STD-Adaptive T3 Channel w/ Ehlers Swiss Army Knife Mod. [Loxx]STD-Adaptive T3 Channel w/ Ehlers Swiss Army Knife Mod. is an adaptive T3 indicator using standard deviation adaptivity and Ehlers Swiss Army Knife indicator to adjust the alpha value of the T3 calculation. This helps identify trends and reduce noise. In addition. I've included a Keltner Channel to show reversal/exhaustion zones.
What is the Swiss Army Knife Indicator?
John Ehlers explains the calculation here: www.mesasoftware.com
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included:
Bar coloring
Signals
Alerts
Loxx's Expanded Source Types
스크립트에서 "technical"에 대해 찾기
T3 Velocity [Loxx]T3 Velocity is a simple velocity indicator using T3 moving average that uses gradient colors to better identify trends.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included:
Bar coloring
Signals
Alerts
Loxx's Expanded Source Types

R-squared Adaptive T3 w/ DSL [Loxx]R-squared Adaptive T3 w/ DSL is the following T3 indicator but with Discontinued Signal Lines added to reduce noise and thereby increase signal accuracy. This adaptation makes this indicator lower TF scalp friendly.
What is R-squared Adaptive?
One tool available in forecasting the trendiness of the breakout is the coefficient of determination ( R-squared ), a statistical measurement.
The R-squared indicates linear strength between the security's price (the Y - axis) and time (the X - axis). The R-squared is the percentage of squared error that the linear regression can eliminate if it were used as the predictor instead of the mean value. If the R-squared were 0.99, then the linear regression would eliminate 99% of the error for prediction versus predicting closing prices using a simple moving average .
R-squared is used here to derive a T3 factor used to modify price before passing price through a six-pole non-linear Kalman filter.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included:
Bar coloring
Signals
Alerts
EMA and FEMA Signla/DSL smoothing
Loxx's Expanded Source Types
STD-Filterd, R-squared Adaptive T3 w/ Dynamic Zones [Loxx]STD-Filterd, R-squared Adaptive T3 w/ Dynamic Zones is a standard deviation filtered R-squared Adaptive T3 moving average with dynamic zones.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
What is R-squared Adaptive?
One tool available in forecasting the trendiness of the breakout is the coefficient of determination ( R-squared ), a statistical measurement.
The R-squared indicates linear strength between the security's price (the Y - axis) and time (the X - axis). The R-squared is the percentage of squared error that the linear regression can eliminate if it were used as the predictor instead of the mean value. If the R-squared were 0.99, then the linear regression would eliminate 99% of the error for prediction versus predicting closing prices using a simple moving average .
R-squared is used here to derive a T3 factor used to modify price before passing price through a six-pole non-linear Kalman filter.
What are Dynamic Zones?
As explained in "Stocks & Commodities V15:7 (306-310): Dynamic Zones by Leo Zamansky, Ph .D., and David Stendahl"
Most indicators use a fixed zone for buy and sell signals. Here’ s a concept based on zones that are responsive to past levels of the indicator.
One approach to active investing employs the use of oscillators to exploit tradable market trends. This investing style follows a very simple form of logic: Enter the market only when an oscillator has moved far above or below traditional trading lev- els. However, these oscillator- driven systems lack the ability to evolve with the market because they use fixed buy and sell zones. Traders typically use one set of buy and sell zones for a bull market and substantially different zones for a bear market. And therein lies the problem.
Once traders begin introducing their market opinions into trading equations, by changing the zones, they negate the system’s mechanical nature. The objective is to have a system automatically define its own buy and sell zones and thereby profitably trade in any market — bull or bear. Dynamic zones offer a solution to the problem of fixed buy and sell zones for any oscillator-driven system.
An indicator’s extreme levels can be quantified using statistical methods. These extreme levels are calculated for a certain period and serve as the buy and sell zones for a trading system. The repetition of this statistical process for every value of the indicator creates values that become the dynamic zones. The zones are calculated in such a way that the probability of the indicator value rising above, or falling below, the dynamic zones is equal to a given probability input set by the trader.
To better understand dynamic zones, let's first describe them mathematically and then explain their use. The dynamic zones definition:
Find V such that:
For dynamic zone buy: P{X <= V}=P1
For dynamic zone sell: P{X >= V}=P2
where P1 and P2 are the probabilities set by the trader, X is the value of the indicator for the selected period and V represents the value of the dynamic zone.
The probability input P1 and P2 can be adjusted by the trader to encompass as much or as little data as the trader would like. The smaller the probability, the fewer data values above and below the dynamic zones. This translates into a wider range between the buy and sell zones. If a 10% probability is used for P1 and P2, only those data values that make up the top 10% and bottom 10% for an indicator are used in the construction of the zones. Of the values, 80% will fall between the two extreme levels. Because dynamic zone levels are penetrated so infrequently, when this happens, traders know that the market has truly moved into overbought or oversold territory.
Calculating the Dynamic Zones
The algorithm for the dynamic zones is a series of steps. First, decide the value of the lookback period t. Next, decide the value of the probability Pbuy for buy zone and value of the probability Psell for the sell zone.
For i=1, to the last lookback period, build the distribution f(x) of the price during the lookback period i. Then find the value Vi1 such that the probability of the price less than or equal to Vi1 during the lookback period i is equal to Pbuy. Find the value Vi2 such that the probability of the price greater or equal to Vi2 during the lookback period i is equal to Psell. The sequence of Vi1 for all periods gives the buy zone. The sequence of Vi2 for all periods gives the sell zone.
In the algorithm description, we have: Build the distribution f(x) of the price during the lookback period i. The distribution here is empirical namely, how many times a given value of x appeared during the lookback period. The problem is to find such x that the probability of a price being greater or equal to x will be equal to a probability selected by the user. Probability is the area under the distribution curve. The task is to find such value of x that the area under the distribution curve to the right of x will be equal to the probability selected by the user. That x is the dynamic zone.
