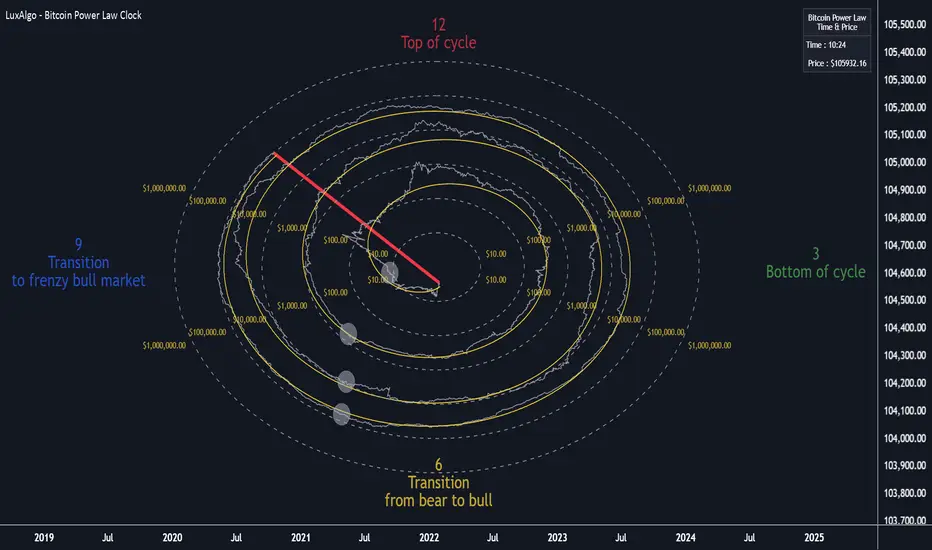
Bitcoin Power Law Clock [LuxAlgo]The Bitcoin Power Law Clock is a unique representation of Bitcoin prices proposed by famous Bitcoin analyst and modeler Giovanni Santostasi.
It displays a clock-like figure with the Bitcoin price and average lines as spirals, as well as the 12, 3, 6, and 9 hour marks as key points in the cycle.
🔶 USAGE
Giovanni Santostasi, Ph.D., is the creator and discoverer of the Bitcoin Power Law Theory. He is passionate about Bitcoin and has 12 years of experience analyzing it and creating price models.
As we can see in the above chart, the tool is super intuitive. It displays a clock-like figure with the current Bitcoin price at 10:20 on a 12-hour scale.
This tool only works on the 1D INDEX:BTCUSD chart. The ticker and timeframe must be exact to ensure proper functionality.
According to the Bitcoin Power Law Theory, the key cycle points are marked at the extremes of the clock: 12, 3, 6, and 9 hours. According to the theory, the current Bitcoin prices are in a frenzied bull market on their way to the top of the cycle.
🔹 Enable/Disable Elements
All of the elements on the clock can be disabled. If you disable them all, only an empty space will remain.
The different charts above show various combinations. Traders can customize the tool to their needs.
🔹 Auto scale
The clock has an auto-scale feature that is enabled by default. Traders can adjust the size of the clock by disabling this feature and setting the size in the settings panel.
The image above shows different configurations of this feature.
🔶 SETTINGS
🔹 Price
Price: Enable/disable price spiral, select color, and enable/disable curved mode
Average: Enable/disable average spiral, select color, and enable/disable curved mode
🔹 Style
Auto scale: Enable/disable automatic scaling or set manual fixed scaling for the spirals
Lines width: Width of each spiral line
Text Size: Select text size for date tags and price scales
Prices: Enable/disable price scales on the x-axis
Handle: Enable/disable clock handle
Halvings: Enable/disable Halvings
Hours: Enable/disable hours and key cycle points
🔹 Time & Price Dashboard
Show Time & Price: Enable/disable time & price dashboard
Location: Dashboard location
Size: Dashboard size
Forecasting
M2 Growth Rate vs Borrowing RateHave you ever wondered how fast M2 is actually growing? Have you ever wanted to compare its percentage growth rate to the actual cost of borrowing? Are you also, like me, a giant nerd with too much time on your hands?
M2 Growth Rate vs Borrowing Rate
This Pine Script indicator analyzes the annualized growth rate of M2 money supply and compares it to key borrowing rates, providing insights into the relationship between money supply expansion and borrowing costs. Users can select between US M2 or a combined M2 (aggregating US, EU, China, Japan, and UK money supplies, adjusted for currency exchange rates). The M2 growth period is customizable, offering options from 1 month to 5 years for flexible analysis over different time horizons. The indicator fetches monthly data for US M2, EU M2, China M2, Japan M2, UK M2, and exchange rates (EURUSD, CNYUSD, JPYUSD, GBPUSD) to compute the combined M2 in USD terms.
It plots the annualized M2 growth rate alongside borrowing rates, including US 2-year and 10-year Treasury yields, corporate bond effective yield, high-yield bond effective yield, and 30-year US mortgage rates. Borrowing rates are color-coded for clarity: red if the rate exceeds the selected M2 growth rate, and green if below, highlighting relative dynamics. Displayed on a separate pane with a zero line for reference, the indicator includes labeled plots for easy identification.
This tool is designed for informational purposes, offering a visual framework to explore economic trends without providing trading signals or financial advice.
Bitcoin Power Law [LuxAlgo]The Bitcoin Power Law tool is a representation of Bitcoin prices first proposed by Giovanni Santostasi, Ph.D. It plots BTCUSD daily closes on a log10-log10 scale, and fits a linear regression channel to the data.
This channel helps traders visualise when the price is historically in a zone prone to tops or located within a discounted zone subject to future growth.
🔶 USAGE
Giovanni Santostasi, Ph.D. originated the Bitcoin Power-Law Theory; this implementation places it directly on a TradingView chart. The white line shows the daily closing price, while the cyan line is the best-fit regression.
A channel is constructed from the linear fit root mean squared error (RMSE), we can observe how price has repeatedly oscillated between each channel areas through every bull-bear cycle.
Excursions into the upper channel area can be followed by price surges and finishing on a top, whereas price touching the lower channel area coincides with a cycle low.
Users can change the channel areas multipliers, helping capture moves more precisely depending on the intended usage.
This tool only works on the daily BTCUSD chart. Ticker and timeframe must match exactly for the calculations to remain valid.
🔹 Linear Scale
Users can toggle on a linear scale for the time axis, in order to obtain a higher resolution of the price, (this will affect the linear regression channel fit, making it look poorer).
🔶 DETAILS
One of the advantages of the Power Law Theory proposed by Giovanni Santostasi is its ability to explain multiple behaviors of Bitcoin. We describe some key points below.
🔹 Power-Law Overview
A power law has the form y = A·xⁿ , and Bitcoin’s key variables follow this pattern across many orders of magnitude. Empirically, price rises roughly with t⁶, hash-rate with t¹² and the number of active addresses with t³.
When we plot these on log-log axes they appear as straight lines, revealing a scale-invariant system whose behaviour repeats proportionally as it grows.
🔹 Feedback-Loop Dynamics
Growth begins with new users, whose presence pushes the price higher via a Metcalfe-style square-law. A richer price pool funds more mining hardware; the Difficulty Adjustment immediately raises the hash-rate requirement, keeping profit margins razor-thin.
A higher hash rate secures the network, which in turn attracts the next wave of users. Because risk and Difficulty act as braking forces, user adoption advances as a power of three in time rather than an unchecked S-curve. This circular causality repeats without end, producing the familiar boom-and-bust cadence around the long-term power-law channel.
🔹 Scale Invariance & Predictions
Scale invariance means that enlarging the timeline in log-log space leaves the trajectory unchanged.
The same geometric proportions that described the first dollar of value can therefore extend to a projected million-dollar bitcoin, provided no catastrophic break occurs. Institutional ETF inflows supply fresh capital but do not bend the underlying slope; only a persistent deviation from the line would falsify the current model.
🔹 Implications
The theory assigns scarcity no direct role; iterative feedback and the Difficulty Adjustment are sufficient to govern Bitcoin’s expansion. Long-term valuation should focus on position within the power-law channel, while bubbles—sharp departures above trend that later revert—are expected punctuations of an otherwise steady climb.
Beyond about 2040, disruptive technological shifts could alter the parameters, but for the next order of magnitude the present slope remains the simplest, most robust guide.
Bitcoin behaves less like a traditional asset and more like a self-organising digital organism whose value, security, and adoption co-evolve according to immutable power-law rules.
🔶 SETTINGS
🔹 General
Start Calculation: Determine the start date used by the calculation, with any prior prices being ignored. (default - 15 Jul 2010)
Use Linear Scale for X-Axis: Convert the horizontal axis from log(time) to linear calendar time
🔹 Linear Regression
Show Regression Line: Enable/disable the central power-law trend line
Regression Line Color: Choose the colour of the regression line
Mult 1: Toggle line & fill, set multiplier (default +1), pick line colour and area fill colour
Mult 2: Toggle line & fill, set multiplier (default +0.5), pick line colour and area fill colour
Mult 3: Toggle line & fill, set multiplier (default -0.5), pick line colour and area fill colour
Mult 4: Toggle line & fill, set multiplier (default -1), pick line colour and area fill colour
🔹 Style
Price Line Color: Select the colour of the BTC price plot
Auto Color: Automatically choose the best contrast colour for the price line
Price Line Width: Set the thickness of the price line (1 – 5 px)
Show Halvings: Enable/disable dotted vertical lines at each Bitcoin halving
Halvings Color: Choose the colour of the halving lines

Intraweek Highs & Lows🔎 Track and analyze intraweek price extremes with full flexibility.
