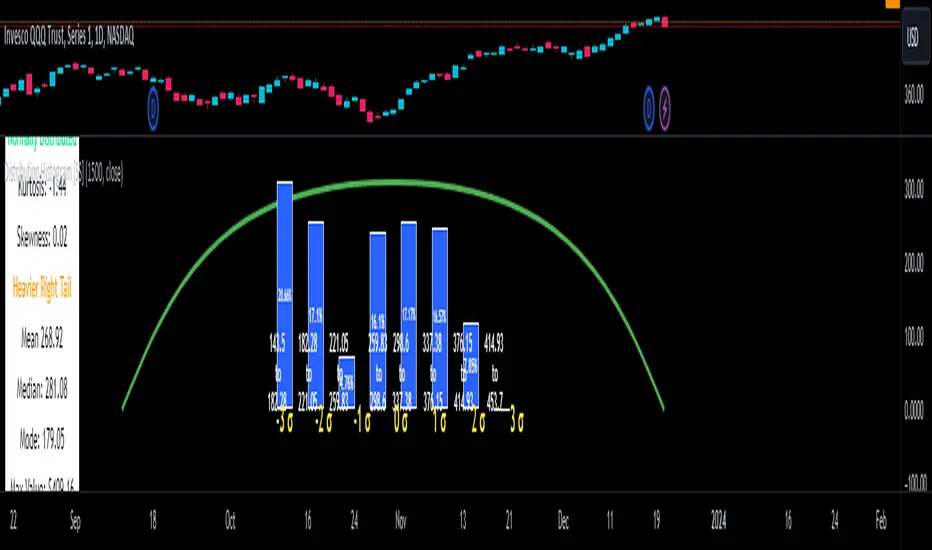
Distribution Histogram [SS]This is the frequency histogram indicator. It does just that—creates a frequency histogram distribution based on your desired lookback period. It then uses Pine's new Polyline function to plot a normal curve of the expected results for a normal distribution. This allows you to see quite a few things:
🎯 Firstly, it allows you to see where the accumulation rests in terms of a bell curve. The histogram represents a bell curve, and you can visually observe what the curve would look like.
🎯 Secondly, it will assess the normal distribution and the degree of skewness based on the curve itself. The indicator imports the SPTS statistics library to assess the distribution using Kurtosis and Skewness. However, it also adds functionality in this regard by making a qualitative assessment of the data. For example, if there are heavy left tails or heavier right tails present in the histogram, the indicator will alert you that a heavier left or right tail has been observed.
🎯 Thirdly, it provides you with the kurtosis and skewness of the dataset.
🎯 Fourthly, it provides the mean, median, and mode of the dataset, as well as the maximum and minimum values within the dataset.
🎯 Lastly, it provides you with the ability to toggle on tips/explanations of the curve itself. Simply toggle on "Show Distribution Explanation" in the settings menu:
How is the indicator helpful for trading?
If you are a mean reversion trader, this helps you identify the areas and price ranges of high and low accumulation. It also allows you to ascertain the probability by looking at the standard deviation of the bell curve. Remember, the majority of values should fall between -1 and 1 standard deviation of the mean (68%).
If it is revealed that the distribution has a heavier right or left tail, you will know that the stock is more likely to experience sudden drops and shifts in the curve in one direction or the other. Heavier left tails will tend to shift to the values on the far left, and vice versa for right tails.
Customization
You can turn off and on the following:
👉 The normal curve,
👉 The standard deviation levels, and
👉 The distribution explanations and tips.
Conclusion: And that is the indicator! Hope you enjoy it!
스크립트에서 "curve"에 대해 찾기
Orion Algo Strategy v2.0Hi everyone.
I decided to make the latest Orion Algo open to people. I don't have enough time to work on it lately, so I figured it would be best that everyone can have it to work on it. I took out some stuff from the original but it should give an idea on how things work. I made two strategies with this so far so you can use that to come up with your own. I recommend the DCA strategy because it gives you the most bang for Orion Algo's buck. It's pretty good at finding long entries.
Overall I hope you guys like this one. Also, Banano is the best crypto currency :)
-INFO-
Orion Algo is a trading algorithm designed to help traders find the highs and lows of the market before, during, and after they happen. We wanted to give an indicator to people that was simple to use. In fact we created the algorithm in such a way that it currently only needs a single input from the user. Since no indicator can predict the market perfectly, Orion should be used as just another tool (although quite a sharp one) for you to trade with. Fundamental knowledge of price action and TA should be used with Orion Algo.
Being an oscillator, Orion currently has a bias towards market volatility . So you will want to be trading markets over 30% volatility . We have plans to develop future versions that take this into account and adjust automatically for dead conditions. Also, while there are some similarities across all oscillators, what sets ours apart is the prediction curve. The prediction curve looks at the current signal values and gives it a relative score to approximate tops and bottoms 1-2 bars ahead of the signal curve. We also designed a velocity curve that attempts to predict the signal curve 2+ bars ahead. You can find the relative change in velocity in the Info panel. The bottom momentum wave is based on the signal curve and helps find overall market direction of higher time-frames while in a lower one.
