fromGradient()` and `fromMultiStepGradient()` functions calculate colors from gradients in any of the supported color spaces, providing flexible alternatives to the RGB-based color.from_gradient() function. The `fromGradient()` function calculates a color from a single gradient. The `fromMultiStepGradient()` function calculates a color from a piecewise gradient with multiple defined steps. Gradients are useful for heatmaps and for coloring plots or drawings based on value intensities.
Scheme creation
Three functions in this library calculate palettes for custom color schemes. Scripts can use these functions to create responsive color schemes that adjust to calculated values and user inputs.
The `gradientPalette()` function creates an array of colors by sampling a specified number of colors along a gradient from a base color to a target color, in fixed-size steps.
The `monoPalette()` function creates an array containing monochromatic variants (tints, tones, or shades) of a specified base color. Whether the function mixes the color toward white (for tints), a form of gray (for tones), or black (for shades) depends on the `grayLuminance` value. If unspecified, the function automatically chooses the mix behavior with the highest contrast.
The `harmonyPalette()` function creates a matrix of colors. The first column contains the base color and specified harmonies, e.g., triadic colors. The columns that follow contain tints, tones, or shades of the harmonic colors for additional color choices, similar to `monoPalette()`.
█ EXAMPLE CODE
The example code at the end of the script generates and visualizes color schemes by processing user inputs. The code builds the scheme's palette based on the "Base color" input and the additional inputs in the "Settings/Inputs" tab:
• "Palette type" specifies whether the palette uses a custom gradient, monochromatic base color variants, or color harmonies with monochromatic variants.
• "Target color" sets the top color for the "Gradient" palette type.
• The "Gray luminance" inputs determine variation behavior for "Monochromatic" and "Harmony" palette types. If "Auto" is selected, the palette mixes the base color toward white or black based on its brightness. Otherwise, it mixes the color toward the grayscale color with the specified relative luminance (from 0 to 1).
• "Harmony type" specifies the color harmony used in the palette. Each row in the palette corresponds to one of the harmonious colors, starting with the base color.
The code creates a table on the first bar to display the collection of calculated colors. Each cell in the table shows the color's `getHexString()` value in a tooltip for simple inspection.
Look first. Then leap.
█ EXPORTED FUNCTIONS
Below is a complete list of the functions and overloads exported by this library.
getRGB(source)
Retrieves the sRGB red, green, blue, and transparency components of a "color" value.
getHexString(r, g, b, t)
(Overload 1 of 2) Converts a set of sRGB channel values to a string representing the corresponding color's hexadecimal form.
getHexString(source)
(Overload 2 of 2) Converts a "color" value to a string representing the sRGB color's hexadecimal form.
hexStringToRGB(source)
Converts a string representing an sRGB color's hexadecimal form to a set of decimal channel values.
hexStringToColor(source)
Converts a string representing an sRGB color's hexadecimal form to a "color" value.
getLRGB(r, g, b, t)
(Overload 1 of 2) Converts a set of sRGB channel values to a set of linear RGB values with specified transparency information.
getLRGB(source)
(Overload 2 of 2) Retrieves linear RGB channel values and transparency information from a "color" value.
lrgbToRGB(lr, lg, lb, t)
Converts a set of linear RGB channel values to a set of sRGB values with specified transparency information.
lrgbToColor(lr, lg, lb, t)
Converts a set of linear RGB channel values and transparency information to a "color" value.
getHSL(r, g, b, t)
(Overload 1 of 2) Converts a set of sRGB channels to a set of HSL values with specified transparency information.
getHSL(source)
(Overload 2 of 2) Retrieves HSL channel values and transparency information from a "color" value.
hslToRGB(h, s, l, t)
Converts a set of HSL channel values to a set of sRGB values with specified transparency information.
hslToColor(h, s, l, t)
Converts a set of HSL channel values and transparency information to a "color" value.
getHSV(r, g, b, t)
(Overload 1 of 2) Converts a set of sRGB channels to a set of HSV values with specified transparency information.
getHSV(source)
(Overload 2 of 2) Retrieves HSV channel values and transparency information from a "color" value.