The indicator detects weekly highs or lows for any selected weekday and monitors when other days break those levels.
⚙️ Inputs
Select day
Pick which weekday’s extreme you want to monitor.
Find Low/High
Select whether you want to track Lows or Highs.
Use candle Wick/Body
Choose if extremes are calculated by full wick or candle body.
Cutoff date
Toggle the date-based filter and choose the starting date for event display.

RACZ-SIGNAL-V2.1RACZ-SIGNAL-V2.1 – Reactive Analytical Confluence Zones
Developed by: RACZ Trading
Indicator Type: Multi-Factor Confluence System
Overlay: Off (separate pane)
Purpose: Detect powerful trade opportunities through confluence of technical signals.
⸻
🔍 What is RACZ?
RACZ stands for Reactive Analytical Confluence Zones.
It’s a high-precision trading tool built for traders who rely on multi-signal confirmation, momentum alignment, and market structure awareness.
Rather than relying on a single technical metric, RACZ dynamically combines RSI, VWAP-RSI, Divergence, ADX, and Volume Analytics to produce a composite signal score from 0 to 12 — the higher the score, the stronger the signal.
⸻
🧠 How It Works – Core Components
1. RSI Analysis
• Detects momentum shifts.
• Compares RSI value to overbought (default: 67) and oversold (default: 33) thresholds.
• Adds points to Bullish or Bearish score.
2. VWAP-RSI
• Uses RSI based on VWAP (Volume Weighted Average Price).
• Adds weight to signals influenced by volume-adjusted price movement.
3. Divergence Detection
• Detects potential reversal zones.
• Bullish Divergence: RSI crosses up from low zone.
• Bearish Divergence: RSI crosses down from high zone.
• Strong confluence signal when present.
4. ADX Dynamic Strength Filter
• Custom-calculated ADX (trend strength indicator).
• Uses a dynamic threshold derived from SMA of ADX over a lookback period, scaled by a factor (default 0.9).
• Ensures signals are only validated in strong trend environments.
5. Volume Z-Score
• Detects anomalies in volume behavior.
• Z-score applied to 20-period volume average & deviation.
• Labels spikes, drops, high/low volume conditions.
⸻
📊 Signal Scoring Logic
Each component (RSI, VWAP-RSI, Divergence, ADX) can score up to 3 points each.
• Bullish Score: Total from bullish alignment of each factor.
• Bearish Score: Total from bearish alignment of each factor.
• Signal Power = max(bullish, bearish)
📈 Signal Interpretation
• BUY: Bullish Score > Bearish Score
• SELL: Bearish Score > Bullish Score
• NEUTRAL: Scores are equal
• Signal power is plotted on a 0–12 histogram:
• 0–5 = Weak
• 6–8 = Medium
• 9–12 = Strong (High Confluence Zone)
🖥️ Live Status Panel (Top-Right Corner)
This real-time panel helps you break down the signal:Component
Value Explanation: RSI / VWAP / DIV / ADX
Shows points contributing to signal
SIGNAL: Current market bias (BUY, SELL, NEUTRAL)
VOLUME: Volume classification (Spike, Drop, High, Low, Normal)
Color-coded for quick interpretation.
✅ How to Use
1. Look at Histogram: Bars ≥6 suggest valid setups, especially ≥9.
2. Confirm Panel Agreement: Check which components are supporting the signal.
3. Validate Volume: Unusual spikes/drops often precede strong moves.
4. Follow Direction: Use BUY/SELL signals aligned with signal power and trend.
⸻
⚙️ Customizable Inputs
• RSI period, overbought/oversold levels
• VWAP-RSI period
• ADX period and dynamic threshold settings
• Fully adjustable to fit any trading style
⸻
🚀 Why Choose RACZ?
• Clarity: Scores & signals derived from multiple tools, not just one.
• Confluence Logic: Designed for traders who look for confirmation across indicators.
• Speed: Real-time responsiveness to changing market dynamics.
• Volume Awareness: Integrated volume intelligence gives a deeper edge.
⸻
⚠️ Disclaimer
This indicator is intended strictly for educational and informational purposes only. It is not financial advice and should not be used to make actual investment decisions. Always conduct your own research or consult with a licensed financial advisor before trading or investing. Use of this script is at your own risk.
Yelober_Momentum_BreadthMI# Yelober_Momentum_BreadthMI: Market Breadth Indicator Analysis
## Overview
The Yelober_Momentum_BreadthMI is a comprehensive market breadth indicator designed to monitor market internals across NYSE and NASDAQ exchanges. It tracks several key metrics including up/down volume ratios, TICK readings, and trend momentum to provide traders with real-time insights into market direction, strength, and potential turning points.
## Indicator Components
This indicator displays a table with data for:
- NYSE breadth metrics
- NASDAQ breadth metrics
- NYSE TICK data and trends
- NASDAQ TICK (TICKQ) data and trends
## Table Columns and Interpretation
### Column 1: Market
Identifies the data source:
- **NYSE**: New York Stock Exchange data
- **NASDAQ**: NASDAQ exchange data
- **Tick**: NYSE TICK index
- **TickQ**: NASDAQ TICK index
### Column 2: Ratio
Shows the current ratio values with different calculations depending on the row:
- **For NYSE/NASDAQ rows**: Displays the up/down volume ratio
- Positive values (green): More up volume than down volume
- Negative values (red): More down volume than up volume
- The magnitude indicates the strength of the imbalance
- **For Tick/TickQ rows**: Shows the ratio of positive to negative ticks plus the current TICK reading in parentheses
- Format: "Ratio (Current TICK value)"
- Positive values (green): More stocks ticking up than down
- Negative values (red): More stocks ticking down than up
### Column 3: Trend
Displays the directional trend with both a symbol and value:
- **For NYSE/NASDAQ rows**: Shows the VOLD (volume difference) slope
- "↗": Rising trend (positive slope)
- "↘": Falling trend (negative slope)
- "→": Neutral/flat trend (minimal slope)
- **For Tick/TickQ rows**: Shows the slope of the ratio history
- Color-coding: Green for positive momentum, Red for negative momentum, Gray for neutral
The trend column is particularly important as it shows the current momentum of the market. The indicator applies specific thresholds for color-coding:
- NYSE: Green when normalized value > 2, Red when < -2
- NASDAQ: Green when normalized value > 3.5, Red when < -3.5
- TICK/TICKQ: Green when slope > 0.01, Red when slope < -0.01
## How to Use This Indicator
### Basic Interpretation
1. **Market Direction**: When multiple rows show green ratios and upward trends, it suggests strong bullish market internals. Conversely, red ratios and downward trends indicate bearish internals.
2. **Market Breadth**: The magnitude of the ratios indicates how broad-based the market movement is. Higher absolute values suggest stronger market breadth.
3. **Momentum Shifts**: When trend arrows change direction or colors shift, it may signal a potential reversal or change in market momentum.
4. **Divergences**: Look for divergences between different markets (NYSE vs NASDAQ) or between ratios and trends, which can indicate potential market turning points.
### Advanced Usage
- **Volume Normalization**: The indicator includes options to normalize volume data (none, tens, thousands, millions, 10th millions) to handle different exchange scales.
- **Trend Averaging**: The slope calculation uses an averaging period (default: 5) to smooth out noise and identify more reliable trend signals.
## Examples for Interpretation
### Example 1: Strong Bullish Market
```
| Market | Ratio | Trend |
|--------|---------|-----------|
| NYSE | 1.75 | ↗ 2.85 |
| NASDAQ | 2.10 | ↗ 4.12 |
| Tick | 2.45 (485) | ↗ 0.05 |
| TickQ | 1.95 (320) | ↗ 0.03 |
```
**Interpretation**: All metrics are positive and trending upward (green), indicating a strong, broad-based rally. The high ratio values show significant bullish dominance. This suggests continuation of the upward move with good momentum.
### Example 2: Weakening Market
```
| Market | Ratio | Trend |
|--------|---------|-----------|
| NYSE | 0.45 | ↘ -1.50 |
| NASDAQ | 0.85 | → 0.30 |
| Tick | 0.95 (105) | ↘ -0.02 |
| TickQ | 1.20 (160) | → 0.00 |
```
**Interpretation**: The market is showing mixed signals with positive but low ratios, while NYSE and TICK trends are turning negative. NASDAQ shows neutral to slightly positive momentum. This divergence often occurs near market tops or during consolidation phases. Traders should be cautious and consider reducing position sizes.