Settings and How to Use them:
User Agreement – Orion Algo is a tool for you to use while trading. We aren’t responsible for losses OR the gains you make with it. By clicking the checkbox on the left you are agreeing to the terms.
Super Smooth – Smooths the main signal line based on the value inside the box. Lower values shift the pivot points to the left but also make things more noisy. Higher values move things to the right making it lag a bit more while creating a smoother signal. 8 is a good value to start with.
Theme – Changes the color scheme of Orion.
Dashboard – Turns on a dashboard with useful stats, such as Delta v, Volatility , Rsi , etc. Changing the value box will move the dashboard left and right.
Prediction – A secondary prediction model that attempts to predict a reversal before it happens (0-2bars). This can be noisy some times so make your best judgement. Curve will toggle a curve view of the prediction. Pivots will toggle bull/bear dots.
∆v – Delta v (change in velocity). This shows momentum of the signal. Crossing 0 signals a reversal. If you see the delta v changing direction, it may signify a reversal in the several bars depending on the overall momentum of the market.
Momentum Wave – Uses the signal as a macro trend indicator. Changes in direction of the wave can signify macro changes in the market. Average will toggle an averaging algorithm of the momentum waves and makes it easy to understand.
-STRATEGIES-
Simple - Just buy and sell on the dots
DCA - Uses the settings in the script for entries. If a buy dot appears then it will buy, if the price goes below the percentage it will wait for another dot before entering. This drastically improves DCA potential.
Support and Resistance LevelsDetecting Support and Resistance Levels
Description:
Support & Resistance levels are essential for every trader to define the decision points of the markets. If you are long and the market falls below the previous support level, you most probably have got the wrong position and better exit.
This script uses the first and second deviation of a curve to find the turning points and extremes of the price curve.
The deviation of a curve is nothing else than the momentum of a curve (and inertia is another name for momentum). It defines the slope of the curve. If the slope of a curve is zero, you have found a local extreme. The curve will change from rising to falling or the other way round.
The second deviation, or the momentum of momentum, shows you the turning points of the first deviation. This is important, as at this point the original curve will switch from acceleration to break mode.
Using the logic laid out above the support&resistance indicator will show the turning points of the market in a timely manner. Depending on level of market-smoothing it will show the long term or short term turning points.
This script first calculates the first and second deviation of the smoothed market, and in a second step runs the turning point detection.
Style tags: Trend Following, Trend Analysis
Asset class: Equities, Futures, ETFs, Currencies and Commodities
Dataset: FX Minutes/Hours/Days
Reduced-Lag Chande Momentum Oscillator [BOSWaves]Reduced-Lag Chande Momentum Oscillator – Adaptive Momentum Geometry with Reduced-Latency Reversion Logic
Overview
The Reduced-Lag Chande Momentum Oscillator represents a sophisticated extension of the classical Chande Momentum Oscillator, preserving the foundational measurement of net directional pressure while addressing inherent limitations in lag, noise, and signal clarity. The traditional CMO provides reliable snapshots of upward versus downward force but reacts slowly to rapid market accelerations and can obscure meaningful momentum inflections with delayed readings. This iteration integrates a dual-stage reduced-lag filter, optional advanced smoothing, and acceleration-based analytics, producing a real-time, multi-dimensional representation of market momentum.
The design reframes classical momentum using a layered curvature and gradient structure - main, midline, and shadow - to show trajectory, velocity, and intensity in one view. Instead of the usual ±70/30 extremes, it uses ±50 as a statistically grounded threshold where one side of the market begins exerting true dominance. This captures structural imbalance more reliably, exposing exhaustion and actionable inflection without amplifying noise.
This visualization gives traders a continuous, responsive read on market structure, revealing not just direction but rate of change, acceleration alignment, and curvature behavior. The oscillator becomes a momentum map, expressing both probability and intensity behind directional shifts.
Where conventional oscillators mislabel short-lived swings as signals, the Reduced-Lag CMO separates baseline shifts from high-conviction transitions, enabling cleaner, more decisive signal interpretation.
Theoretical Foundation
The classical Chande Momentum Oscillator, created by Tushar Chande, calculates the normalized net difference between consecutive upward and downward price changes over a defined window, generating readings from –100 to +100. While effective for capturing basic directional pressure, the unmodified CMO suffers from signal latency and sensitivity to abrupt market swings, which can obscure actionable inflection points.
The Reduced-Lag CMO augments this foundation with three key mechanisms:
Reduced-Lag Filtering : A dual-EMA structure eliminates inertial lag, aligning the oscillator curve closely with real-time market momentum without producing overshoot artifacts.