hsvToRGB(h, s, v, t)
Converts a set of HSV channel values to a set of sRGB values with specified transparency information.
hsvToColor(h, s, v, t)
Converts a set of HSV channel values and transparency information to a "color" value.
getHWB(r, g, b, t)
(Overload 1 of 2) Converts a set of sRGB channels to a set of HWB values with specified transparency information.
getHWB(source)
(Overload 2 of 2) Retrieves HWB channel values and transparency information from a "color" value.
hwbToRGB(h, w, b, t)
Converts a set of HWB channel values to a set of sRGB values with specified transparency information.
hwbToColor(h, w, b, t)
Converts a set of HWB channel values and transparency information to a "color" value.
getXYZ(r, g, b, t)
(Overload 1 of 2) Converts a set of sRGB channels to a set of XYZ values with specified transparency information.
getXYZ(source)
(Overload 2 of 2) Retrieves XYZ channel values and transparency information from a "color" value.
xyzToRGB(x, y, z, t)
Converts a set of XYZ channel values to a set of sRGB values with specified transparency information
xyzToColor(x, y, z, t)
Converts a set of XYZ channel values and transparency information to a "color" value.
getXYY(r, g, b, t)
(Overload 1 of 2) Converts a set of sRGB channels to a set of xyY values with specified transparency information.
getXYY(source)
(Overload 2 of 2) Retrieves xyY channel values and transparency information from a "color" value.
xyyToRGB(xc, yc, y, t)
Converts a set of xyY channel values to a set of sRGB values with specified transparency information.
xyyToColor(xc, yc, y, t)
Converts a set of xyY channel values and transparency information to a "color" value.
getLAB(r, g, b, t)
(Overload 1 of 2) Converts a set of sRGB channels to a set of CIELAB values with specified transparency information.
getLAB(source)
(Overload 2 of 2) Retrieves CIELAB channel values and transparency information from a "color" value.
labToRGB(l, a, b, t)
Converts a set of CIELAB channel values to a set of sRGB values with specified transparency information.
labToColor(l, a, b, t)
Converts a set of CIELAB channel values and transparency information to a "color" value.
getOKLAB(r, g, b, t)
(Overload 1 of 2) Converts a set of sRGB channels to a set of Oklab values with specified transparency information.
getOKLAB(source)
(Overload 2 of 2) Retrieves Oklab channel values and transparency information from a "color" value.
oklabToRGB(l, a, b, t)
Converts a set of Oklab channel values to a set of sRGB values with specified transparency information.
oklabToColor(l, a, b, t)
Converts a set of Oklab channel values and transparency information to a "color" value.
getLCH(r, g, b, t)
(Overload 1 of 2) Converts a set of sRGB channels to a set of CIELCh values with specified transparency information.
getLCH(source)
(Overload 2 of 2) Retrieves CIELCh channel values and transparency information from a "color" value.
lchToRGB(l, c, h, t)
Converts a set of CIELCh channel values to a set of sRGB values with specified transparency information.
lchToColor(l, c, h, t)
Converts a set of CIELCh channel values and transparency information to a "color" value.
getOKLCH(r, g, b, t)
(Overload 1 of 2) Converts a set of sRGB channels to a set of Oklch values with specified transparency information.
getOKLCH(source)
(Overload 2 of 2) Retrieves Oklch channel values and transparency information from a "color" value.
oklchToRGB(l, c, h, t)
Converts a set of Oklch channel values to a set of sRGB values with specified transparency information.
oklchToColor(l, c, h, t)
Converts a set of Oklch channel values and transparency information to a "color" value.
contrastRatio(value1, value2)
Calculates the contrast ratio between two colors values based on the formula from version 2 of the Web Content Accessibility Guidelines (WCAG).
isLightTheme(source)
Detects whether a background color represents a light theme or dark theme, based on the amount of contrast between the color and the white and black points.
grayscale(source)
Calculates the grayscale version of a color with the same relative luminance (i.e., brightness).
negative(source, colorSpace)
Calculates the negative (i.e., inverted) form of a specified color.
complement(source, colorSpace)
Calculates the complementary color for a `source` color using a cylindrical color space.