### Example 3: Negative Market Turning Positive
```
| Market | Ratio | Trend |
|--------|---------|-----------|
| NYSE | -1.25 | ↗ 1.75 |
| NASDAQ | -0.95 | ↗ 2.80 |
| Tick | -1.35 (-250) | ↗ 0.04 |
| TickQ | -1.10 (-180) | ↗ 0.02 |
```
**Interpretation**: This is a potential bottoming pattern. Current ratios are still negative (red) showing overall negative breadth, but the trends are all positive (green arrows), indicating improving momentum. This divergence often occurs at market bottoms and could signal an upcoming reversal. Look for confirmation with price action before establishing long positions.
### Example 4: Mixed Market with Divergence
```
| Market | Ratio | Trend |
|--------|---------|-----------|
| NYSE | 1.45 | ↘ -2.25 |
| NASDAQ | -0.85 | ↘ -3.80 |
| Tick | 1.20 (230) | ↘ -0.03 |
| TickQ | -0.75 (-120) | ↘ -0.02 |
```
**Interpretation**: There's a significant divergence between NYSE (positive ratio) and NASDAQ (negative ratio), while all trends are negative. This suggests sector rotation or a market that's weakening but with certain segments still showing strength. Often seen during late-stage bull markets or in transitions between leadership groups. Consider reducing risk exposure and focusing on relative strength sectors.
## Practical Trading Applications
1. **Confirmation Tool**: Use this indicator to confirm price movements. Strong breadth readings in the direction of the price trend increase confidence in trade decisions.
2. **Early Warning System**: Watch for divergences between price and breadth metrics, which often precede market turns.
3. **Intraday Trading**: The real-time nature of TICK and volume data makes this indicator valuable for day traders to gauge intraday momentum shifts.
4. **Market Regime Identification**: Sustained readings can help identify whether the market is in a trend or chop regime, allowing for appropriate strategy selection.
This breadth indicator is most effective when used in conjunction with price action and other technical indicators rather than in isolation.

IU Market Rhythm WaveDESCRIPTION:
The IU Market Rhythm Wave is a multi-dimensional indicator designed to reveal the underlying rhythm and energy of the market. By analyzing price momentum, harmonic oscillations, volume behavior, and market breadth, it helps traders identify high-quality long and short wave signals. It also visualizes rhythm bands, wave strength zones, and harmonic levels to provide comprehensive context for decision-making.
This tool is best used on trending instruments where rhythm cycles and volume patterns create clear wave-based opportunities.
USER INPUTS:
Rhythm Cycle Length
Controls the main lookback period used to calculate price waves, harmonic oscillation, volume rhythm, and breath. A longer cycle smooths signals, while a shorter cycle makes them more responsive. Recommended range: 8 to 35.
Wave Signal Strength
Multiplies the standard deviation of rhythm to define dynamic breakout thresholds. A higher value results in fewer but stronger signals, filtering out minor fluctuations.
Harmonic Filter
Applies a sensitivity filter to the harmonic mean and standard deviation. It helps eliminate weak or noisy signals and ensures rhythm-based signals align with harmonic structure.
Show Wave Energy Zones
Toggles background color shading based on current rhythm conditions. Greenish zones indicate strong upward rhythm, red for strong downward rhythm, yellow for positive bias, and gray for weak or neutral zones.
Show Rhythm Bands
Enables the display of upper and lower rhythm bands derived from ATR and rhythm volatility. These bands act as dynamic price envelopes and potential support/resistance zones.
Wave Zone Opacity
Adjusts the transparency of background energy zones, allowing users to control how prominent these zones appear on the chart. Range: 60 to 90 for optimal visibility.
INDICATOR LOGIC:
The indicator combines multiple rhythmic components into a composite rhythm score:
1. Price Wave – Based on momentum (rate of price change) smoothed by a moving average.
2. Harmonic Oscillation – Measures how far price has deviated from a central harmonic average (HLC3).
3. Volume Rhythm – Uses volume’s deviation from its mean, standardized by its volatility.
4. Market Breath – Captures range expansion and closing strength relative to range.
These elements form the Raw Rhythm, which is further smoothed to produce the Market Rhythm. When the rhythm exceeds statistically calculated thresholds and other conditions like volume confirmation and harmonic proximity are met, wave signals are triggered.
Harmonic Fibonacci levels (0.236, 0.382, 0.618, 0.764) are also calculated every rhythm cycle to identify nearby structural price zones. Signals occurring near these levels are considered more reliable.
The Rhythm Bands use ATR and rhythm strength to define dynamic boundaries above and below price. Visual zones and arrows mark rhythm shifts and highlight the underlying energy of the market.
WHY IT IS UNIQUE:
This indicator goes beyond traditional oscillators or volume indicators by blending multiple market dimensions into one rhythmic framework. It adapts to volatility, applies harmonic structure awareness, and filters signals based on real-time market conditions. It offers:
* A unique rhythm-based view of price, volume, and volatility
* Dynamic, adaptive signal generation and zone coloring
* Visual analytics and contextual data in a summary table
* Signal filtering using harmonic alignment and market breath
Its real-time responsiveness and multi-layered logic make it suitable for intraday, swing, and positional traders.
HOW USER CAN BENEFIT FROM IT:
* Spot high-conviction long or short entries when rhythm, volume, and structure align
* Avoid low-quality trades during weak or noisy rhythm periods
* Use visual wave zones to gauge trend strength and rhythm direction
* Monitor harmonic proximity to enter or exit near key structural levels
* Apply rhythm bands for dynamic stop-loss and target setting
* Use rhythm direction arrows and analytics table to gain deeper market insight
DISCLAIMER:
This indicator is created for educational and informational purposes only. It does not constitute financial advice or a recommendation to buy or sell any asset. All trading involves risk, and users should conduct their own analysis or consult with a qualified financial advisor before making any trading decisions. The creator is not responsible for any losses incurred through the use of this tool. Use at your own discretion.
Linear Regression Forecast (ADX Adaptive)Linear Regression Forecast (ADX Adaptive)
This indicator is a dynamic price projection tool that combines multiple linear regression forecasts into a single, adaptive forecast curve. By integrating trend strength via the ADX and directional bias, it aims to visualize how price might evolve in different market environments—from strong trends to mean-reverting conditions.
Core Concept:
This tool builds forward price projections based on a blend of linear regression models with varying lookback lengths (from 2 up to a user-defined max). It then adjusts those projections using two key mechanisms:
ADX-Weighted Forecast Blending
In trending conditions (high ADX), the model follows the raw forecast direction. In ranging markets (low ADX), the forecast flips or reverts, biasing toward mean-reversion. A logistic transformation of directional bias, controlled by a steepness parameter, determines how aggressively this blending reacts to price behavior.
Volatility Scaling
The forecast’s magnitude is scaled based on ADX and directional conviction. When trends are unclear (low ADX or neutral bias), the projection range expands to reflect greater uncertainty and volatility.
How It Works:
Regression Curve Generation
For each regression length from 2 to maxLength, a forward projection is calculated using least-squares linear regression on the selected price source. These forecasts are extrapolated into the future.
Directional Bias Calculation
The forecasted points are analyzed to determine a normalized bias value in the range -1 to +1, where +1 means strongly bullish, -1 means strongly bearish, and 0 means neutral.
Logistic Bias Transformation
The raw bias is passed through a logistic sigmoid function, with a user-defined steepness. This creates a probability-like weight that favors either following or reversing the forecast depending on market context.
ADX-Based Weighting
ADX determines the weighting between trend-following and mean-reversion modes. Below ADX 20, the model favors mean-reversion. Above 25, it favors trend-following. Between 20 and 25, it linearly blends the two.
Blended Forecast Curve
Each forecast point is blended between trend-following and mean-reverting values, scaled for volatility.
What You See:
Forecast Lines: Projected future price paths drawn in green or red depending on direction.
Bias Plot: A separate plot showing post-blend directional bias as a percentage, where +100 is strongly bullish and -100 is strongly bearish.
Neutral Line: A dashed horizontal line at 0 percent bias to indicate neutrality.
User Inputs:
-Max Regression Length
-Price Source
-Line Width
-Bias Steepness
-ADX Length and Smoothing
Use Cases:
Visualize expected price direction under different trend conditions
Adjust trading behavior depending on trending vs ranging markets
Combine with other tools for deeper analysis
Important Notes:
This indicator is for visualization and analysis only. It does not provide buy or sell signals and should not be used in isolation. It makes assumptions based on historical price action and should be interpreted with market context.
MTF Pivot Fib Speed Resistance FansOverview
This Pine Script indicator, titled "MTF Pivot Fib Speed Resistance Fans", is a multi-timeframe tool that automatically plots Fib Speed Resistance Fan lines based on pivot structures derived from higher timeframes. It mirrors the functionality of TradingView’s built-in “Fib Speed Resistance Fan” drawing tool, but in a dynamic, programmatic way. It uses pivot highs and lows to anchor fan projections, drawing forward-facing trend lines that align with well-known Fibonacci ratios and their extensions.
Pivot Detection Logic
The script identifies pivots by comparing the current bar’s high and low against the highest and lowest prices over a user-defined pivot period. This pivot detection occurs on a higher timeframe of your choice, giving a broader and more strategic view of price structure. The script tracks direction changes in the pivot trend and stores only the most recent few pivots to maintain clean and meaningful fan drawings.