Smoothing Architecture : Optional SMA, EMA, or WMA smoothing is applied post-filter, balancing noise reduction with trajectory fidelity. A multi-layer line system (shadow → midline → main) communicates depth, curvature, and gradient dynamics.
Acceleration Integration : First and second derivatives of the smoothed curve quantify velocity and acceleration, allowing the indicator to identify not only momentum flips but the force behind each shift, forming the basis for the strong-signal overlay.
The combination of these mechanisms produces an oscillator that respects the original CMO framework while delivering real-time, context-sensitive intelligence. The ±50 boundaries are selected as the statistically validated pressure zones where directional dominance exceeds neutral oscillation. Crosses and rejections at these boundaries are not arbitrary overbought/oversold events, but measurable imbalances with actionable significance.
How It Works
The Reduced-Lag CMO is constructed through a multi-stage process:
Momentum Estimation Core : Raw CMO values are calculated and then passed through a reduced-lag filter to remove delay, creating a curve that closely tracks instantaneous directional pressure.
Smoothing & Layered Representation : The filtered curve can be smoothed and split into three layers - shadow, midline, and main - giving visual depth, trajectory clarity, and curvature instead of a single-line oscillator.
Gradient-Based Pressure Mapping : Color gradients encode momentum strength and polarity. Green-yellow transitions highlight increasing upward dominance, while red-yellow transitions indicate weakening downward force.
Pressure-Zone Anchoring (±50) : The system defines statistically significant pressure zones at ±50. Moves beyond these levels reflect dominant directional control, and rejections inside the zone signal potential exhaustion.
Signal Generation : Momentum events are evaluated through velocity and acceleration. Standard signals appear as triangle markers indicating validated momentum flips. Strong signals appear as triangles with diamonds when acceleration confirms a high-conviction transition.
A cooldown rule spaces signals apart to reduce clutter and emphasize structurally meaningful events.
Interpretation
The Reduced-Lag CMO reframes momentum as a dynamic equilibrium between directional force and structural pressure:
Positive Momentum Phases : Curves above zero with green-yellow gradients indicate sustained upward pressure. Shallow retracements or midline tests denote controlled pullbacks.
Negative Momentum Phases : Curves below zero with red-yellow gradients show downward dominance. Rejections from –50 highlight potential exhaustion and reversal readiness.
Pressure-Zone Dynamics (±50) : Crosses beyond ±50 confirm dominant directional force. Meanwhile, rejections and rotations inside the zone signal structural fatigue.
Velocity & Acceleration Analysis : Rising momentum with decelerating velocity suggests fading force; acceleration alignment amplifies signal strength and forms the basis of strong signals.
Signal Architecture
The Reduced-Lag CMO produces a single event type with two intensities: a validated momentum inflection.
Standard Signals - Triangles:
Triggered by momentum flips confirmed by velocity.
Represent moderate-intensity directional changes.
Appear at zero-line crosses or ±50 rejections with aligned velocity.
Strong Signals Triangles + Diamonds:
Triggered when acceleration confirms the directional change.
Represent high-intensity, high-conviction shifts.
Rare by design; indicate robust momentum inflections.
Cooldown mechanics prevent repeated signals in short succession, emphasizing structural reliability over noise.
Strategy Integration
Trend Confirmation : Align zero-line flips with higher-timeframe directional bias.
Reversal Detection : Strong signals from ±50 zones highlight potential inflection points.
Volatility Assessment : Gradient transitions reveal strengthening or weakening momentum.
Pullback Timing : Multi-layer curvature identifies controlled retracements vs trend exhaustion.
Confluence Mapping : Pair with structure-based indicators to filter signals in context.
Technical Implementation Details
Core Engine : Classical CMO with Ehlers reduced-lag extension
Lag Reduction : Dual EMA filtering
Smoothing : Optional SMA/EMA/WMA post-filter
Multi-Layer Curve : Shadow, midline, main
Signal System : Two-tier momentum-acceleration framework
Pressure Zones : ±50 statistically validated thresholds
Cooldown Logic : Bar-indexed suppression
Gradient Mapping : Encodes magnitude and direction
Alerts : Standard and strong signals
Optimal Application Parameters
Timeframes:
1 - 5 min : Intraday momentum tracking
15 - 60 min : Trend rotations & volatility transitions
4H - Daily : Macro momentum exhaustion & re-accumulation mapping
Suggested Ranges:
CMO Length : 7 - 12
Reduced-Lag Length : 5 - 15
Smoothing : 10 - 20
Cooldown Bars : 5 - 15
Performance Characteristics
High Effectiveness:
Markets with directional pulses & clean pressure transitions
Trending phases with measurable pullbacks
Instruments with stable volatility cycles
Reduced Edge:
Choppy consolidations
Ultra-low volatility environments
Disclaimer
The Reduced-Lag Chande Momentum Oscillator is a professional-grade analytical tool. It is not predictive and carries no guaranteed profitability. Effectiveness depends on asset class, volatility regime, parameter selection, and disciplined execution. Any suggested application timeframes or recommended ranges are guidance only - they are not universally optimal and will not deliver consistent accuracy on every asset or market condition. BOSWaves recommends using it in conjunction with structure, liquidity, and momentum context.