Included:
Bar coloring
Signals
Alerts
Loxx's Expanded Source Types

Pips-Stepped, R-squared Adaptive T3 [Loxx]Pips-Stepped, R-squared Adaptive T3 is a a T3 moving average with optional adaptivity, trend following, and pip-stepping. This indicator also uses optional flat coloring to determine chops zones. This indicator is R-squared adaptive. This is also an experimental indicator.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
What is R-squared Adaptive?
One tool available in forecasting the trendiness of the breakout is the coefficient of determination (R-squared), a statistical measurement.
The R-squared indicates linear strength between the security's price (the Y - axis) and time (the X - axis). The R-squared is the percentage of squared error that the linear regression can eliminate if it were used as the predictor instead of the mean value. If the R-squared were 0.99, then the linear regression would eliminate 99% of the error for prediction versus predicting closing prices using a simple moving average.
R-squared is used here to derive a T3 factor used to modify price before passing price through a six-pole non-linear Kalman filter.
Included:
Bar coloring
Signals
Alerts
Flat coloring
R-squared Adaptive T3 [Loxx]R-squared Adaptive T3 is an R-squared adaptive version of Tilson's T3 moving average. This adaptivity was originally proposed by mladen on various forex forums. This is considered experimental but shows how to use r-squared adapting methods to moving averages. In theory, the T3 is a six-pole non-linear Kalman filter.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis. Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD, Momentum, Relative Strength Index) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA (simple moving average) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA(n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA.
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE/2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE/2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE/2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA, popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE/2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA(3) has lag 1, and EMA(11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA(3) through itself 5 times than if I just take EMA(11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA(3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA(7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA(n) = EMA(n) + EMA(time series - EMA(n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA. The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA(n) + EMA(time series - EMA(n))*.7;
This is algebraically the same as:
EMA(n)*1.7-EMA(EMA(n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD(n,v) = EMA(n)*(1+v)-EMA(EMA(n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA, and when v=1, GD is DEMA. In between, GD is a cooler DEMA. By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD(GD(GD(n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA(n)) to correct themselves. In Technical Analysis, these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included:
Bar coloring
Signals
Alerts
Loxx's Expanded Source Types
God Number Channel v2(GNC v2)GNC got a little update:
1) Logic changed a bit.
I tried to calculate MAs based on the power(high - low of previous bars).You can see it the M-variables, as new statements were added in calculation section of MAs. I don't really know if I did right, because I didn't go too much in Pine Script. I just wanted to make a Bollinger-bands-like bands, which could predict the levels at which might reverse, using legendary fibonacci and Tesla's harmonic number 432. It's might sound as a joke, but as you can see, it works pretty good.
2) Customization :
No need to change Fibonacci ratios in code. Now you can do it in the GNC settings. Also MAs' names were made obvious, just check it out. Time of million similar "MA n1" has passed :)
3) Trade-entry advices :
I didn't tell you exactly the trade-entry advices, as I haven't explored this script fully yet :) But you probably understood something intuitively, when added GNC on the chart. Now I made things way more obvious:
1. Zones between Fib ratios show you how aware you should be of price movements. Basically, here are the rules, but you probably understand them already:
1.1 Red zone(RZ) : high awareness, very likly for price to be reversed, but if there is a clear trend and you know, than it might be a time for price to shoot up/down.
1.2 Orange zone(OZ) : medium awareness, not so obvious, as price might go between boundaries of OZ and continue the trend movement if such followed before entering the OZ. If price go below lower boundary of OZ and the next bar opens below this boundary, it might be a signal for SHORY, BUT(!) please consider confirmation of any sort to be more sure. Think of going beyond the upper boundary by analogy.
1.3 Green Zone(GZ) : if the price hits any boundary of green zone, it is usually a good oppurtunity to open a position against the movement(hit lower boundary -> open LONG, hit upper boundary -> open SHORT).
1.4 Middle Zone(Harmonic Zone)(MZ) : same rules from Green Zone.
IMPORTANT RECCOMENDATION : Use trend indicator to trend all signals from zones to follow the trend, 'cause counter-trending with this thing without stop loss might very quickly wipe you out , might if you will counter-trend strategy with GNC, I will be glad if you share it with the community :)
Reccomendation for better entries :
1) if the price hits the lower(or high) boundaries(LB or HB) zone after zone(hit LB or HB of RZ, then of OZ, then of GZ), it is a very good signal to either LONG, if price was hitting LBs , or SHORT, if hitting HBs .
2) Consider NOT to place trades when in MZ, as price in this zone gets tricky often enough. By the way, if you dont the see the harmonic MAs(which go with plot(ma1+(0.432*avg1)) ), then set the transparency of zone to 20% or a bit more and then it will be ok.
I will continue to develop the GNC and any help or feedback from you, guys, will be very helpful for me, so you welcome for any of those, but please be precise in your critics.
Thank you for using my stuff, hope you found it usefull. Good luck :)

Autodrawn Pivot Levels IndicatorAn experiment with pinescript's line.new() function. The Autodrawn Pivot Levels indicator draws horizontal lines in areas where prices have been flat, which serve as pivot points. This can be useful for pivot trading as it visually shows several critical levels
FATL, SATL, RFTL, & RSTL Digital Signal Filter Smoother [Loxx]FATL, SATL, RFTL, & RSTL Digital Signal Filter (DSP) Smoother is is a baseline indicator with DSP processed source inputs
What are digital indicators: distinctions from standard tools, types of filters.
To date, dozens of technical analysis indicators have been developed: trend instruments, oscillators, etc. Most of them use the method of averaging historical data, which is considered crude. But there is another group of tools - digital indicators developed on the basis of mathematical methods of spectral analysis. Their formula allows the trader to filter price noise accurately and exclude occasional surges, making the forecast more effective in comparison with conventional indicators. In this review, you will learn about their distinctions, advantages, types of digital indicators and examples of strategies based on them.