Fan Direction Control
The user can select whether to draw fans for "Buys", "Sells", or "Both". The script only draws fan lines when a new directional move is detected based on the pivot structure and the selected bias. For example, in “Buys” mode, a rising pivot followed by another higher low will trigger upward fan projections.
Fib Speed Resistance Levels
Once two pivots are identified, the script draws multiple fan lines from the first pivot outward, at angles defined by a preset list of Fibonacci levels. These fan lines help visualize speed and strength of a price move.
The script also draws a horizontal line from the pivot for additional confluence at the base level (1.0).
Price Level Plotting
In addition to drawing fan lines, the indicator also plots their price levels on the right-hand price scale. This makes it easier for users to visually reference the projected support and resistance levels without needing to trace the lines manually across the chart.
Mapping to TradingView’s "Fib Speed Resistance Fan"
The expanded set of values used in this script is not arbitrary—they closely align with the default and extended levels available in TradingView's built-in "Fib Speed Resistance Fan" tool.
TradingView’s Fib Fan tool offers several levels by default, including traditional Fibonacci ratios like 0.382, 0.5, 0.618, and 1. However, if you right-click the tool and open its settings, you’ll find additional toggles for levels like 1.618, 2.000, 2.618, and even 4.000. These deeper levels are used to project stronger trend continuations beyond the standard retracement zones.
The inclusion of levels such as 0.25, 0.75, and 1.34 reflects configurations that are available when you manually add or customize levels in TradingView’s fan tool. While 1.34 is not a canonical Fibonacci ratio, it is often found in hybrid Gann/Fib methods and is included in some preset templates in TradingView’s drawing tool for advanced users.
By incorporating these levels directly into the Pine Script, the indicator faithfully reproduces the fan structure users would manually draw using TradingView’s graphical Fib Fan tool—but does so programmatically, dynamically, and with multi-timeframe control. This eliminates manual errors, allows for responsive updating, and adds custom visual tracking via the price scale.
These values are standardized within the context of TradingView's Fib Fan tool and not made up. This script automates what the manual drawing tool achieves, with added precision and flexibility.

Golden Crossover Momentum Check📊 Golden Cross Momentum Screener — Summary
🔍 What It Does
This indicator identifies Golden Cross events — where the 50 EMA crosses above the 200 EMA, signaling a potential long-term trend reversal — and evaluates the momentum strength to help determine whether price is likely to:
Surge immediately (Group B), or
Retrace first (Group A)
It uses 5 momentum-confirming conditions to score the quality of the breakout and display a single label on the chart with a classification.
✅ Momentum Conditions Validated
RSI > 60 and rising – Indicates bullish buying pressure
MACD Histogram > 0 and rising – Confirms increasing momentum
Volume > 2× 20-day average – Validates participation on the breakout
ADX > 25 – Measures trend strength
Price is >5% above 200 EMA – Confirms price extension above long-term trend
Each passing condition adds 1 point to the momentum score (0–5).
📈 How to Use
Watch for a Golden Cross signal (triangle appears below candle)
If momentum score ≥ 4, the script labels the setup as:
"🚀 Surge Likely (Group B)" — consider immediate breakout entries
If score is 2–3, labeled:
"🔄 Pullback Likely (Group A)" — expect retest/consolidation before continuation
If score < 2, labeled:
"❌ No Momentum Confirmed" — avoid or wait for confirmation

IU Liquidity Flow TrackerDESCRIPTION
The IU Liquidity Flow Tracker is a powerful market analysis tool designed to visualize hidden buying and selling activity by analyzing price action, volume behavior, market pressure, and depth. It provides a composite view of liquidity dynamics to help traders identify accumulation, distribution, and neutral phases with high clarity.
This indicator is ideal for traders who want to gauge the flow of market participants and make informed entry/exit decisions based on the underlying liquidity structure.
USER INPUTS:
* Flow Analysis Period: Length used for analyzing price spread and volume flow.
* Pressure Sensitivity: Adjusts the sensitivity of threshold detection for flow classification.
* Flow Smoothing: Controls the smoothing applied to raw flow data.
* Market Depth Analysis: Sets the depth range for rejection and wick analysis.
* Colors: Customize colors for accumulation, distribution, neutral zones, and pressure visualization.
INDICATOR LOGIC:
The IU Liquidity Flow Tracker uses a multi-factor model to evaluate market behavior:
1. Liquidity Pressure: Combines price spread, price efficiency, and volume imbalance.
2. Flow Direction: Weighted momentum using short, medium, and long-term price changes adjusted for volume.
3. Market Depth: Wick-based rejection scoring to estimate buying/selling aggressiveness at price extremes.
4. Composite Flow Index: Blended value of flow direction, pressure, and depth—smoothed for clarity.
5. Dynamic Thresholds: Automatically adjusts based on volatility to classify the market into:
* Accumulation: Strong buying signals.
* Distribution: Strong selling signals.
* Neutral: No significant flow dominance.
6. Entry Signals: Long/Short signals are generated when flow state shifts, supported by momentum, volume surge, and depth strength.
WHY IT IS UNIQUE:
Unlike typical indicators that rely solely on price or volume, this tool combines spread behavior, volume polarity, momentum weighting, and price rejection zones into a single visual interface. It dynamically adjusts sensitivity based on market volatility, helping avoid false signals during sideways or low-volume periods.
It is not based on any traditional indicator (RSI, MACD, etc.), making it ideal for traders looking for an original and data-driven market read.
HOW USER CAN BENEFIT FROM IT:
* Understand Market Context: Know whether the market is being accumulated, distributed, or ranging.
* Improve Entries/Exits: Use flow transitions combined with volume confirmation for high-probability setups.
* Spot Institutional Activity: Detect subtle shifts in liquidity that precede major price moves.
* Reduce Whipsaws: Dynamic thresholds and multi-factor confirmation help filter noise.
* Use with Any Style: Whether you're a swing trader, day trader, or scalper, this tool adapts to different timeframes and strategies.
DISCLAIMER:
This indicator is created for educational and informational purposes only. It does not constitute financial advice or a recommendation to buy or sell any asset. All trading involves risk, and users should conduct their own analysis or consult with a qualified financial advisor before making any trading decisions. The creator is not responsible for any losses incurred through the use of this tool. Use at your own discretion.
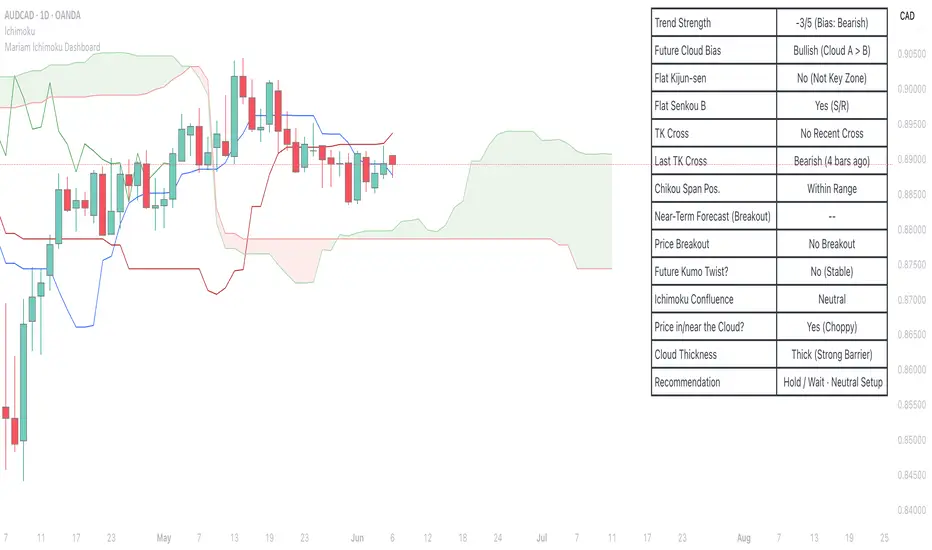
Mariam Ichimoku DashboardPurpose
The Mariam Ichimoku Dashboard is designed to simplify the Ichimoku trading system for both beginners and experienced traders. It provides a complete view of trend direction, strength, momentum, and key signals all in one compact dashboard on your chart. This tool helps traders make faster and more confident decisions without having to interpret every Ichimoku element manually.
How It Works
1. Trend Strength Score
Calculates a score from -5 to +5 based on Ichimoku components.
A high positive score means strong bullish momentum.
A low negative score shows strong bearish conditions.
A near-zero score indicates a sideways or unclear market.
2. Future Cloud Bias
Looks 26 candles ahead to determine if the future cloud is bullish or bearish.
This helps identify the longer-term directional bias of the market.
3. Flat Kijun / Flat Senkou B
Detects flat zones in the Kijun or Senkou B lines.
These flat areas act as strong support or resistance and can attract price.
4. TK Cross
Identifies Tenkan-Kijun crosses:
Bullish Cross means Tenkan crosses above Kijun
Bearish Cross means Tenkan crosses below Kijun
5. Last TK Cross Info
Shows whether the last TK cross was bullish or bearish and how many candles ago it happened.
Helps track trend development and timing.