analogousColors(source, colorSpace)
Calculates the analogous colors for a `source` color using a cylindrical color space.
splitComplements(source, colorSpace)
Calculates the split-complementary colors for a `source` color using a cylindrical color space.
triadicColors(source, colorSpace)
Calculates the two triadic colors for a `source` color using a cylindrical color space.
tetradicColors(source, colorSpace, square)
Calculates the three square or rectangular tetradic colors for a `source` color using a cylindrical color space.
pentadicColors(source, colorSpace)
Calculates the four pentadic colors for a `source` color using a cylindrical color space.
hexadicColors(source, colorSpace)
Calculates the five hexadic colors for a `source` color using a cylindrical color space.
add(value1, value2, transpWeight)
Additively mixes two "color" values, with optional transparency weighting.
overlay(fg, bg)
Estimates the resulting color that appears on the chart when placing one color over another.
fromGradient(value, bottomValue, topValue, bottomColor, topColor, colorSpace)
Calculates the gradient color that corresponds to a specific value based on a defined value range and color space.
fromMultiStepGradient(value, steps, colors, colorSpace)
Calculates a multi-step gradient color that corresponds to a specific value based on an array of step points, an array of corresponding colors, and a color space.
gradientPalette(baseColor, stopColor, steps, strength, model)
Generates a palette from a gradient between two base colors.
monoPalette(baseColor, grayLuminance, variations, strength, colorSpace)
Generates a monochromatic palette from a specified base color.
harmonyPalette(baseColor, harmonyType, grayLuminance, variations, strength, colorSpace)
Generates a palette consisting of harmonious base colors and their monochromatic variants.
Quick scan for drift🙏🏻
ML based algorading is all about detecting any kind of non-randomness & exploiting it, kinda speculative stuff, not my way, but still...
Drift is one of the patterns that can be exploited, because pure random walks & noise aint got no drift.
This is an efficient method to quickly scan tons of timeseries on the go & detect the ones with drift by simply checking wherther drift < -0.5 or drift > 0.5. The code can be further optimized both in general and for specific needs, but I left it like dat for clarity so you can understand how it works in a minute not in an hour
^^ proving 0.5 and -0.5 are natural limits with no need to optimize anything, we simply put the metric on random noise and see it sits in between -0.5 and 0.5
You can simply take this one and never check anything again if you require numerous live scans on the go. The metric is purely geometrical, no connection to stats, TSA, DSA or whatever. I've tested numerous formulas involving other scaling techniques, drift estimates etc (even made a recursive algo that had a great potential to be written about in a paper, but not this time I gues lol), this one has the highest info gain aka info content.
The timeseries filtered by this lil metric can be further analyzed & modelled with more sophisticated tools.
Live Long and Prosper
P.S.: there's no such thing as polynomial trend/drift, it's alwasy linear, these curves you see are just really long cycles
P.S.: does cheer still work on TV? @admin
Multiple Non-Linear Regression [ChartPrime]This Pine Script indicator is designed to perform multiple non-linear regression analysis using four independent variables: close, open, high, and low prices. Here's a breakdown of its components and functionalities:
Inputs:
Users can adjust several parameters:
Normalization Data Length: Length of data used for normalization.
Learning Rate: Rate at which the algorithm learns from errors.
Smooth?: Option to smooth the output.
Smooth Length: Length of smoothing if enabled.
Define start coefficients: Initial coefficients for the regression equation.
Data Normalization:
The script normalizes input data to a range between 0 and 1 using the highest and lowest values within a specified length.
Non-linear Regression:
It calculates the regression equation using the input coefficients and normalized data. The equation used is a weighted sum of the independent variables, with coefficients adjusted iteratively using gradient descent to minimize errors.
Error Calculation:
The script computes the error between the actual and predicted values.
Gradient Descent: The coefficients are updated iteratively using gradient descent to minimize the error.
// Compute the predicted values using the non-linear regression function
predictedValues = nonLinearRegression(x_1, x_2, x_3, x_4, b1, b2, b3, b4)
// Compute the error
error = errorModule(initial_val, predictedValues)
// Update the coefficients using gradient descent
b1 := b1 - (learningRate * (error * x_1))
b2 := b2 - (learningRate * (error * x_2))
b3 := b3 - (learningRate * (error * x_3))
b4 := b4 - (learningRate * (error * x_4))
Visualization:
Plotting of normalized input data (close, open, high, low).