ErrorFunctionsLibrary "ErrorFunctions"
A collection of functions used to approximate the area beneath a Gaussian curve.
Because an ERF (Error Function) is an integral, there is no closed-form solution to calculating the area beneath the curve. Meaning all ERFs are approximations; precisely wrong, but mostly accurate. How close you need to get to the actual area depends entirely on your use case, with more precision being less efficient.
The internal precision of floats in Pine Script is 1e-16 (16 decimals, aka. double precision). This library adapts well known algorithms designed to efficiently reach double precision. Single precision alternates are also included. All of them were made free to use, modify, and distribute by their original authors.
HASTINGS
Adaptation of a single precision ERF by Cecil Hastings Jr, published through Princeton University in 1955. It was later documented by Abramowitz and Stegun as equation 7.1.26 in their 1972 Handbook of Mathematical Functions. Fast, efficient, and ideal when precision beyond a few decimals is unnecessary.
GILES
Adaptation of a single precision Inverse ERF by Michael Giles, published through the University of Oxford in 2012. It reverses the ERF, estimating an X coordinate from an area. It too is fast, efficient, and ideal when precision beyond a few decimals is unnecessary.
LIBC
Adaptation of the double precision ERF & ERFC in the standard C library (aka. libc). It is also the same ERF & ERFC that SciPy uses. While not quite as efficient as the Hastings approximation, it's still very fast and fully maximizes Pines precision.
BOOST
Adaptation of the double precision Inverse ERF & Inverse ERFC in the Boost Math C++ library. SciPy uses these as well. These reverse the ERF & ERFC, estimating an X coordinate from an area. It too isn't quite as efficient as the Giles approximation, but still fast and fully maximizes Pines precision.
While these algorithms are not exported directly, they are available through their exported counterparts.
- - -
ERROR FUNCTIONS
erf(x, precise)
An Error Function estimates the theoretical error of a measurement.
Parameters:
x (float) : (float) Upper limit of the integration.
precise (bool) : Double precision (true) or single precision (false).
Returns: (float) Between -1 and 1.
erfc(x, precise)
A Complementary Error Function estimates the difference between a theoretical error and infinity.
Parameters:
x (float) : (float) Lower limit of the integration.
precise (bool) : Double precision (true) or single precision (false).
Returns: (float) Between 0 and 2.
erfinv(x, precise)
An Inverse Error Function reverses the erf() by estimating the original measurement from the theoretical error.
Parameters:
x (float) : (float) Theoretical error.
precise (bool) : Double precision (true) or single precision (false).
Returns: (float) Between 0 and ± infinity.
erfcinv(x, precise)
An Inverse Complementary Error Function reverses the erfc() by estimating the original measurement from the difference between the theoretical error and infinity.
Parameters:
x (float) : (float) Difference between the theoretical error and infinity.
precise (bool) : Double precision (true) or single precision (false).
Returns: (float) Between 0 and ± infinity.
- - -
DISTRIBUTION FUNCTIONS
pdf(x, m, s)
A Probability Density Function estimates the probability density . For clarity, density is not a probability .
Parameters:
x (float) : (float) X coordinate for which a density will be estimated.
m (float) : (float) Mean
s (float) : (float) Sigma
Returns: (float) Between 0 and ∞.
cdf(z, precise)
A Cumulative Distribution Function estimates the area under a Gaussian curve between negative infinity and the Z Score.
Parameters:
z (float) : (float) Z Score.
precise (bool) : Double precision (true) or single precision (false).
Returns: (float) Between 0 and 1.
cdfinv(a, precise)
An Inverse Cumulative Distribution Function reverses the cdf() by estimating the Z Score from an area.
Parameters:
a (float) : (float) Area between 0 and 1.
precise (bool) : Double precision (true) or single precision (false).
Returns: (float) Between -∞ and +∞
cdfab(z1, z2, precise)
A Cumulative Distribution Function from A to B estimates the area under a Gaussian curve between two Z Scores (A and B).
Parameters:
z1 (float) : (float) First Z Score.
z2 (float) : (float) Second Z Score.
precise (bool) : Double precision (true) or single precision (false).
Returns: (float) Between 0 and 1.
ttt(z, precise)
A Two-Tailed Test estimates the area under a Gaussian curve between symmetrical ± Z scores and ± infinity.
Parameters:
z (float) : (float) One of the symmetrical Z Scores.
precise (bool) : Double precision (true) or single precision (false).