6. Chikou Span Position
Checks if the Chikou Span is above, below, or inside past price.
Above means bullish momentum
Below means bearish momentum
Inside means mixed or indecisive
7. Near-Term Forecast (Breakout)
Warns when price is near the edge of the cloud, preparing for a potential breakout.
Useful for anticipating price moves.
8. Price Breakout
Shows if price has recently broken above or below the cloud.
This can confirm the start of a new trend.
9. Future Kumo Twist
Detects upcoming twists in the cloud, which often signal potential trend reversals.
10. Ichimoku Confluence
Measures how many key Ichimoku signals are in agreement.
The more signals align, the stronger the trend confirmation.
11. Price in or Near the Cloud
Displays if the price is inside the cloud, which often indicates low clarity or a choppy market.
12. Cloud Thickness
Shows whether the cloud is thin or thick.
Thick clouds provide stronger support or resistance.
Thin clouds may allow easier breakouts.
13. Recommendation
Gives a simple trading suggestion based on all major signals.
Strong Buy, Strong Sell, or Hold.
Helps simplify decision-making at a glance.
Features
All major Ichimoku signals summarized in one panel
Real-time trend strength scoring
Detects flat zones, crosses, cloud twists, and breakouts
Visual alerts for trend alignment and signal confluence
Compact, clean design
Built with simplicity in mind for beginner traders
Tips
Best used on 15-minute to 1-hour charts for short-term trading
Avoid entering trades when price is inside the cloud because the market is often indecisive
Wait for alignment between trend score, TK cross, cloud bias, and confluence
Use the dashboard to support your trading strategy, not replace it
Enable alerts for major confluence or upcoming Kumo twists
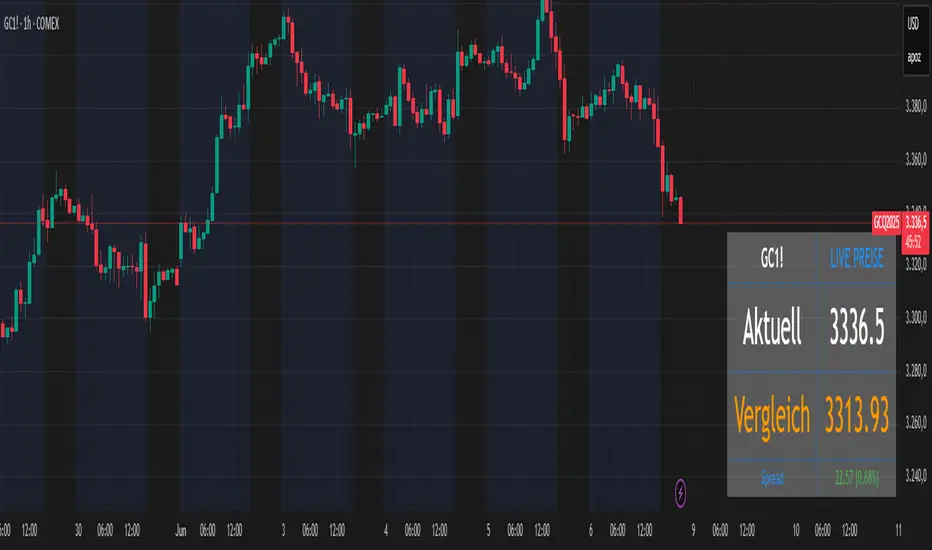
Futures vs CFD Price Display
🎯 Trading the same asset in CFDs and Futures but tired of switching charts to compare prices? This is your indicator!
Stop the constant chart hopping! This live price comparison shows you instantly where the better conditions are.
✨ What you get:
Bidirectional: Works in both Futures AND CFD charts
Live prices: Real-time comparison of both markets
Spread calculation: Automatic difference in points and percentage
Fully customizable: Colors, position, size to your liking
Professional design: Clean display with symbol header
🎯 Perfect for:
Gold traders (Futures vs CFD)
Arbitrage strategies
Spread monitoring
Multi-broker comparisons
⚙️ Customization:
3 sizes (Small/Normal/Large) for all screens
4 positions available
Individual color schemes
Toggle features on/off
💡 Simply enter the symbol and keep both markets in sight!
Notice: "Co-developed with Claude AI (Anthropic) - because even AI needs to pay the server bills! 😄"
DCA Investment Tracker Pro [tradeviZion]DCA Investment Tracker Pro: Educational DCA Analysis Tool
An educational indicator that helps analyze Dollar-Cost Averaging strategies by comparing actual performance with historical data calculations.
---
💡 Why I Created This Indicator
As someone who practices Dollar-Cost Averaging, I was frustrated with constantly switching between spreadsheets, calculators, and charts just to understand how my investments were really performing. I wanted to see everything in one place - my actual performance, what I should expect based on historical data, and most importantly, visualize where my strategy could take me over the long term .
What really motivated me was watching friends and family underestimate the incredible power of consistent investing. When Napoleon Bonaparte first learned about compound interest, he reportedly exclaimed "I wonder it has not swallowed the world" - and he was right! Yet most people can't visualize how their $500 monthly contributions today could become substantial wealth decades later.
Traditional DCA tracking tools exist, but they share similar limitations:
Require manual data entry and complex spreadsheets
Use fixed assumptions that don't reflect real market behavior
Can't show future projections overlaid on actual price charts
Lose the visual context of what's happening in the market
Make compound growth feel abstract rather than tangible
I wanted to create something different - a tool that automatically analyzes real market history, detects volatility periods, and shows you both current performance AND educational projections based on historical patterns right on your TradingView charts. As Warren Buffett said: "Someone's sitting in the shade today because someone planted a tree a long time ago." This tool helps you visualize your financial tree growing over time.
This isn't just another calculator - it's a visualization tool that makes the magic of compound growth impossible to ignore.
---
🎯 What This Indicator Does
This educational indicator provides DCA analysis tools. Users can input investment scenarios to study:
Theoretical Performance: Educational calculations based on historical return data
Comparative Analysis: Study differences between actual and theoretical scenarios
Historical Projections: Theoretical projections for educational analysis (not predictions)
Performance Metrics: CAGR, ROI, and other analytical metrics for study
Historical Analysis: Calculates historical return data for reference purposes
---
🚀 Key Features
Volatility-Adjusted Historical Return Calculation
Analyzes 3-20 years of actual price data for any symbol
Automatically detects high-volatility stocks (meme stocks, growth stocks)
Uses median returns for volatile stocks, standard CAGR for stable stocks
Provides conservative estimates when extreme outlier years are detected
Smart fallback to manual percentages when data insufficient
Customizable Performance Dashboard
Educational DCA performance analysis with compound growth calculations
Customizable table sizing (Tiny to Huge text options)
9 positioning options (Top/Middle/Bottom + Left/Center/Right)
Theme-adaptive colors (automatically adjusts to dark/light mode)
Multiple display layout options
Future Projection System
Visual future growth projections
Timeframe-aware calculations (Daily/Weekly/Monthly charts)
1-30 year projection options
Shows projected portfolio value and total investment amounts
Investment Insights
Performance vs benchmark comparison
ROI from initial investment tracking
Monthly average return analysis
Investment milestone alerts (25%, 50%, 100% gains)
Contribution tracking and next milestone indicators
---
📊 Step-by-Step Setup Guide
1. Investment Settings 💰
Initial Investment: Enter your starting lump sum (e.g., $60,000)
Monthly Contribution: Set your regular DCA amount (e.g., $500/month)
Return Calculation: Choose "Auto (Stock History)" for real data or "Manual" for fixed %
Historical Period: Select 3-20 years for auto calculations (default: 10 years)
Start Year: When you began investing (e.g., 2020)
Current Portfolio Value: Your actual portfolio worth today (e.g., $150,000)
2. Display Settings 📊
Table Sizes: Choose from Tiny, Small, Normal, Large, or Huge
Table Positions: 9 options - Top/Middle/Bottom + Left/Center/Right
Visibility Toggles: Show/hide Main Table and Stats Table independently
3. Future Projection 🔮
Enable Projections: Toggle on to see future growth visualization
Projection Years: Set 1-30 years ahead for analysis
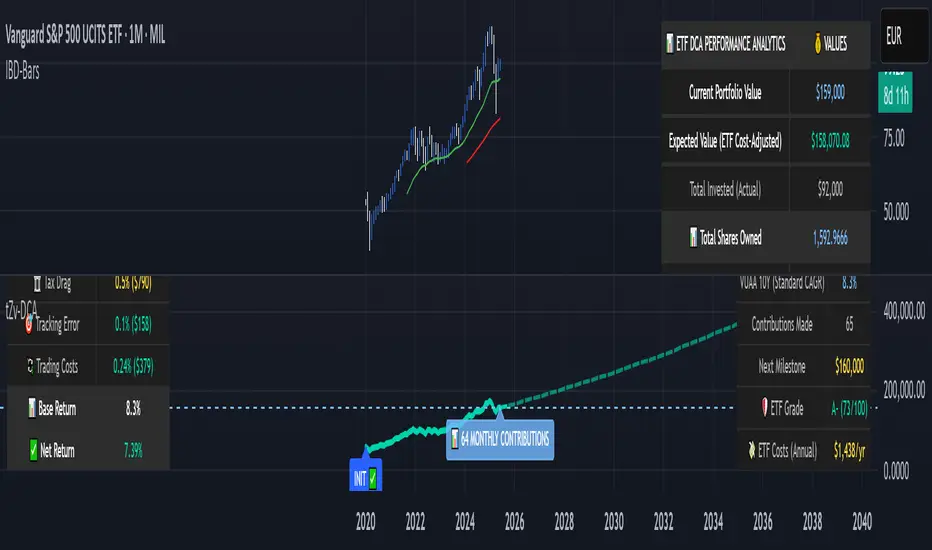
Live Example - NASDAQ:META Analysis:
Settings shown: $60K initial + $500/month + Auto calculation + 10-year history + 2020 start + $150K current value
---
🔬 Pine Script Code Examples
Core DCA Calculations:
// Calculate total invested over time
months_elapsed = (year - start_year) * 12 + month - 1
total_invested = initial_investment + (monthly_contribution * months_elapsed)
// Compound growth formula for initial investment
theoretical_initial_growth = initial_investment * math.pow(1 + annual_return, years_elapsed)
// Future Value of Annuity for monthly contributions
monthly_rate = annual_return / 12
fv_contributions = monthly_contribution * ((math.pow(1 + monthly_rate, months_elapsed) - 1) / monthly_rate)
// Total expected value
theoretical_total = theoretical_initial_growth + fv_contributions
Volatility Detection Logic:
// Detect extreme years for volatility adjustment
extreme_years = 0
for i = 1 to historical_years
yearly_return = ((price_current / price_i_years_ago) - 1) * 100
if yearly_return > 100 or yearly_return < -50
extreme_years += 1
// Use median approach for high volatility stocks
high_volatility = (extreme_years / historical_years) > 0.2
calculated_return = high_volatility ? median_of_returns : standard_cagr
Performance Metrics:
// Calculate key performance indicators
absolute_gain = actual_value - total_invested
total_return_pct = (absolute_gain / total_invested) * 100
roi_initial = ((actual_value - initial_investment) / initial_investment) * 100
cagr = (math.pow(actual_value / initial_investment, 1 / years_elapsed) - 1) * 100
---
📊 Real-World Examples
See the indicator in action across different investment types:
Stable Index Investments:
AMEX:SPY (SPDR S&P 500) - Shows steady compound growth with standard CAGR calculations
Classic DCA success story: $60K initial + $500/month starting 2020. The indicator shows SPY's historical 10%+ returns, demonstrating how consistent broad market investing builds wealth over time. Notice the smooth theoretical growth line vs actual performance tracking.