Two non-standard strategies based on digital indicators
Basic technical analysis indicators built into most platforms are based on mathematical formulas. These formulas are a reflection of market behavior in past periods. In other words, these indicators are built based on patterns that were discovered as a result of statistical analysis, which allows one to predict further trend movement to some extent. But there is also a group of indicators called digital indicators. They are developed using mathematical analysis and are an algorithmic spectral system called ATCF (Adaptive Trend & Cycles Following). In this article, I will tell you more about the components of this system, describe the differences between digital and regular indicators, and give examples of 2 strategies with indicator templates.
ATCF - Market Spectrum Analysis Method
There is a theory according to which the market is chaotic and unpredictable, i.e. it cannot be accurately analyzed. After all, no one can tell how traders will react to certain news, or whether some large investor will want to play against the market like George Soros did with the Bank of England. But there is another theory: many general market trends are logical, and have a rationale, causes and effects. The economy is undulating, which means it can be described by mathematical methods.
Digital indicators are defined as a group of algorithms for assessing the market situation, which are based exclusively on mathematical methods. They differ from standard indicators by the form of analysis display. They display certain values: price, smoothed price, volumes. Many standard indicators are built on the basis of filtering the minute significant price fluctuations with the help of moving averages and their variations. But we can hardly call the MA a good filter, because digital indicators that use spectral filters make it possible to do a more accurate calculation.
Simply put, digital indicators are technical analysis tools in which spectral filters are used to filter out price noise instead of moving averages.
The display of traditional indicators is lines, areas, and channels. Digital indicators can be displayed both in the form of lines and in digital form (a set of numbers in columns, any data in a text field, etc.). The digital display of the data is more like an additional source of statistics; for trading, a standard visual linear chart view is used.
All digital models belong to the category of spectral analysis of the market situation. In conventional technical indicators, price indications are averaged over a fixed period of time, which gives a rather rough result. The use of spectral analysis allows us to increase trading efficiency due to the fact that digital indicators use a statistical data set of past periods, which is converted into a “frequency” of the market (period of fluctuations).
Fourier theory provides the following spectral ranging of the trend duration:
low frequency range (0-4) - a reflection of a long trend of 2 months or more
medium frequency range (5-40) - the trend lasts 10-60 days, thus it is referred to as a correction
high frequency range (41-130) - price noise that lasts for several days
The ATCF algorithm is built on the basis of spectral analysis and includes a set of indicators created using digital filters. Its consists of indicators and filters:
FATL: Built on the basis of a low-frequency digital trend filter
SATL: Built on the basis of a low-frequency digital trend filter of a different order
RFTL: High frequency trend line
RSTL: Low frequency trend line
Inclucded:
4 DSP filters
Bar coloring
Keltner channels with variety ranges and smoothing functions
Bollinger bands
40 Smoothing filters
33 souce types
Variable channels

APA-Adaptive, Ehlers Early Onset Trend [Loxx]APA-Adaptive, Ehlers Early Onset Trend is Ehlers Early Onset Trend but with Autocorrelation Periodogram Algorithm dominant cycle period input.
What is Ehlers Early Onset Trend?
The Onset Trend Detector study is a trend analyzing technical indicator developed by John F. Ehlers , based on a non-linear quotient transform. Two of Mr. Ehlers' previous studies, the Super Smoother Filter and the Roofing Filter, were used and expanded to create this new complex technical indicator. Being a trend-following analysis technique, its main purpose is to address the problem of lag that is common among moving average type indicators.
The Onset Trend Detector first applies the EhlersRoofingFilter to the input data in order to eliminate cyclic components with periods longer than, for example, 100 bars (default value, customizable via input parameters) as those are considered spectral dilation. Filtered data is then subjected to re-filtering by the Super Smoother Filter so that the noise (cyclic components with low length) is reduced to minimum. The period of 10 bars is a default maximum value for a wave cycle to be considered noise; it can be customized via input parameters as well. Once the data is cleared of both noise and spectral dilation, the filter processes it with the automatic gain control algorithm which is widely used in digital signal processing. This algorithm registers the most recent peak value and normalizes it; the normalized value slowly decays until the next peak swing. The ratio of previously filtered value to the corresponding peak value is then quotiently transformed to provide the resulting oscillator. The quotient transform is controlled by the K coefficient: its allowed values are in the range from -1 to +1. K values close to 1 leave the ratio almost untouched, those close to -1 will translate it to around the additive inverse, and those close to zero will collapse small values of the ratio while keeping the higher values high.
Indicator values around 1 signify uptrend and those around -1, downtrend.
What is an adaptive cycle, and what is Ehlers Autocorrelation Periodogram Algorithm?
From his Ehlers' book Cycle Analytics for Traders Advanced Technical Trading Concepts by John F. Ehlers , 2013, page 135:
"Adaptive filters can have several different meanings. For example, Perry Kaufman’s adaptive moving average ( KAMA ) and Tushar Chande’s variable index dynamic average ( VIDYA ) adapt to changes in volatility . By definition, these filters are reactive to price changes, and therefore they close the barn door after the horse is gone.The adaptive filters discussed in this chapter are the familiar Stochastic , relative strength index ( RSI ), commodity channel index ( CCI ), and band-pass filter.The key parameter in each case is the look-back period used to calculate the indicator. This look-back period is commonly a fixed value. However, since the measured cycle period is changing, it makes sense to adapt these indicators to the measured cycle period. When tradable market cycles are observed, they tend to persist for a short while.Therefore, by tuning the indicators to the measure cycle period they are optimized for current conditions and can even have predictive characteristics.
The dominant cycle period is measured using the Autocorrelation Periodogram Algorithm. That dominant cycle dynamically sets the look-back period for the indicators. I employ my own streamlined computation for the indicators that provide smoother and easier to interpret outputs than traditional methods. Further, the indicator codes have been modified to remove the effects of spectral dilation.This basically creates a whole new set of indicators for your trading arsenal."