The indicator provides visualization of normalized data values (close, open, high, low) in the form of circular markers on the chart, allowing users to easily observe the relative positions of these values in relation to each other and the regression line.
Plotting of the regression line.
Color gradient on the regression line based on its value and bar colors.
Display of normalized input data and predicted value in a table.
Signals for crossovers with a midline (0.5).
Interpretation:
Users can interpret the regression line and its crossovers with the midline (0.5) as signals for potential buy or sell opportunities.
This indicator helps users analyze the relationship between multiple variables and make trading decisions based on the regression analysis. Adjusting the coefficients and parameters can fine-tune the model's performance according to specific market conditions.

Gradient Value Overlay
This script helps with identifying certain conditions without cluttering too much of the candles.
Some use cases:
It helps identify rsi low and high values.
Directional price movement becoming difficult.
low and high volume.
it uses a percent rank to distinguish low and high values.
It then uses a gradient to match the percentile rank to heatmap type colors.
i.e. dark blue for lowest volume, white for highest volume.
Current options are:
max bars to use.
approximate color - This value will attempt to give an approximation of what the color might be for the candle close.
e.g. If you're on the 1-hour chart, and only 30 minutes have past, it will multiple the current volume by 1.5. As time passes, if no volume comes in eventually, it will multiply current volume by 1.
This approximate value is only set to work with volume-based options.
option - select the type of value you'd like to see the gradient for.
timeframe - get values from a different chart timeframe.
on/off - turns the gradient on or off.
Gradient type - color wheel or heatmap. Currently these are the only two gardient options.
color wheel's colors for low to high values:
color wheel's current colors:
dark blue
purple
pink
red
orange
yellow
green
teal
white
heatmap's current colors from low values to high values:
dark blue
purple
pink
red
orange
yellow
white
reverse gradient - will reverse the colors so dark blue will be the high value and white will be the low value. Some charts based on previous data; you might need to switch the gradient colors.
moving average length while inside timeframe - an exponential moving average is applied to the values. At 1, there is no moving average applied.
Use case for this is to smooth out the gradient.
An example use case - if your currently on the 1-hour chart, you can set the timeframe to 1 minute and then the moving average length inside timeframe to 60. You will then be seeing the color sixty 1-minute bars.
current timeframe moving average length - an exponential moving average applied to current gradient (helps with smoothing gradient).
Smooth, further smooths values.
There is no set rule for what moving average lengths to use. Adjust timeframe, and moving average lengths to get an insight.
Keltner Channels Bands (RMA)Keltner Channel Bands
These normally consist of:
Keltner Channel Upper Band = EMA + Multiplier ∗ ATR
Keltner Channel Lower Band = EMA − Multiplier ∗ ATR
However instead of using ATR we are using RMA
This gives us a much smoother take of the KCB
We are also using 2 sets of bands built on 1 Moving average, this is a common set up for mean reversion strategies.
This can often be paired with RSI for lower timeframe divergences
Divergence
This is using the RSI to calculate when price sets new lows/highs whilst the RSI movement is in the opposite direction.
The way this is calculated is slightly different to traditional divergence scripts. instead of looking for pivot highs/lows in the RSI we are logging the RSI value when price makes it pivot highs/lows.
Gradient Bands
The Gradient Colouring on the bands is measuring how long price has been either side of the MA.
As Keltner bands are commonly used as a mean reversion strategy, I thought it would be useful to see how long price has been trending in a certain direction, the stronger the colours get,
the longer price has been trending that direction which could suggest we are looking for a retrace soon.
Alerts
Alerts included let you choose whether you want to receive an alert for the inside, outside or both band touches.
To set up these alerts, simply toggle them on in the settings, then click on the 3 dots next to the indicators name, from there you click 'Add Alert'.
From there you can customise the alert settings but make sure to leave the 2 top boxes which control the alert conditions. They will be default selected onto your correct settings, the rest you may want to change.