Returns: (float) Between 0 and 1.
tttinv(a, precise)
An Inverse Two-Tailed Test reverses the ttt() by estimating the absolute Z Score from an area.
Parameters:
a (float) : (float) Area between 0 and 1.
precise (bool) : Double precision (true) or single precision (false).
Returns: (float) Between 0 and ∞.
ott(z, precise)
A One-Tailed Test estimates the area under a Gaussian curve between an absolute Z Score and infinity.
Parameters:
z (float) : (float) Z Score.
precise (bool) : Double precision (true) or single precision (false).
Returns: (float) Between 0 and 1.
ottinv(a, precise)
An Inverse One-Tailed Test Reverses the ott() by estimating the Z Score from a an area.
Parameters:
a (float) : (float) Area between 0 and 1.
precise (bool) : Double precision (true) or single precision (false).
Returns: (float) Between 0 and ∞.

Trailing Management (Zeiierman)█ Overview
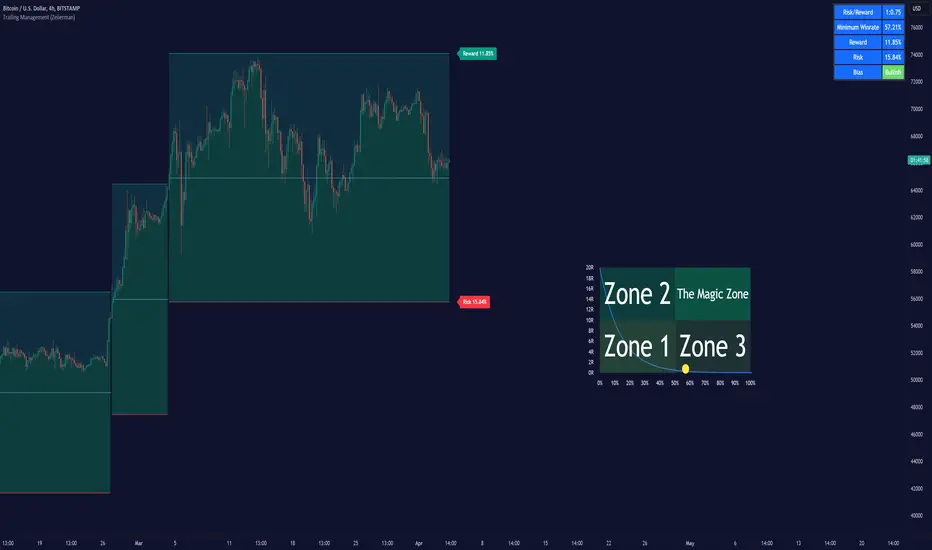
The Trailing Management (Zeiierman) indicator is designed for traders who seek an automated and dynamic approach to managing trailing stops. It helps traders make systematic decisions regarding when to enter and exit trades based on the calculated risk-reward ratio. By providing a clear visual representation of trailing stop levels and risk-reward metrics, the indicator is an essential tool for both novice and experienced traders aiming to enhance their trading discipline.
The Trailing Management (Zeiierman) indicator integrates a Break-Even Curve feature to enhance its utility in trailing stop management and risk-reward optimization. The Break-Even Curve illuminates the precise point at which a trade neither gains nor loses value, offering clarity on the risk-reward landscape. Furthermore, this precise point is calculated based on the required win rate and the risk/reward ratio. This calculation aids traders in understanding the type of strategy they need to employ at any given time to be profitable. In other words, traders can, at any given point, assess the kind of strategy they need to utilize to make money, depending on the price's position within the risk/reward box.
█ How It Works
The indicator operates by computing the highest high and the lowest low over a user-defined period and then applying this information to determine optimal trailing stop levels for both long and short positions.
Directional Bias:
It establishes the direction of the market trend by comparing the index of the highest high and the lowest low within the lookback period.
Bullish
Bearish
Trailing Stop Adjustment:
The trailing stops are adjusted using one of three methods: an automatic calculation based on the median of recent peak differences, pivot points, or a fixed percentage defined by the user.
The Break-Even Curve:
The Break-Even Curve, along with the risk/reward ratio, is determined through the trailing method. This approach utilizes the current closing price as a hypothetical entry point for trades. All calculations, including those for the curve, are based on this current closing price, ensuring real-time accuracy and relevance. As market conditions fluctuate, the curve dynamically adjusts, offering traders a visual benchmark that signifies the break-even point. This real-time adjustment provides traders with an invaluable tool, allowing them to visually track how shifts in the market could impact the point at which their trades neither gain nor lose value.
Example:
Let's say the price is at the midpoint of the risk/reward box; this means that the risk/reward ratio should be 1:1, and the minimum win rate is 50% to break even.
In this example, we can see that the price is near the stop-loss level. If you are about to take a trade in this area and would respect your stop, you only need to have a minimum win rate of 11% to earn money, given the risk/reward ratio, assuming that you hold the trade to the target.