Parabolic SAR with the ADX overlayThe following indicator and chart pattern is based on a twist from Welles Wilder's parabolic stop and reverse . This is a trend following system which is essentially a dynamic trailing stop loss for longs and shorts. The system is often criticized for it's poor performance in choppy rangebound markets so people often combine it with other signals that attempt to identify a "trend" the ADX is a popular indicator with three indicators, the DI+ "Positive Directional Indicator" the DI- "Negative Directional Indicator" and then a combination of the two, the ADX "Average Directional Indicator". Generally speaking, if the DI+ is above the DI- and the ADX is greater than 25 then we are in a positive trending market. If the DI+ is less than the DI- and the ADX is greater than 25 then we are in a negative trending market. If the ADX is less than 25 then there is no trend in place and we are in a range bound "choppy market".
So, I created this chart to show when the ADX is > 25 (or you can enter your own number) and the DI+ is > DI- then the background will be green. Vice versa, when the ADX is >25 and the DI+ is < DI- then we are in a negative trending market and the background color will be red. If the ADX is < 25 (or whatever you choose) then we are in a choppy 'range-bound" market.
Regarding the ParSAR. Pay attention to the "+" marks. they indicate whether we are bullish or bearish. When we cross through a + then we revert to the opposite. "Stop And Reverse". They are a simple calculation of a starting percentage, an incremental increase in that percentage, and a max percentage increase. If you want your system to trade less, decrease the "maximum" If you want it to trade more, increase the maximum.
Tinker around with these and you might find a healthy strategy you can trade on.
If you add Take Profit Targets and Stop Loss Targets, this is an even more productive strategy. Try it out on BINANCE:ETHUSDT with a 2hr time horizon and 0.02, 0.023, 0.2.

Object: object oriented programming made possible! Hash map's in Pinescript?? Absolutely
This Library is the first step towards bringing a much needed data structure to the Pine Script community.
"Object" allows Pine coders to finally create objects full or unique key:value pairs, which are converted to strings and stored in an array. Data can be stored and accessed using dedicated get and set methods.
The workflow is simple, but has a few nuances:
0. Import this library into your project; you can give it whatever alias you'd like (I'll be using obj)
1. Create your first object using the obj.new() method and assign it a variable or "ID".
2. Use the object's ID as the first argument into the obj.set() method, for the key and value there's one extra step required. They must be added as arguments to the appropriate prop_() method.
Note: While objects in this library technically only store data as strings, any primitive data type can be converted to a string before being stored, meaning that one object can hold data from multiple types at once. There's a trade off though..Pine Script requires that all exported function parameters have pre-defined types, meaning that as convenient as it would be to have a single method for storing and returning data of every type, it's not currently possible. Instead there are functions to add properties for each individual type, which are then converted to strings automatically (the original type is flagged and stored along with the data). Furthermore, since switch/if statements can only return values of the same type, there must also be "get" methods which correspond with each type. Again, a single "get" method which auto-detects the returned value's type was the goal but it's just not currently possible. Instead each get method is only allowed to return a value of its own type. No worries though, all the "get" methods will throw errors if they can't access the data you're trying to access. In that error message, you'll be informed exactly which "get" method you need to use if you ever lose track of what type of data you should be returning.
3. The second argument for obj.set() method is the obj.prop_() method. You just plug in your key as a string and your value and you're done. Easy as that.
Please do not skip this step, properties must be formatted correctly for data to be stored and accessed correctly
4. Obj.get_ (s: string, f: float, b: bool, i: int) methods are even easier, just choose whichever method will return the data type you need, then plug in your ID, and key and that's it. Objects will output data of the same type they were stored as!
There's a short example at the end of the script if you'd like to see more!
prop_string(string: key, string: value)
returns property formatted to string and flagged as string type
prop_float(string: key, float: value)
returns property formatted to string and flagged as float type
prop_bool(string: key, bool: value)
returns property formatted to string and flagged as bool type
prop_int(string: key, int: value)
returns property formatted to string and flagged as int type
Support for lines and shapes coming soon!
new()
returns an empty object
set(string : ID, string: property)
adds new property to object
get_f(string : ID, string: key)
returns float values
get_s(string : ID, string: key)
returns string values
get_b(string : ID, string: key)
returns boolean values
get_i(string : ID, string: key)
returns int values
More methods like Obj.remove(), Obj.size(), Obj.fromString, Obj.fromArray, Obj.toJSON, Obj.keys, & Obj.values coming very soon!!

Infiten's Return Candle OscillatorInfiten's Return Candle Oscillator is an oscillator which shows the percentage return on the open, high, close and low over a customizable period in the form of candlesticks. It may be helpful for seeing volatility, swing trading, or mean reversion trading.
The RCO consists of two plotted elements :
RCO Candles (short length): candlesticks which are plotted with low = the product of the percentage changes in the low over a period, high = the product of the percentage changes in the high over a period, close = the product of the percent changes in close over a period, and open = the product of the percentage changes in return over a period. Similarly to with standard candlesticks, if the percentage change on the close is higher than the percentage change on the open, the candlestick is green, otherwise it is red.
Smoothed RCO Line (long length) : a moving average of the average of the low, close, open and high calculated for the RCO Candles. The line's transparency is determined by the percentage difference between the RCO and the highest or lowest RCO over the long length. A more transparent line means that the RCO is closer to the highest or lowest RCO, and may be indicative of a reversal, or weakening trend.

Trend MasterThis is a trend aggregator for confirmation and trend signals. It basically aggregates many buy/sell signals and confirmation and by combining them provides a strong buy/sell signal or trend confirmation.
The actual layout idea and trend confirmation is derived from Trend Meter and this indicator uses few other indicator, such as Chandelier Exit, WaveTrend, QQE Signals, Parabolic SAR and AlphaTrend. This indicator aggregates signal from different methods to find out more powerful and confirmed Trend and combines them into one Signal. It also uses Technical Ratings from TradingView team to filter out false signal, it tremendously opts out false signals and improve profitability.