Once you create the alert, it will then trigger as soon as price touches your chosen inside/outside band.
Suggestions
Please feel free to offer any suggestions which you think could improve the script
Disclaimer
The default settings/parameters were shared by Jimtalbott, feel free to play about with the and use this code to make your own strategies.

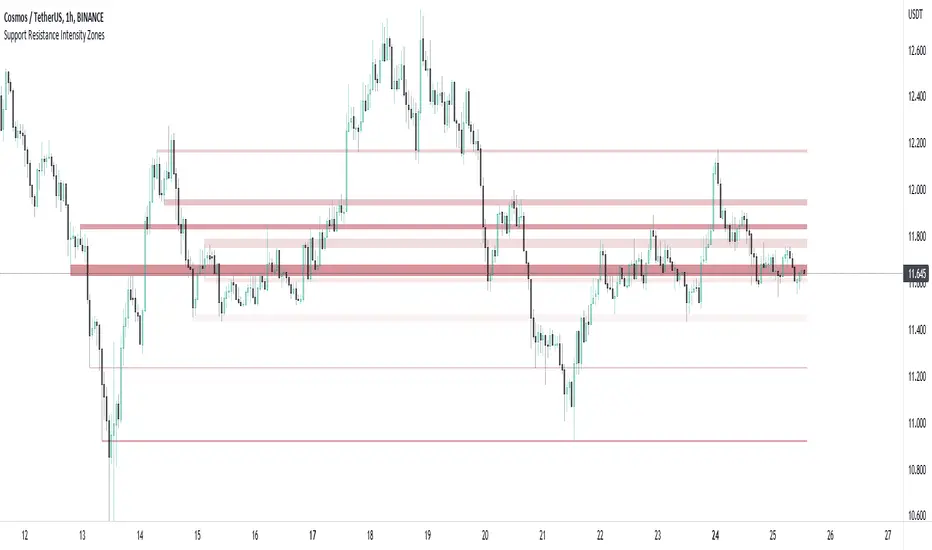
Support and Resistance Intensity ZonesSupport and resistance are often drawn using lines. This is too simple and doesn't give a clear idea of the market sentiment at these particular levels. What is strong support and resistance? What is weak support and resistance. How can either be defined by a single price point?
Using a simple, clean and configurable solution, this indicator not only shows these support and resistance levels as zones, it also gives them a colour gradient based on their intensity.
It does this by letting you choose the pivot highs and lows within a chosen range back. Then you choose one of two options to display how these multiple pivots at the same levels look. You can either group these pivots together into 'zones', where grouped pivots are all separated by a chosen price percentage, choosing how many zones to display, the most grouped pivots being the most intense colour.
Alternatively you display the pivots by 'gradient', where the closer the pivots are together in price the more intense the colour. As pivots diverge apart, the colour weakens.
Both of these options have to be seen to realise how much more there is to support and resistance than a single line.
Stochastic of Two-Pole SuperSmoother [Loxx]Stochastic of Two-Pole SuperSmoother is a Stochastic Indicator that takes as input Two-Pole SuperSmoother of price. Includes gradient coloring and Discontinued Signal Lines signals with alerts.
What is Ehlers ; Two-Pole Super Smoother?
From "Cycle Analytics for Traders Advanced Technical Trading Concepts" by John F. Ehlers
A SuperSmoother filter is used anytime a moving average of any type would otherwise be used, with the result that the SuperSmoother filter output would have substantially less lag for an equivalent amount of smoothing produced by the moving average. For example, a five-bar SMA has a cutoff period of approximately 10 bars and has two bars of lag. A SuperSmoother filter with a cutoff period of 10 bars has a lag a half bar larger than the two-pole modified Butterworth filter.Therefore, such a SuperSmoother filter has a maximum lag of approximately 1.5 bars and even less lag into the attenuation band of the filter. The differential in lag between moving average and SuperSmoother filter outputs becomes even larger when the cutoff periods are larger.
Market data contain noise, and removal of noise is the reason for using smoothing filters. In fact, market data contain several kinds of noise. I’ll group one kind of noise as systemic, caused by the random events of trades being exercised. A second kind of noise is aliasing noise, caused by the use of sampled data. Aliasing noise is the dominant term in the data for shorter cycle periods.