MIL:VUAA (Vanguard S&P 500 UCITS) - Shows both data limitation and solution approaches
Data limitation example: VUAA shows "Manual (Auto Failed)" and "No Data" when default 10-year historical setting exceeds available data. The indicator gracefully falls back to manual percentage input while maintaining all DCA calculations and projections.
MIL:VUAA (Vanguard S&P 500 UCITS) - European ETF with successful 5-year auto calculation
Solution demonstration: By adjusting historical period to 5 years (matching available data), VUAA auto calculation works perfectly. Shows how users can optimize settings for newer assets. European market exposure with EUR denomination, demonstrating DCA effectiveness across different markets and currencies.
NYSE:BRK.B (Berkshire Hathaway) - Quality value investment with Warren Buffett's proven track record
Value investing approach: Berkshire Hathaway's legendary performance through DCA lens. The indicator demonstrates how quality companies compound wealth over decades. Lower volatility than tech stocks = standard CAGR calculations used.
High-Volatility Growth Stocks:
NASDAQ:NVDA (NVIDIA Corporation) - Demonstrates volatility-adjusted calculations for extreme price swings
High-volatility example: NVIDIA's explosive AI boom creates extreme years that trigger volatility detection. The indicator automatically switches to "Median (High Vol): 50%" calculations for conservative projections, protecting against unrealistic future estimates based on outlier performance periods.
NASDAQ:TSLA (Tesla) - Shows how 10-year analysis can stabilize volatile tech stocks
Stable long-term growth: Despite Tesla's reputation for volatility, the 10-year historical analysis (34.8% CAGR) shows consistent enough performance that volatility detection doesn't trigger. Demonstrates how longer timeframes can smooth out extreme periods for more reliable projections.
NASDAQ:META (Meta Platforms) - Shows stable tech stock analysis using standard CAGR calculations
Tech stock with stable growth: Despite being a tech stock and experiencing the 2022 crash, META's 10-year history shows consistent enough performance (23.98% CAGR) that volatility detection doesn't trigger. The indicator uses standard CAGR calculations, demonstrating how not all tech stocks require conservative median adjustments.
Notice how the indicator automatically detects high-volatility periods and switches to median-based calculations for more conservative projections, while stable investments use standard CAGR methods.
---
📈 Performance Metrics Explained
Current Portfolio Value: Your actual investment worth today
Expected Value: What you should have based on historical returns (Auto) or your target return (Manual)
Total Invested: Your actual money invested (initial + all monthly contributions)
Total Gains/Loss: Absolute dollar difference between current value and total invested
Total Return %: Percentage gain/loss on your total invested amount
ROI from Initial Investment: How your starting lump sum has performed
CAGR: Compound Annual Growth Rate of your initial investment (Note: This shows initial investment performance, not full DCA strategy)
vs Benchmark: How you're performing compared to the expected returns
---
⚠️ Important Notes & Limitations
Data Requirements: Auto mode requires sufficient historical data (minimum 3 years recommended)
CAGR Limitation: CAGR calculation is based on initial investment growth only, not the complete DCA strategy
Projection Accuracy: Future projections are theoretical and based on historical returns - actual results may vary
Timeframe Support: Works ONLY on Daily (1D), Weekly (1W), and Monthly (1M) charts - no other timeframes supported
Update Frequency: Update "Current Portfolio Value" regularly for accurate tracking
---
📚 Educational Use & Disclaimer
This analysis tool can be applied to various stock and ETF charts for educational study of DCA mathematical concepts and historical performance patterns.
Study Examples: Can be used with symbols like AMEX:SPY , NASDAQ:QQQ , AMEX:VTI , NASDAQ:AAPL , NASDAQ:MSFT , NASDAQ:GOOGL , NASDAQ:AMZN , NASDAQ:TSLA , NASDAQ:NVDA for learning purposes.
EDUCATIONAL DISCLAIMER: This indicator is a study tool for analyzing Dollar-Cost Averaging strategies. It does not provide investment advice, trading signals, or guarantees. All calculations are theoretical examples for educational purposes only. Past performance does not predict future results. Users should conduct their own research and consult qualified financial professionals before making any investment decisions.
---
© 2025 TradeVizion. All rights reserved.
Previous Two Days HL + Asia H/L + 4H Vertical Lines📊 Indicator Overview
This custom TradingView indicator visually marks key market structure levels and session data on your chart using lines, labels, boxes, and vertical guides. It is designed for traders who analyze intraday and multi-session behavior — especially around the New York and Asia sessions — with a focus on 4-hour price ranges.
🔍 What the Indicator Tracks
1. Previous Two Days' Ranges (6PM–5PM NY Time)
PDH/PDL (Day 1 & Day 2): Draws horizontal lines marking the previous two trading days’ highs and lows.
Midlines: Calculates and displays the midpoint between each day’s high and low.
Color-Coded: Uses strong colors for Day 1 and more transparent versions for Day 2, to help differentiate them.
2. Asia Session High/Low (6 PM – 2 AM NY Time)
Automatically tracks the high and low during the Asia session.
Extends these levels until the following day’s NY close (4 PM).
Shows a midline of the Asia session (optional dotted line).
Highlights the Asia session background in gray.
Labels Asia High and Low on the chart for easy reference.
3. Last Closed 4-Hour Candle Range
At the start of every new 4H candle, it:
Draws a box from the last closed 4H candle.
Box spans horizontally across a set number of bars (adjustable).
Top and bottom lines indicate the high and low of that 4H candle.
Midline, 25% (Q1) and 75% (Q3) levels are also drawn inside the box using dotted lines.
Helps traders identify premium/discount zones within the previous 4H range.
4. Vertical 4H Time Markers
Draws vertical dashed lines to mark the start and end of the last 4H candle range.
Based on the standard 4H bar timing in NY (e.g. 5:00, 9:00, 13:00, 17:00).
⚙️ Inputs & Options
Line thickness, color customization for all levels.
Option to place labels on the right or left side of the chart.
Toggle for enabling/disabling the 4H box.
Adjustable box extension length (how far to extend the range visually).
✅ Ideal Use Cases
Identifying reaction zones from prior highs/lows.
Spotting reversals during Asia or NY session opens.
Trading intraday setups based on 4H structure.
Anchoring scalping or swing entries off major session levels.

Session Status Table📌 Session Status Table
Session Status Table is an indicator that displays the real-time status of the four major trading sessions:
* 🇯🇵 Asia (Tokyo)
* 🇬🇧 London
* 🇺🇸 New York AM
* 🇺🇸 New York PM
It shows which sessions are currently open, how much time remains until they open or close, and optionally sends alerts in advance.