The first seven dots are these
All 3 Trend Meters Now Align
MACD Crossover - Fast - 8, 21, 5
RSI 13: > or < 50
RSI 5: > or < 50
MA Crossover
MA Crossover
Chaikin Money Flow
Alphatrend
Technical Ratings
Then trend
Chandelier Exit
WaveTrend
QQE Signals
Parabolic Sar
All 3 Trend Meters aligns and A signal from trend i
Instructions
Change buy/sell policy based on market trend
Works on all TimeFrame but gives more accuracy on 4H, 1D.
Buy when green big dot appears at the bottom.
Sell when red big dot appears at the bottom.
Red/green dot at the top line appears when three trend meter is aligned and this is a good confirmation.
Any red/green dot below horizontal bars are trend signals.
Big red/green got at the bottom appears whenever there's a good confirmation from trend meter and a buy/sell signal comes from any trend signals.
Also look on the technical ratings bar, green means buy, red means sell and yellow means neutral.
Look for Support or Resistance Levels for price to be attracted to.
Find confluence with other indicators.
The more Trend meters are lit up the better.
Alert
01 Buy Signal = Strong Buy Signal
02 Sell Signal = Strong Sell Signal
03 Buy Signal = Strong Buy Signal
04 Sell Signal = Strong Sell Signal
Thanks to TradingView Technical Ratings authors, evergot, Lij_MC, KivancOzbilgic for their work. This indicator was heavily inspired from their work.
Oversold RSI with Tight Stop-Loss Strategy (by Coinrule)KRAKEN:LINKUSD
This is one of the best strategies that can be used to get familiar with technical indicators and start to include them in your rules on Coinrule .
ENTRY
1. This trading system uses the RSI (Relative Strength Index) to anticipate good points to enter positions. RSI is a technical indicator frequently used in trading. It works by measuring the speed and change of price movements to determine whether a coin is oversold (indicating a good entry point) or overbought (indicating a point of exit/entry for a short position). The RSI oscillates between 0 and 100 and is traditionally considered overbought when over 70 and oversold when below 30.
2. To pick the right moment to buy, the strategy enters a trade when the RSI falls below 30 indicating the coin is oversold and primed for a trend reversal.
EXIT
The strategy then exits the position when the price appreciates 7% from the point of entry. The position also maintains a tight stop-loss and closes the position if the price depreciates 1% from the entry price. The idea behind this is to cut your losing trades fast and let your winners ride.
The best time frame for this strategy based on our back testing data is the daily. Shorter time frames can also work well on certain coins, however in our experience, the daily works best. Feel free to experiment with this script and test it on a variety of your coins! With our back testing data a trading fee of 0.1% is taken into account. The fee is aligned to the base fee applied on Binance, which is the largest cryptocurrency exchange by volume. In the example shown, this strategy made a handsome net profit of 52.6% on Chainlink with 66.67% of trades being profitable.
You can execute this strategy on your favorite exchanges with Coinrule .
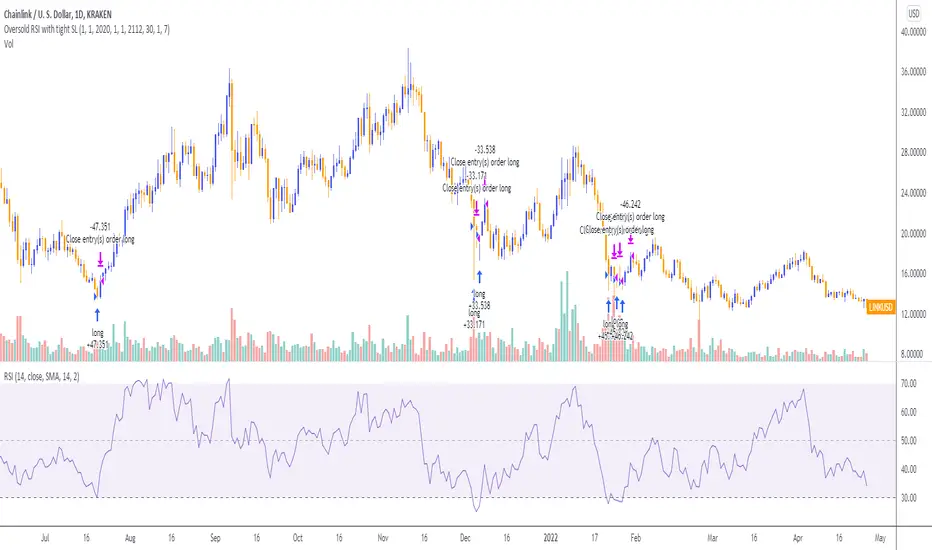
Moving Average Band Width ((((20/04/2022))))Todays Script uses 5 Moving Averages with the new function on V5 called fill, we can now colour fill between moving averages.
9ema
20ema
50ema
100ema
200ema
100-200ema which is labelled in Redis where the big impulse moves will fall into if the pressure is so strong on the opposite of the trend.
50-100ema which is labelled in Blue is where price could be heading in a healthy trend
20-50ema which is labelled in Purple, price will enter this area when price is in a strong impulse move/trend
9-20ema which is labelled in Green is a super strong trend/ impulse move, price will most likely break this stream and enter the 20-50ema
(the colour of EMAS can be changed in the settings)
I would use this to either gauge the strength of a trend//impulse leg or buy/sell opportunities.