It is easy to think of market data as being a continuous waveform, but it is not. Using the closing price as representative for that bar constitutes one sample point. It doesn’t matter if you are using an average of the high and low instead of the close, you are still getting one sample per bar. Since sampled data is being used, there are some dSP aspects that must be considered. For example, the shortest analysis period that is possible (without aliasing)2 is a two-bar cycle.This is called the Nyquist frequency, 0.5 cycles per sample.A perfect two-bar sine wave cycle sampled at the peaks becomes a square wave due to sampling. However, sampling at the cycle peaks can- not be guaranteed, and the interference between the sampling frequency and the data frequency creates the aliasing noise.The noise is reduced as the data period is longer. For example, a four-bar cycle means there are four samples per cycle. Because there are more samples, the sampled data are a better replica of the sine wave component. The replica is better yet for an eight-bar data component.The improved fidelity of the sampled data means the aliasing noise is reduced at longer and longer cycle periods.The rate of reduction is 6 dB per octave. My experience is that the systemic noise rarely is more than 10 dB below the level of cyclic information, so that we create two conditions for effective smoothing of aliasing noise:
1. It is difficult to use cycle periods shorter that two octaves below the Nyquist frequency.That is, an eight-bar cycle component has a quantization noise level 12 dB below the noise level at the Nyquist frequency. longer cycle components therefore have a systemic noise level that exceeds the aliasing noise level.
2. A smoothing filter should have sufficient selectivity to reduce aliasing noise below the systemic noise level. Since aliasing noise increases at the rate of 6 dB per octave above a selected filter cutoff frequency and since the SuperSmoother attenuation rate is 12 dB per octave, the Super- Smoother filter is an effective tool to virtually eliminate aliasing noise in the output signal.
What are DSL Discontinued Signal Line?
A lot of indicators are using signal lines in order to determine the trend (or some desired state of the indicator) easier. The idea of the signal line is easy : comparing the value to it's smoothed (slightly lagging) state, the idea of current momentum/state is made.
Discontinued signal line is inheriting that simple signal line idea and it is extending it : instead of having one signal line, more lines depending on the current value of the indicator.
"Signal" line is calculated the following way :
When a certain level is crossed into the desired direction, the EMA of that value is calculated for the desired signal line
When that level is crossed into the opposite direction, the previous "signal" line value is simply "inherited" and it becomes a kind of a level
This way it becomes a combination of signal lines and levels that are trying to combine both the good from both methods.
In simple terms, DSL uses the concept of a signal line and betters it by inheriting the previous signal line's value & makes it a level.
Included:
Bar coloring
Alerts
Signals
Loxx's Expanded Source Types
FDI-Adaptive Non-Lag Moving Average [Loxx]FDI-Adaptive Non-Lag Moving Average is a Fractal Dimension Index adaptive Non-Lag moving Average. This acts more like a trend coloring indictor with gradient coloring.
What is the Fractal Dimension Index?
The goal of the fractal dimension index is to determine whether the market is trending or in a trading range. It does not measure the direction of the trend. A value less than 1.5 indicates that the price series is persistent or that the market is trending. Lower values of the FDI indicate a stronger trend. A value greater than 1.5 indicates that the market is in a trading range and is acting in a more random fashion.
Included
Bar coloring
Loxx's Expanded Source Types

HSV and HSL gradient Tools ( Built-in Drop-in replacement )Library "hsvColor"
HSV and HSL Gradient Tool Alternatives and helpers. Demo'd is built-in in the middle with HSL/HSV gradients on top/bottom
TODO: Solve for #000000 issue
rgbhsv(_col)
RGB Color to HSV Values
Parameters:
_col : Color input (#abc012 or color.name or color.rgb(0,0,0,0))
Returns: values
rgbhsv(_r, _g, _b, _t)
RGB Color to HSV Values
Parameters:
_r : Red 0 - 255
_g : Green 0 - 255
_b : Blue 0 - 255
_t : Transp 0 - 100
Returns: values
hsv(_h, _s, _v, _a)
HSV colors, Auto fix if past boundaries
Parameters:
_h : Hue Input (-360 - 360) or further
_s : Saturation 0.- 1.