🧩 Features:
* Real-time session table — shows the status of each session on the chart.
* Color-coded statuses:
* 🟢 Green – Session is open
* 🔴 Red – Session is closed
* ⚪ Gray – Weekend
* Countdown timers until session open or close.
* User alerts — receive a notification a custom number of minutes before a session starts.
⚙️ Customization:
* Table position — fully configurable.
* Session colors — customizable for open, closed, and weekend states.
* Session labels — customizable with icons.
* Notifications:
* Enabled through TradingView's Alerts panel.
* User-defined lead time before session opens.
🕒 Time Zones:
All times are calculated in UTC to ensure consistency across different markets and regions, avoiding discrepancies from time zones and daylight saving time.
🚨 How to enable alerts:
1. Open the "Alerts" panel in TradingView.
2. Click "Create Alert".
3. In the condition dropdown, choose "Session Status Table".
4. Set to any alert() trigger.
5. Save — you'll be notified a set number of minutes before each session begins.
ℹ️ Technical Notes:
* Built with Pine Script version 6.
* Logically divided into clear sections: inputs, session calculations, table rendering, and alerts.
* Optimized for performance and reliability on all timeframes.
Ideal for traders who use session activity in their strategies — especially in Forex, crypto, and futures markets.
QG-Particle OscillatorThis is an advanced oscillator based on auxiliary particle filter. It separates signal from noise and uses smoothing algorithm similar to JMA.
The main oscillator line is a smoothed and detrended version of the price series similar to detrended oscillator line. The purple/aqua lines are a prediction based on an additional adaptive smoothing technique and current volatility.
The prediction is smoothed twice and is supposed to represent the true signal without any noise, thus the prediction should always be less than the raw detrend line. However, certain volatile conditions will cause the prediction to cross above/below the detrend line. When this happens the likelihood of a reversal or pullback is extremely high.
There are 3 dots on the zero line- Red, Green and Yellow. The yellow dots warn of an eminent pullback 2 bars before it actually occurs. This is a non-repainting indicator.
One can also use this indicator to trade CCI signals, similar to zero line rejection in existing trend.
The indicator has 2 settings- Period and Phase. The phase represents cycle phase and Period represents oscillator period.
Credits: This indicator has been originally published for Ninjatrader and this is conversion into pinescript.

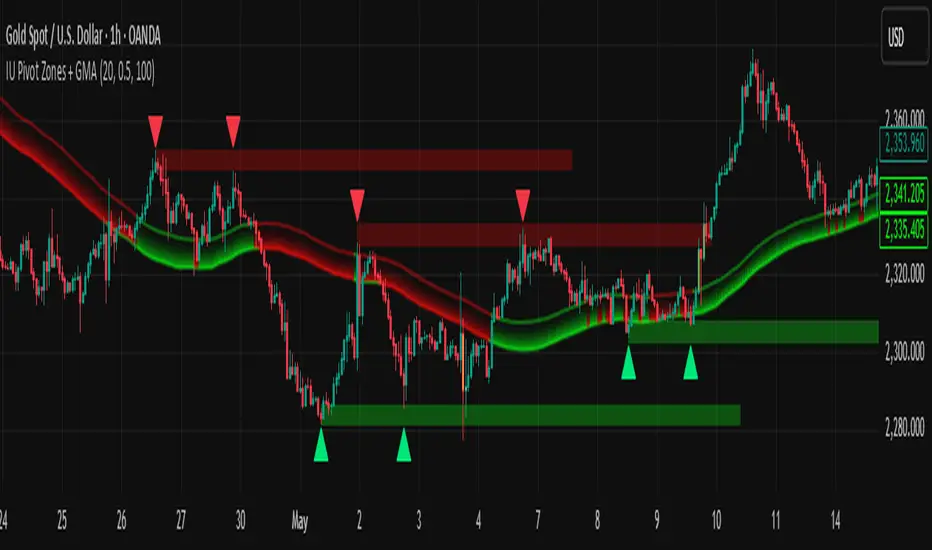
IU Pivot Zones + GMADESCRIPTION:
IU Pivot Zones + GMA is a smart price-action-based indicator that detects meaningful support and resistance zones formed through pivot highs/lows while combining them with dynamic zone generation and Geometric Moving Averages (GMA). This tool is built to help traders visualize institutional breakout/rejection zones with clear, logical mapping and live box management — helping you stay ahead of the move.
The indicator is designed for intraday, swing, and positional traders who want to enhance their trading decisions with visual confluence zones and market structure logic.
USER INPUTS
* Pivot point Lengths: Number of bars used to detect pivot highs/lows
* Zone length: Controls the thickness of the support/resistance zone; higher values create wider zones
* GMA Length: Period for calculating the geometric moving averages based on highs and lows
* Allow Bar/candle Color: Enables or disables special candle coloring when price interacts with the zones
LOGIC OF THE INDICATOR:
* Detects pivot highs and pivot lows using the user-defined length
* Compares consecutive pivot levels to determine if they fall within a valid ATR-based price band to form a zone
* If confirmed, the indicator dynamically plots a resistance or support box between those pivot points, colored respectively (red for resistance, green for support)
* The boxes update in real-time based on price action. If price respects the zone, the box extends forward. If price breaks the zone, the box disappears
* Geometric Moving Averages (GMA) based on logarithmic mean of highs and lows are plotted to offer a trend bias
* Candles that touch the top of the support zone are colored yellow, and those touching the bottom of the resistance zone are orange, enhancing zone reaction visibility
WHY IT IS UNIQUE:
* Uses logarithmic-based GMAs, which are smoother and less reactive than traditional moving averages
* ATR-based zone logic makes it adaptive to volatility instead of using fixed-width zones
* Combines structural levels (pivots), volatility filters (ATR), and trend overlays (GMA) in one unified tool
* Real-time zone extension and disappearance logic based on price interaction
HOW USER CAN BENEFIT FROM IT:
* Spot high-probability breakout or reversal zones that price respects consistently
* Use the GMA cloud for trend confirmation — for example, bullish bias when price is above both GMAs
* Build price action strategies around zone touches, breakouts, or rejections
* Use color-coded candles as real-time alerts for potential entry/exit signals near S/R levels
* Save time by avoiding manual marking of zones on charts across timeframes
DISCLAIMER:
This indicator is created for educational and informational purposes only. It does not constitute financial advice or a recommendation to buy or sell any asset. All trading involves risk, and users should conduct their own analysis or consult with a qualified financial advisor before making any trading decisions. The creator is not responsible for any losses incurred through the use of this tool. Use at your own discretion.
Last Week's APM & Daily % Move(Corrected)Last Week's Average Price Movement + Daily Percentage Move (based on NY time)
This indicator accurately displays last week's Average Pip Movement (APM) consistently across all timeframes and tracks the true daily percentage move relative to that APM in a clear table in the top-right corner.
Key Features:
-Consistent Last Week's APM: Calculates the average pip movement from Monday to Friday of the previous trading week (based on daily wick-to-wick ranges, divided by 5). This APM value is now stable and the same across all chart timeframes.
-Accurate Live Daily % Move: Tracks the maximum percentage the price has moved (either up or down) since the 5 PM New York time daily open, compared to last week's APM. The percentage holds the maximum value reached during the day and resets at the next 5 PM NY open.
-NY Time Alignment: All time-based calculations are aligned with the New York time zone
Pip Adjustment: Automatically adjusts for JPY pairs.
⚠️ Important: For the intended display and relevance of the daily percentage move, this indicator is best used on timeframes 4-hour and under. On Daily and Weekly timeframes, the APM display will show a message indicating this.
We hope this indicator enhances your trading analysis.

COT-Index-NocTradingCOT Index Indicator
The COT Index Indicator is a powerful tool designed to visualize the Commitment of Traders (COT) data and offer insights into market sentiment. The COT Index is a measurement of the relative positioning of commercial traders versus non-commercial and retail traders in the futures market. It is widely used to identify potential market reversals by observing the extremes in trader positioning.
Customizable Timeframe: The indicator allows you to choose a custom time interval (in months) to visualize the COT data, making it flexible to fit different trading styles and strategies.
How to Use:
Visualize Market Sentiment: A COT Index near extremes (close to 0 or 100) can indicate potential turning points in the market, as it reflects extreme positioning of different market participant groups.
Adjust the Time Interval: The ability to adjust the time interval (in months) gives traders the flexibility to analyze the market over different periods, which can be useful in detecting longer-term trends or short-term shifts in sentiment.
Combine with Other Indicators: To enhance your analysis, combine the COT Index with your technical analysis.
This tool can serve as an invaluable addition to your trading strategy, providing a deeper understanding of the market dynamics and the positioning of major market participants.