This works best in trending environments, LTF and liquid markets

MTF Stochastic ScannerThis Stochastic scanner can be use to identify overbought and oversold of 10 symbols over multiple timeframes
it will give you a quick overview which pair is more overbough or more oversold and also signals tops and bottoms in the AVG row
light red/green cell = weak bearish (Stoch = 30-20) / bullish (Stoch = 70-80)
medium red/green cell = bearish (Stoch = 20-10) / bullish (Stoch = 80-90)
dark red/green cell = strong bearish (Stoch <= 10) / bullish (Stoch >= 90)
gray cell = neutral (Stoch = 30-70)
Usage
If AVG (average of all 4 timeframes) falls below 20, the cell will get green, indicating a good time to enter long (buy)
If AVG (average of all 4 timeframes) rises above 80, the cell will get red, indicating a good time to enter short (sell)
Use the "MTF Stochastic Scanner" in combination with the " MTF RSI Scanner "
to find tops (RSI MTF avg >=70 AND Stochastic MTF avg >= 80)
or bottoms (RSI MTF avg <= 30 AND Stochastic MTF avg <= 20)
Here is how the two MTF scanners looked on Nov 08 2021 (ATH) »
and here how the MTF scanners looked on June 21 2022
use TradingViews Replay function to check how it would have worked in the past and when not.
As always… there NOT a single indicator that can show to the top & bottom 100% every single time. So use with caution, with other indicators and/or deeper understanding of technicals analysis ☝️☝️☝️
Settings
You can change the timeframes, symbols, Stochastic settings, overbought/oversold levels and colors to your liking
Drag the table onto the price chart, if you want to use it as an overlay.
NOTE:
Because of the 4x10 security requests, it can take up to 1 minute for changed settings to take effect! Please be patient 🙃
If you have any idea on how to optimise the code, please feel free to share 🙏
*** Inspired by "Binance CHOP Dashboard" from @Cazimiro and "RSI MTF Table" from @mobester16 ***

MTF RSI ScannerThis RSI scanner can be use to identify the relative strength of 10 symbols over multiple timeframes
it will give you a quick overview which pair is more bearish or more bullish and also signals tops and bottoms in the AVG row
light red/green cell = weak bearish (RSI = 45-35) / bullish (RSI = 55-65)
medium red/green cell = bearish (RSI = 35-25) / bullish (RSI = 65-75)
dark red/green cell = strong bearish (RSI <= 25) / bullish (RSI >= 75)
gray cell = neutral (RSI= 45-55)
Usage
If AVG (average of all 4 timeframes) falls below 30, the cell will get green, indicating a good time to enter long (buy)
If AVG (average of all 4 timeframes) rises above 70, the cell will get red, indicating a good time to enter short (sell)
Use the "MTF RSI Scanner" in combination with the "MTF Stochastic Scanner"
to find tops (RSI MTF avg >=70 AND Stochastic MTF avg >= 80)
or bottoms (RSI MTF avg <= 30 AND Stochastic MTF avg <= 20)
Here is how the two MTF scanners looked on Nov 08 2021 (ATH) »
and here how the MTF scanners looked on June 21 2022
use TradingViews Replay function to check how it would have worked in the past and when not.
As always… there NOT a single indicator that can show to the top & bottom 100% every single time. So use with caution, with other indicators and/or deeper understanding of technicals analysis ☝️☝️☝️
Settings
You can change the timeframes, symbols, RSI settings, overbought/oversold levels and colors to your liking
Drag the table onto the price chart, if you want to use it as an overlay.
NOTE:
Because of the 4x10 security requests, it can take up to 1 minute for changed settings to take effect! Please be patient 🙃
If you have any idea on how to optimise the code, please feel free to share 🙏
*** Inspired by "Binance CHOP Dashboard" from @Cazimiro and "RSI MTF Table" from @mobester16 ***

HODL LINE [AstrideUnicorn]This indicator determines periods of bull market when a buy-and-hold investor can hold the asset, and bear market periods when they should avoid holding it. Though it was designed primarily with cryptocurrencies in mind, it can be successfully used for any market.
Technically, the indicator is an asymmetric trend filter aimed to account for the fact that market sell-offs tend to be sharper than up-trends. The algorithm has two regimes – with and without price smoothing.
HOW TO USE
The step-like line is the main trend filter. It is colored green in an uptrend and red in a downtrend. When the smoothing is on, in addition to the trend filter, the indicator plots a purple line. It is a Hull Moving Average (HMA) of the price. In this case, the indicator uses this line instead of the price to find crossings with the trend filter.
When the price or the smoothed line crosses the trend filter above, it is an uptrend signal. The indicator marks such crossings with green circles. It also colors the chart background green in an uptrend. The price or the purple line crossing the trend filter below means a downtrend signal. Downtrend signals show as red circles. The chart background in a downtrend turns red.
SETTINGS
Sensitivity – a dropdown list that allows the user to choose an averaging period of the indicator. Users can select a value for sensitivity from a predetermined set that better suits their investment horizon.
Use Smoothing – turns on and off smoothing of the price with HMA. With the smoothing turned on, the indicator responds slower to price changes, but at the same time produces less amount of false signals.
DMI RSI AO 3 indicators in 1 overlayThis is simple indicators that plot 3 indicators DMI, RSI and AO on 1 pane
How to use: you can add on your chart and edit color and display in setting page of indicators
The directional movement index (DMI) is an indicator developed by J. Welles Wilder in 1978 that identifies in which direction the price of an asset is moving. The indicator does this by comparing prior highs and lows and drawing two lines: a positive directional movement line (+DI) and a negative directional movement line (-DI). An optional third line, called the average directional index (ADX), can also be used to gauge the strength of the uptrend or downtrend.
When +DI is above -DI, there is more upward pressure than downward pressure in the price. Conversely, if -DI is above +DI, then there is more downward pressure on the price. This indicator may help traders assess the trend direction. Crossovers between the lines are also sometimes used as trade signals to buy or sell.
The relative strength index (RSI) is a momentum indicator used in technical analysis that measures the magnitude of recent price changes to evaluate overbought or oversold conditions in the price of a stock or other asset. The RSI is displayed as an oscillator (a line graph that moves between two extremes) and can have a reading from 0 to 100. The indicator was originally developed by J. Welles Wilder Jr. and introduced in his seminal 1978 book, “New Concepts in Technical Trading Systems.”1
Traditional interpretation and usage of the RSI are that values of 70 or above indicate that a security is becoming overbought or overvalued and may be primed for a trend reversal or corrective pullback in price. An RSI reading of 30 or below indicates an oversold or undervalued condition.