_v : Value 0.- 1.
_a : Alpha 0.- 1.
Returns: Color output
hue(_col)
returns 0-359 hue on color wheel
Parameters:
_col :
Returns: 360 degree hue value
hsv_gradient(signal, _startVal, _endVal, _startCol, _endCol)
Color Gradient Replacement Function for HSV calculated Gradents
Parameters:
signal : Control signal
_startVal : start color limit
_endVal : end color limit
_startCol : start color
_endCol : end color
Returns: HSV calculated gradient
hsl_gradient(signal, _startVal, _endVal, _startCol, _endCol)
Color Gradient Replacement Function for HSV calculated Gradents
Parameters:
signal : Control signal
_startVal : start color limit
_endVal : end color limit
_startCol : start color
_endCol : end color
Returns: HSV calculated gradient
RSI - colour fillThis script showcases the new (overload) feature regarding the fill() function! 🥳
2 plots could be filled before, but with just 1 colour per bar, now the colour can be a gradient type.
In this example we have 2 plots
- rsiPlot , which plots the rsi value
- centerPlot, which plots the value 50 ('centre line')
Explanation of colour fill in the zone 50-80
Default when rsi > 50
- a bottom value is set at 50 (associated with colour aqua)
- and a top value is set at 80 (associated with colour red)
This zone (bottom -> top value) is filled with a gradient colour (50 - aqua -> 80 - red)
When rsi is towards 80, you see a red coloured zone at the rsi value,
while when rsi is around 50, you'll only see the colour aqua
The same principle is applied in the zone 20-50 when rsi < 50
Cheers!
Educational: FillThis script showcases the latest feature of colour fill between lines with gradient
There are 17 ema's, all with adjustable lengths.
In the settings there are 3 options: '1' , '2' , and '1 & 2' :
Option '1'
Here the highest - lowest lines are filled with a gradient colour,
dependable where the 3rd highest/lowest ema is situated in regard of these 2 lines:
Option '2'
Here the colour fill is applied between every ema and the one next to it.
The gradient colour is dependable where the ema is situated in regard of the highest - lowest line:
Option '1 & 2'
A combination of both options:
The setting 'switch colours at ema x' regulates the switch between bullish and bearish colours.
When close is above the chosen ema -> bullish colours, when below -> bearish colours.
Examples of other settings of 'switch colours at ema x' :
Colour switch when close above/below:
ema 14
ema 11
ema 8
ema 5
ema 2
The colours can be set below, both for option '1' and '2'
Cheers!

T3 Velocity [Loxx]T3 Velocity is a simple velocity indicator using T3 moving average that uses gradient colors to better identify trends.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included:
Bar coloring
Signals
Alerts
Loxx's Expanded Source Types

Standard-Deviation Adaptive Smoother MA [Loxx]Standard-Deviation Adaptive Smoother MA is a Smoother moving average with standard deviation adaptivity.
What is the Smoother Moving Average?
The Smoother filter is a faster-reacting smoothing technique which generates considerably less lag than the SMMA ( Smoothed Moving Average ). It gives earlier signals but can also create false signals due to its earlier reactions. This filter is sometimes wrongly mistaken for the superior Jurik Smoothing algorithm.
Included:
Bar coloring
Old Buddy Old Pal... Color Scheme Pallet GeneratorFor the Tasteful Pine Coder, Find your inner rainbow.
Color pallet tool with 7 standard colors as per syntax highlighters typical scheme.
Hue, Sat, Lum adjustments, transparency, and 4 different modes.
Please Share in comments any Chart Captures showcasing your designs if his tool helped you.
a library version is in the works as of may 2022. will enable a 7 color standard output direct into script with floating color input shifting of the whole pallet or partials.
(( next level past gradients)
ColorArrayLibrary "ColorArray"
Simple color array gradient tool.
makeGradient(size, _col1, _col2, _col3, _col4, _col5) Color Gradient Array from 5 colors.