In other words, traders can, at any given point, assess the kind of strategy they need to employ to make money based on the price's position within the risk/reward box.
█ How to Use
Market Bias:
When using the Auto Bias feature, the indicator calculates the underlying market bias and displays it as either bullish or bearish. This helps traders align their trades with the underlying market trend.
Risk Management:
By observing the plotted trailing stops and the risk-reward ratios, traders can make strategic decisions to enter or exit positions, effectively managing the risk.
Strategy selection:
The Break-Even Curve is a powerful tool for managing risk, allowing traders to visualize the relationship between their trailing stops and the market's price movements. By understanding where the break-even point lies, traders can adjust their strategies to either lock in profits or cut losses.
Based on the plotted risk/reward box and the location of the price within this box, traders can easily see the win rate required by their strategy to make money in the long run, given the risk/reward ratio.
Consider this example: The market is bullish, as indicated by the bias, and the indicator suggests looking into long trades. The price is near the top of the risk/reward box, which means entering the market right now carries a huge risk, and the potential reward is very low. To take this trade, traders must have a strategy with a win rate of at least 90%.
█ Settings
Trailing Method:
Auto: The indicator calculates the trailing stop dynamically based on market conditions.
Pivot: The trailing stop is adjusted to the highest high (long positions) or lowest low (short positions) identified within a specified lookback period. This method uses the pivotal points of the market to set the trailing stop.
Percentage: The trailing stop is set at a fixed percentage away from the peak high or low.
Trailing Size (prd):
This setting defines the lookback period for the highest high and lowest low, which affects the sensitivity of the trailing stop to price movements.
Percentage Step (perc):
If the 'Percentage' method is selected, this setting determines the fixed percentage for the trailing stop distance.
Set Bias (bias):
Allows users to set a market bias which can be Bullish, Bearish, or Auto, affecting how the trailing stop is adjusted in relation to the market trend.
-----------------
Disclaimer
The information contained in my Scripts/Indicators/Ideas/Algos/Systems does not constitute financial advice or a solicitation to buy or sell any securities of any type. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from the use of or reliance on such information.
All investments involve risk, and the past performance of a security, industry, sector, market, financial product, trading strategy, backtest, or individual's trading does not guarantee future results or returns. Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.
My Scripts/Indicators/Ideas/Algos/Systems are only for educational purposes!
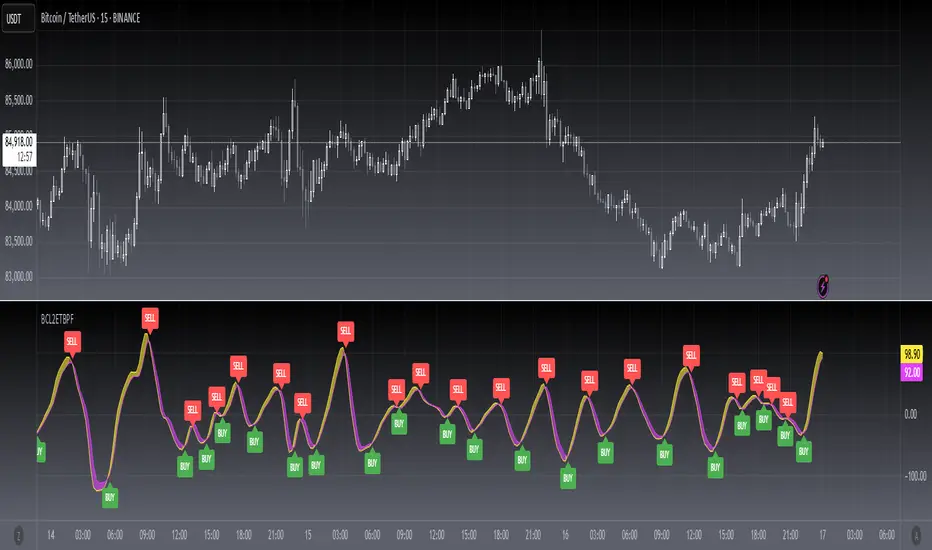
[blackcat] L2 Ehlers Truncated BP FilterLevel: 2
Background
John F. Ehlers introuced Truncated BandPass (BP) Filter in Jul, 2020.
Function
In Dr. Ehlers' article “Truncated Indicators” in Jul, 2020, he introduces a method that can be used to modify some indicators, improving how accurately they are able to track and respond to price action. By limiting the data range, that is, truncating the data, indicators may be able to better handle extreme price events. A reasonable goal, especially during times of high volatility. John Ehlers shows how to improve a bandpass filter’s ability to reflect price by limiting the data range. Filtering out the temporary spikes and price extremes should positively affect the indicator stability. Enter a new indicator ——— the Truncated BandPass (BP) filter.