Awesome Oscillator is developed by famous technical analyst and charting enthusiast Bill Williams. Awesome Oscillator (AO) is an indicator that is non-limiting oscillator, providing insight into the weakness or the strength of a stock. The Awesome Oscillator is used to measure market momentum and to affirm trends or to anticipate possible reversals. It does this by effectively comparing the recent market momentum, with the general momentum over a wider frame of reference.

Oscillators Overlay w/ Divergencies/Alerts by DGTAn oscillator is a technical analysis tool that, simply said, gauge momentum, determine market trend direction and duration. For some oscillators, fluctuations are bounded by some upper and lower band, and traders use them to discover short-term overbought or oversold conditions.
Oscillators are often combined with moving average indicators to signal trend breakouts or reversals
Histogram, is the difference between the oscillator and signal lines, which oscillates above and below a center line and is used as a good indication of an asset's momentum
What to look for
- Signal Line Crossover is the most common signal produced by the oscillators
- Zero Line Crossovers have a very similar premise to Signal Line Crossovers
- Divergence , when the oscillator and actual price are not in agreement, is another signal created by the oscillators
- Overbought and Oversold , with any range-bound oscillator, conditions are a primary signal generated
Oscillators Overlay study
* Presents oscillators on top of the mian chart (price chart)
* A single indicator for many well known and custom oscillators
* Divergence detection
* Alerts for various condtions
The list of oscillators included;
- Awesome Oscillator (AO)
- Chaikin Oscillator (Chaikin Osc)
- Commodity Channel Index (CCI)
- Distance Oscillator
- Elder-Ray Bear and Bull Power
- Elliott Wave Oscillator (EWO)
- Klinger Oscillator
- Money Flow Index (MFI)
- Moving Average Convergence Divergence (MACD)
- Rate Of Change (ROC)
- Relative Strength Index (RSI)
- Stochastic (Stoch)
- Stochastic RSI (Stoch RSI)
- Volume Oscillator (Volume Osc)
- Wave Trend
In technical analysis, investors find oscillators to be important technical tools and consider them more effective when used in conjunction with other means of technical analysis
Disclaimer : Trading success is all about following your trading strategy and the indicators should fit within your trading strategy, and not to be traded upon solely
The script is for informational and educational purposes only. Use of the script does not constitutes professional and/or financial advice. You alone the sole responsibility of evaluating the script output and risks associated with the use of the script. In exchange for using the script, you agree not to hold dgtrd TradingView user liable for any possible claim for damages arising from any decision you make based on use of the script
MACD-X Overlay, More Than MACD by DGTMoving Average Convergence Divergence – MACD
The most popular indicator used in technical analysis , the moving average convergence divergence ( MACD ), created by Gerald Appel. MACD is a trend-following momentum indicator , designed to reveal changes in the strength, direction, momentum, and duration of a trend in a financial instrument’s price
Historical evolution of MACD ,
- Gerald Appel created the MACD line,
- Thomas Aspray added the histogram feature to MACD
- Giorgos E. Siligardos created a leader of MACD
MACD employs two Moving Averages of varying lengths (which are lagging indicators) to identify trend direction and duration. Then, MACD takes the difference in values between those two Moving Averages (MACD Line) and an EMA of those Moving Averages (Signal Line) and plots that difference between the two lines as a histogram which oscillates above and below a center Zero Line. The histogram is used as a good indication of a security's momentum.
The MACD indicator is typically good for identifying three types of basic signals;
Signal Line Crossovers
A Signal Line Crossover is the most common signal produced by the MACD . On the occasions where the MACD Line crosses above or below the Signal Line, that can signify a potentially strong move. The standard interpretation of such an event is a recommendation to buy if the MACD line crosses up through the Signal Line (a "bullish" crossover), or to sell if it crosses down through the Signal Line (a "bearish" crossover). These events are taken as indications that the trend in the financial instrument is about to accelerate in the direction of the crossover.
Zero Line Crossovers
Zero Line Crossovers occur when the MACD Line crossed the Zero Line and either becomes positive (above 0) or negative (below 0). A change from positive to negative MACD is interpreted as "bearish", and from negative to positive as "bullish". Zero crossovers provide evidence of a change in the direction of a trend but less confirmation of its momentum than a signal line crossover
Divergence
Divergence is another signal created by the MACD . Simply, divergence occurs when the MACD and actual price are not in agreement. A "positive divergence" or "bullish divergence" occurs when the price makes a new low but the MACD does not confirm with a new low of its own. A "negative divergence" or "bearish divergence" occurs when the price makes a new high but the MACD does not confirm with a new high of its own. A divergence with respect to price may occur on the MACD line and/or the MACD Histogram
Moving Average Crossovers , another hidden signal that MACD Indicator identifies
Many traders will watch for a short-term moving average to cross above a longer-term moving average and use this to signal increasing upward momentum. This bullish crossover suggests that the price has recently been rising at a faster rate than it has in the past, so it is a common technical buy sign. Conversely, a short-term moving average crossing below a longer-term average is used to illustrate that the asset's price has been moving downward at a faster rate and that it may be a good time to sell.
Moving Average Crossovers in reality is Zero Line Crossovers, the value of the MACD indicator is equal to zero each time the two moving averages cross over each other. For easy interpretation by trades, Zero Line Crossovers are simply described as positive or negative MACD
False signals
Like any forecasting algorithm, the MACD can generate false signals. A false positive, for example, would be a bullish crossover followed by a sudden decline in a financial instrument. A false negative would be a situation where there is bearish crossover, yet the financial instrument accelerated suddenly upwards
What is “MACD-X” and Why it is “More Than MACD”
In its simples form, MACD-X implements variety of different calculation techniques applied to obtain MACD Line. Different calculation techniques lead to different values for MACD Line, as will further discuss below, and as a consequence the signal line and the histogram values will differentiate accordingly.