Parameters:
size : : default 10
_col1 : : default #ff0000
_col2 : : default #ffff00
_col3 : : default #00ff00
_col4 : : default #00ffff
_col5 : : default #0000ff
Returns: array of colors to specified size.

Moving Average with Dynamic Color Gradient (WaveTrend Momentum)Similar scripts exist but I haven't seen one using WaveTrend and I haven't seen one that hand picks evenly divided colors between GREEN-YELLOW-RED.
The green is exact green, the yellow is exact yellow, and the red is exact red.
Not complicated, just useful.

Bollinger Band Gradient (BBG)The Bollinger Band Gradient Indicator uses plenty of Bollinger Bands to create a gradient-looking indicator to help with layered entries . It is similar to a Ribbon but better. This indicator is best used with any volume-related indicator so you can recede from entering into any position with too much momentum to rebound off of any line. Note that this indicator is best used with another strategy like pair trading. It is not recommended to trade based on this indicator only . Please stay aware of any news about the stock you are trading because some events may have a big impact and force the market to go bullish/bearish by a lot. This indicator can be used with all chart types and works well with many other indicators. It allows for complete customization and offers easy-to-understand settings which can be designated to a certain individual. You can modify all settings for the BBs which allows for an even more personalized and adapted Indicator that reflects your trading/ investing needs. You also have the option to choose which type of MAs will be used to create the Bollinger Bands , a few of which include: SMA, EMA, WMA, HMA, RMA, DMA, LSMA, VAMA, TMA, MF.
Bollinger Bands are a way to measure and visualize volatility . As volatility increases, the wider the bands become, and the more they deviate from the basis. Likewise, when volatility decreases, the gap between the bands and basis decreases. Yet a big advantage for not only this but many other indicators is created due to the ample count of different settings that are widely used, it is difficult to view the market through the eyes of all types of investors/traders . This indicator manages to counter exactly this issue, you will be able to see all of these settings on one chart and at one time and enter/exit positions accordingly.
Using this indicator will allow you to visualize entry and exit points with ease and make order layering (buying/selling in layers) much more simple. You can choose a certain amount of Bollinger Bands you would like displayed and customize all technical and style-related settings related to the BBs .
A few of the technical settings you can change for the Bollinger Bands are:
Bollinger Band count (Select how many BBs you want to be displayed.)
MA type used to make the Bollinger Bands ( EMA, SMA, WMA, etc.)
Source (close, open, high, low.)
BB length separately (The length of each Bollinger Band, its lookback. How many previous candles should it be based on? Choose each Bollinger Band's lookback length.)
BB deviator separately(The standard Deviator applied for the BB for both the upper and lower line.)
A few of the style settings you can change for each Bollinger Band are:
Fill (the color used to fill from the upper to the lower band)
Fill opacity % (the opacity used when filling the upper line to the lower line)
This indicator is unique because it can be used for all strategies and all trading styles , for example, day trading or long-term investing, really anything if used correctly. The reason it can be used in so many instances is a result of the detailed and in-depth settings tab that allows for complete customization. This allows the indicator to be used and to be useful in various situations and allows you to dominate the market. Integrated alerts also enhance your efficiency while using this indicator because you can choose to be notified at the crossing of any of the Bollinger Bands.
The technical part of this indicator plots the selected amount of Bollinger Bands using custom-built specified Bollinger Bands accordingly. Then it uses the style settings and styles it as you selected.
Green to Red Gradient for Dynamic / Color Changing IndicatorsI have evenly divided every color between green and red.
This gradient is useful for pine coders who are creating color changing, dynamic, or gradient indicators.

RGB color check tool with RSI [DM]Greetings colleagues.
Here I share a tool that uses the color gradient provided by PineCoders and lucf.
This tool was made for the reason that whenever we start with an idea for a script, we end up consuming a lot of time in selecting suitable colors.
An RSI was taken as a reference for the signal
You have multiple switches for axes, fill, background and colors
You can also change the background so that you can check the contrast with the signals.
The mix of colors with 8 boxes (4 channels for each color as detailed below) for each color since RGB has been defined
Red= 0 a 255
Green= 0 a 255
Blue= 0 a 255
Transparency= 0 a 100
I hope you enjoy it. [ ;-)