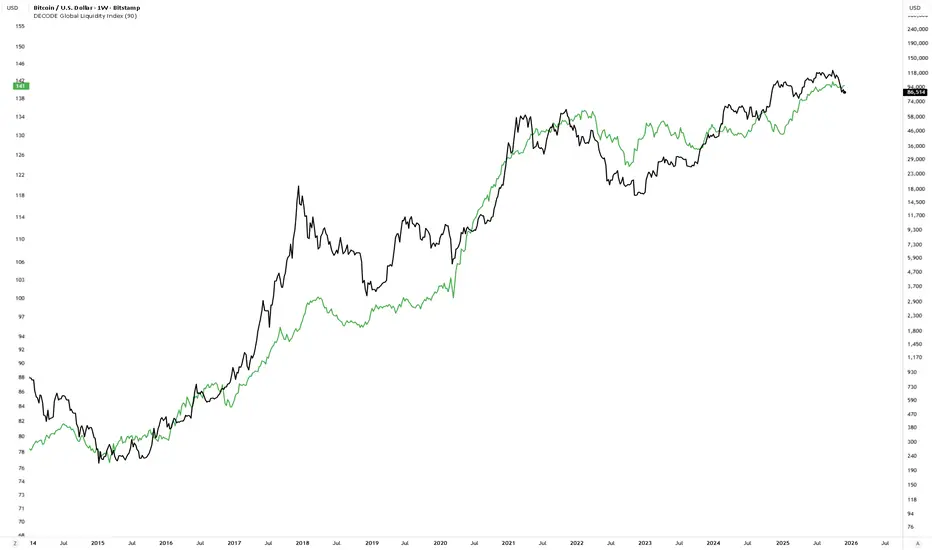
DECODE Global Liquidity IndexDECODE Global Liquidity Index 🌊
The DECODE Global Liquidity Index is a powerful tool designed to track and aggregate global liquidity by combining data from the world's 13 largest economies. It offers a comprehensive view of financial liquidity, providing crucial insights into the underlying currents that can influence asset prices and market trends.
The economies covered are: United States, China, European Union, Japan, India, United Kingdom, Brazil, Canada, Russia, South Korea, Australia, Mexico, and Indonesia. The European Union accounts for major individual economies within the EU like Germany, France, Italy, Spain, Netherlands, Poland, etc.
Key Features:
1. Customizable Liquidity Sources
Include Global M2: You can opt to include the M2 money supply from the 13 listed economies. M2 is a broad measure of money supply that includes cash, checking deposits, savings deposits, money market securities, mutual funds, and other time deposits. (Note: Australia uses M3 as its primary measure, which is included when M2 is selected for Australia).
Include Central Bank Balance Sheets (CBBS): Alternatively, or in addition, you can include the total assets held by the central banks of these economies. Central bank balance sheets expand or contract based on monetary policy operations like quantitative easing (QE) or tightening (QT).
Combined View: If you select both M2 and CBBS, and data is available for both, the indicator will display an average of the two aggregated values. If only one source type is selected, or if data for one type is unavailable despite both being selected, the indicator will display the single available and selected component. This provides flexibility in how you define and analyze global liquidity.
2. Lead/Lag Analysis (Forward Projection):
Lead Offset (Days): This feature allows you to project the liquidity index forward by a specified number of days.
Why it's useful: Global liquidity changes can often be a leading indicator for various asset classes, particularly those sensitive to risk appetite, like Bitcoin or growth stocks. These assets might lag shifts in liquidity. By applying a lead (e.g., 90 days), you can shift the liquidity data forward on your chart to more easily visualize potential correlations and identify if current asset price movements might be responding to past changes in liquidity.
3. Rate of Change (RoC) Oscillator:
Year-over-Year % View: Instead of viewing aggregate liquidity, you can switch to a Year-over-Year (YoY%) Rate of Change (ROC) oscillator.
Why it's useful:
Momentum Identification: The ROC highlights the speed and direction of liquidity changes. Positive values indicate liquidity is increasing compared to a year ago, while negative values show it's decreasing.
Turning Points: Oscillators make it easier to spot potential accelerations, decelerations, or reversals in liquidity trends. A cross above the zero line can signal strengthening liquidity momentum, while a cross below can signal weakening momentum.
Cycle Analysis: It helps in assessing the cyclical nature of liquidity provision and its potential impact on market cycles.
This indicator aims to provide a clear, customizable, and insightful measure of global liquidity to aid traders and investors in their market analysis.
Momentum Fusion v1Momentum Fusion v1
Overview
Momentum Fusion v1 (MFusion) is a multi-oscillator indicator that combines several components to analyze market momentum and trend strength. It incorporates modified versions of classic indicators such as PVI (Positive Volume Index), NVI (Negative Volume Index), MFI (Money Flow Index), RSI, Stochastic, and Bollinger Bands Oscillator. The indicator displays a histogram that changes color based on momentum strength and includes "FUSION🔥" signal labels when extreme values are reached.
Indicator Settings
Parameters:
EMA Length – Smoothing period for the moving average (default: 255).
Smoothing Period – Internal calculation smoothing parameter (default: 15).
BB Multiplier – Standard deviation multiplier for Bollinger Bands (default: 2.0).
Show verde / marron / media lines – Toggles the display of auxiliary lines.
Show FUSION🔥 label – Enables/disables signal labels.
Indicator Components
1. PVI (Positive Volume Index)
Formula:
pvi := volume > volume ? nz(pvi ) + (close - close ) / close * sval : nz(pvi )
Description:
PVI increases when volume rises compared to the previous bar and accounts for price percentage change. The stronger the price movement with increasing volume, the higher the PVI value.
2. NVI (Negative Volume Index)
Formula:
nvi := volume < volume ? nz(nvi ) + (close - close ) / close * sval : nz(nvi )
Description:
NVI tracks price movements during declining volume. If the price rises on low volume, it may indicate a "stealth" trend.
3. Money Flow Index (MFI)
Formula:
100 - 100 / (1 + up / dn)
Description:
An oscillator measuring money flow strength. Values above 80 suggest overbought conditions, while values below 20 indicate oversold conditions.
4. Stochastic Oscillator
Formula:
k = 100 * (close - lowest(low, length)) / (highest(high, length) - lowest(low, length))
Description:
A classic stochastic oscillator showing price position relative to the selected period's range.
5. Bollinger Bands Oscillator
Formula:
(tprice - BB midline) / (upper BB - lower BB) * 100
Description:
Indicates the price position relative to Bollinger Bands in percentage terms.
Key Lines & Histogram
1. Verde (Green Line)
Calculation:
verde = marron + oscp (normalized PVI)
Interpretation:
Higher values indicate stronger bullish momentum. A FUSION🔥 signal appears when the value reaches 750+.
2. Marron (Brown Line)
Calculation:
marron = (RSI + MFI + Bollinger Osc + Stochastic / 3) / 2
Interpretation:
A composite oscillator combining multiple indicators. Higher values suggest overbought conditions.
3. Media (Red Line)
Calculation:
media = EMA of marron with smoothing period
Interpretation:
Acts as a signal line for trend confirmation.
4. Histogram
Calculation:
histo = verde - marron
Colors:
Bright green (>100) – Strong bullish momentum.
Light green (>0) – Moderate bullish momentum.
Orange (<0) – Bearish momentum.
Red (<-100) – Strong bearish momentum.
Signals & Alerts
1. FUSION🔥 (Strong Momentum)
Condition:
verde >= 750
Visualization:
A "FUSION🔥" label appears below the chart.
Alert:
Can be set to trigger notifications when the condition is met.
2. Background Aura
Condition:
verde > 850
Visualization:
The chart background turns teal, indicating extreme momentum.
Usage Recommendations
FUSION🔥 Signal – Can be used as a long entry point when confirmed by other indicators.
Histogram:
1. Green bars – Potential long entry.
2. Red/orange bars – Potential short entry.
3. Media & Marron Crossover – Can serve as an additional trend filter.
4. Suitable for a 5-15 minute time frame
Conclusion
Momentum Fusion v1 is a powerful tool for momentum analysis, combining multiple indicators into a unified system. It is suitable for:
Trend traders (catching strong movements).
Scalpers (identifying short-term impulses).
Swing traders (filtering entry points).
The indicator features customizable settings and visual signals, making it adaptable to various trading styles.

MTF - Quantum Fibonacci ATR/ADR Levels & Targets V_2.0# Quantum Fibonacci Wave Mechanics v2.0 Release Notes
## 🚀 New Features
- Added multi-timeframe alert system for buy/sell signals
- Implemented dynamic label management with price values
- New mid-level trigger option for additional signals
- New EMA trigger option for confirmation signals
- Signal bar highlighting option
- Customizable line widths for all levels
## 🎨 Visual Improvements
- Completely redesigned label system (left-aligned with offsets)
- More intuitive input organization
- Better color customization options
## ⚙️ Technical Upgrades
- Upgraded to Pine Script v6
- Reduced repainting with stricter confirmation checks
- Optimized performance with proper variable initialization
## ⚠️ Note for Existing Users
- Some color parameters have been renamed
- Label positioning has changed (now with configurable offset)
- Review new mid-level trigger option in strategy settings
## 🐛 Bug Fixes
- Fixed potential repainting issues in signal generation
- Improved label cleanup between periods
- More robust security function implementation
## ⚠️ Caution for Mid-Level & EMA Signals
- Mid-Level Reversals may trigger premature entries in ranging markets.
- EMA crossovers can lag; confirm with price action.