Main features of MACD-X ;
1- Plotting of the Oscillator presented on top of the price chart (main chart) and applicable on both log and linear scale. Maximum plotting length is limited to 250 bars
2- Introduces different proven techniques applied on MACD calculation, such as MACD-AS (Histogram), MACD-Leader and MACD-Source, besides the traditional MACD (MACD-TRADITIONAL)
• MACD-Traditional, by Gerald Appel
It is the MACD that we know, stated as traditional just to avoid confusion with other techniques used with this study
• MACD-Histogram, by Thomas Aspray
The MACD-Histogram measures the distance between MACD and its signal line (the 9-day EMA of MACD ). Aspray developed the MACD-Histogram to anticipate signal line crossovers in MACD . Because MACD uses moving averages and moving averages lag price, signal line crossovers can come late and affect the reward-to-risk ratio of a trade. Bullish or bearish divergences in the MACD-Histogram can alert chartists to an imminent signal line crossover in MACD
Aspray's contribution served as a way to anticipate (and therefore cut down on lag) possible MACD crossovers which are a fundamental part of the indicator.
• MACD-Leader, by Giorgos E. Siligardos, PhD
MACD Leader has the ability to lead MACD at critical situations. Almost all smoothing methods encounter in technical analysis are based on a relative-weighted sum of past prices, and the Leader is no exception. The concealed weights of MACD Leader are such that more relative weight is used in the more recent prices than the respective weights used by the components of MACD . In effect, the Leader expresses more changes in average price dynamics for the recent price movement than MACD , thus eventually leading MACD , especially when significant trend changes are about to take place.
• MACD-Source, a custom experimental interpretation of mine,
MACD Source, presents an application of MACD that evaluates Source/MA Ratio, relatively with less lag, as a basis for MACD Line, also can be expressed as source convergence/divergence to its moving average. Among the various techniques for removing the lag between price and moving average (MA) of the price, one in particular stands out: the addition to the moving average of a portion of the difference between the price and MA. MACD Source, is based on signal length mean of the difference between Source and average value of shot length and long length moving average of the source (Source/MA Ratio), where the source is actual value and hence no lag and relatively less lag with the average value of moving average of the source .
MACD Source provides relatively early crossovers comparing to MACD and better momentum direction indications, assuming the lengths are set to same values
3- Alerts presented for MACD and Signal Line Crosses both for Early Warning and Confirmed Crossovers
For more, You are kindly invited to have a look to other MACD or similar studies presented on separate pane
MACD-X, More Than MACD by DGT , P-MACD by DGT and Price Distance to its MA by DGT
Disclaimer : Trading success is all about following your trading strategy and the indicators should fit within your trading strategy, and not to be traded upon solely
The script is for informational and educational purposes only. Use of the script does not constitutes professional and/or financial advice. You alone the sole responsibility of evaluating the script output and risks associated with the use of the script. In exchange for using the script, you agree not to hold dgtrd TradingView user liable for any possible claim for damages arising from any decision you make based on use of the script

Multi-TimeFrame Extremum Points Support/ResistanceIntroduction
This is my newest Support/Resistance indicator based on the idea of my previous script which had been featured in Editors' Picks .
Everyone seems to have their own idea of how you should measure support and resistance levels. This code finds the exact highest and lowest price points (Extrema) on the chart and then draws the support and resistance levels on them.
In my opinion, the advantage of this method is that the most powerful resistance/support levels which usually cover the supply/demand areas would be formed on these extremum points, as the following facts state.
Facts
1. Support and resistance levels are one of the key concepts used by technical analysts and form the basis of a wide variety of technical analysis tools. Technical analysts use support and resistance levels to identify price points on a chart where the probabilities favor a pause or reversal of a prevailing trend.
2. Supply and demand zones are natural support and resistance levels and a popular analysis technique used in day trading. The zones are the periods of sideways price action that come before explosive price moves. A supply zone forms before a downtrend and a demand zone forms before an uptrend. When the price leaves the supply/demand zone and starts trending, the strong imbalance between buyers and sellers leads to strong and explosive price movements.
3. Based on Dow Theory, trends persist until a clear reversal occurs. A reversal is a change in the price direction of an asset. Reversals typically refer to large price changes, where the trend changes direction.
Challenges
The most challenging part in implementing a S/R indicator which draws all the levels on the chart is the problem of congestion!
But we should notice two other facts:
1. The more times the price tests a support or resistance area, the more significant the level becomes.
2. A previous support level will sometimes become a resistance level when the price attempts to move back up, and conversely, a resistance level will become a support level as the price temporarily falls back.
So, I solved the problem using these two approaches:
Merging nearby levels and showing the role of the levels in colors and numbers
Avoiding many weaker levels by checking higher time frames
Settings and Usage
There are some options in the indicator settings as described below:
Calculations Time Frame: By changing the time frame, user could keep only the stronger S/R levels on the chart.
Level Colors: By default, lowest points (Supports) are green, highest points (Resistances) are red and merged levels are blue. Note that the transparency of the colors would be calculated automatically; The more opaque the color is, the stronger the level is!
Lines Style and Width: The style of the levels could be solid, dashed or dotted and user could also change the lines width in pixels.
Length of the lines: This option is based on the count of bars, but user could simply choose to extend the levels
Merge Nearby Levels: The proximity of the levels would be calculated automatically based on ATR (Average True Range) and the default length of the formula could be changed.
Labels: Each level could have a label consisting the count of merged levels into one, the percentage of merged supports/resistances and the price of the level. Note that if user choose to see the percentage of S/R roles, the color of each label changes automatically based on the main role of corresponding merged level (e.g., a blue level with a red label means that the level more acted as resistance).
I think the users of my previous S/R indicators could check this one
That's it for now! Feel free to send me your thoughts!