Cumulative indicators, such as the EMA or MACD, are affected not only by previous candles, but by a theoretically infinite history of candles. Although this effect is often assumed to be negligible, John Ehlers demonstrates in his article that it is not so. Or at least not for a narrow-band bandpass filter.
Bandpass filters are normally used for detecting cycles in price curves. But they do not work well with steep edges in the price curve. Sudden price jumps cause a narrow-band filter to “ring like a bell” and generate artificial cycles that can cause false triggers. As a solution, Ehlers proposes to truncate the candle history of the filter. Limiting the history to 10 bars effectively dampened the filter output and produced a better representation of the cycles in the price curve. For limiting the history of a cumulative indicator, John Ehlers proposes “Truncated Indicators,” John Ehlers takes us aside to look at the impact of sharp price movements on two fundamentally different types of filters: finite impulse response, and infinite impulse response filters. Given recent market conditions, this is a very well timed subject.
As demostrated in this script, Ehlers suggests “truncation” as an approach to the way the trader calculates filters. He explains why truncation is not appropriate for finite impulse response filters but why truncation can be beneficial to infinite impulse response filters. He then explains how to apply truncation to infinite impulse response filters using his bandpass filter as an example.
Key Signal
BPT --> Truncated BandPass (BP) Filter fast line
Trigger --> Truncated BandPass (BP) Filter slow line
Pros and Cons
100% John F. Ehlers definition translation, even variable names are the same. This help readers who would like to use pine to read his book.
Remarks
The 98th script for Blackcat1402 John F. Ehlers Week publication.
Readme
In real life, I am a prolific inventor. I have successfully applied for more than 60 international and regional patents in the past 12 years. But in the past two years or so, I have tried to transfer my creativity to the development of trading strategies. Tradingview is the ideal platform for me. I am selecting and contributing some of the hundreds of scripts to publish in Tradingview community. Welcome everyone to interact with me to discuss these interesting pine scripts.
The scripts posted are categorized into 5 levels according to my efforts or manhours put into these works.
Level 1 : interesting script snippets or distinctive improvement from classic indicators or strategy. Level 1 scripts can usually appear in more complex indicators as a function module or element.
Level 2 : composite indicator/strategy. By selecting or combining several independent or dependent functions or sub indicators in proper way, the composite script exhibits a resonance phenomenon which can filter out noise or fake trading signal to enhance trading confidence level.
Level 3 : comprehensive indicator/strategy. They are simple trading systems based on my strategies. They are commonly containing several or all of entry signal, close signal, stop loss, take profit, re-entry, risk management, and position sizing techniques. Even some interesting fundamental and mass psychological aspects are incorporated.
Level 4 : script snippets or functions that do not disclose source code. Interesting element that can reveal market laws and work as raw material for indicators and strategies. If you find Level 1~2 scripts are helpful, Level 4 is a private version that took me far more efforts to develop.
Level 5 : indicator/strategy that do not disclose source code. private version of Level 3 script with my accumulated script processing skills or a large number of custom functions. I had a private function library built in past two years. Level 5 scripts use many of them to achieve private trading strategy.
Volatility Targeting: Single Asset [BackQuant]Volatility Targeting: Single Asset
An educational example that demonstrates how volatility targeting can scale exposure up or down on one symbol, then applies a simple EMA cross for long or short direction and a higher timeframe style regime filter to gate risk. It builds a synthetic equity curve and compares it to buy and hold and a benchmark.
Important disclaimer
This script is a concept and education example only . It is not a complete trading system and it is not meant for live execution. It does not model many real world constraints, and its equity curve is only a simplified simulation. If you want to trade any idea like this, you need a proper strategy() implementation, realistic execution assumptions, and robust backtesting with out of sample validation.
Single asset vs the full portfolio concept
This indicator is the single asset, long short version of the broader volatility targeted momentum portfolio concept. The original multi asset concept and full portfolio implementation is here:
That portfolio script is about allocating across multiple assets with a portfolio view. This script is intentionally simpler and focuses on one symbol so you can clearly see how volatility targeting behaves, how the scaling interacts with trend direction, and what an equity curve comparison looks like.
What this indicator is trying to demonstrate
Volatility targeting is a risk scaling framework. The core idea is simple:
If realized volatility is low relative to a target, you can scale position size up so the strategy behaves like it has a stable risk budget.
If realized volatility is high relative to a target, you scale down to avoid getting blown around by the market.
Instead of always being 1x long or 1x short, exposure becomes dynamic. This is often used in risk parity style systems, trend following overlays, and volatility controlled products.
This script combines that risk scaling with a simple trend direction model:
Fast and slow EMA cross determines whether the strategy is long or short.
A second, longer EMA cross acts as a regime filter that decides whether the system is ACTIVE or effectively in CASH.
An equity curve is built from the scaled returns so you can visualize how the framework behaves across regimes.
How the logic works step by step
1) Returns and simple momentum
The script uses log returns for the base return stream:
ret = log(price / price )
It also computes a simple momentum value:
mom = price / price - 1
In this version, momentum is mainly informational since the directional signal is the EMA cross. The lookback input is shared with volatility estimation to keep the concept compact.
2) Realized volatility estimation
Realized volatility is estimated as the standard deviation of returns over the lookback window, then annualized:
vol = stdev(ret, lookback) * sqrt(tradingdays)
The Trading Days/Year input controls annualization:
252 is typical for traditional markets.
365 is typical for crypto since it trades daily.
3) Volatility targeting multiplier
Once realized vol is estimated, the script computes a scaling factor that tries to push realized volatility toward the target:
volMult = targetVol / vol
This is then clamped into a reasonable range:
Minimum 0.1 so exposure never goes to zero just because vol spikes.
Maximum 5.0 so exposure is not allowed to lever infinitely during ultra low volatility periods.
This clamp is one of the most important “sanity rails” in any volatility targeted system. Without it, very low volatility regimes can create unrealistic leverage.
4) Scaled return stream
The per bar return used for the equity curve is the raw return multiplied by the volatility multiplier:
sr = ret * volMult
Think of this as the return you would have earned if you scaled exposure to match the volatility budget.
5) Long short direction via EMA cross
Direction is determined by a fast and slow EMA cross on price:
If fast EMA is above slow EMA, direction is long.
If fast EMA is below slow EMA, direction is short.
This produces dir as either +1 or -1. The scaled return stream is then signed by direction:
avgRet = dir * sr
So the strategy return is volatility targeted and directionally flipped depending on trend.
6) Regime filter: ACTIVE vs CASH
A second EMA pair acts as a top level regime filter:
If fast regime EMA is above slow regime EMA, the system is ACTIVE.
If fast regime EMA is below slow regime EMA, the system is considered CASH, meaning it does not compound equity.
This is designed to reduce participation in long bear phases or low quality environments, depending on how you set the regime lengths. By default it is a classic 50 and 200 EMA cross structure.
Important detail, the script applies regime_filter when compounding equity, meaning it uses the prior bar regime state to avoid ambiguous same bar updates.
7) Equity curve construction
The script builds a synthetic equity curve starting from Initial Capital after Start Date . Each bar:
If regime was ACTIVE on the previous bar, equity compounds by (1 + netRet).
If regime was CASH, equity stays flat.
Fees are modeled very simply as a per bar penalty on returns:
netRet = avgRet - (fee_rate * avgRet)
This is not realistic execution modeling, it is just a simple turnover penalty knob to show how friction can reduce compounded performance. Real backtesting should model trade based costs, spreads, funding, and slippage.
Benchmark and buy and hold comparison
The script pulls a benchmark symbol via request.security and builds a buy and hold equity curve starting from the same date and initial capital. The buy and hold curve is based on benchmark price appreciation, not the strategy’s asset price, so you can compare:
Strategy equity on the chart symbol.
Buy and hold equity for the selected benchmark instrument.
By default the benchmark is TVC:SPX, but you can set it to anything, for crypto you might set it to BTC, or a sector index, or a dominance proxy depending on your study.
What it plots
If enabled, the indicator plots:
Strategy Equity as a line, colored by recent direction of equity change, using Positive Equity Color and Negative Equity Color .
Buy and Hold Equity for the chosen benchmark as a line.
Optional labels that tag each curve on the right side of the chart.
This makes it easy to visually see when volatility targeting and regime gating change the shape of the equity curve relative to a simple passive hold.
Metrics table explained
If Show Metrics Table is enabled, a table is built and populated with common performance statistics based on the simulated daily returns of the strategy equity curve after the start date. These include:
Net Profit (%) total return relative to initial capital.
Max DD (%) maximum drawdown computed from equity peaks, stored over time.
Win Rate percent of positive return bars.
Annual Mean Returns (% p/y) mean daily return annualized.
Annual Stdev Returns (% p/y) volatility of daily returns annualized.
Variance of annualized returns.
Sortino Ratio annualized return divided by downside deviation, using negative return stdev.
Sharpe Ratio risk adjusted return using the risk free rate input.
Omega Ratio positive return sum divided by negative return sum.
Gain to Pain total return sum divided by absolute loss sum.
CAGR (% p/y) compounded annual growth rate based on time since start date.
Portfolio Alpha (% p/y) alpha versus benchmark using beta and the benchmark mean.
Portfolio Beta covariance of strategy returns with benchmark returns divided by benchmark variance.
Skewness of Returns actually the script computes a conditional value based on the lower 5 percent tail of returns, so it behaves more like a simple CVaR style tail loss estimate than classic skewness.
Important note, these are calculated from the synthetic equity stream in an indicator context. They are useful for concept exploration, but they are not a substitute for professional backtesting where trade timing, fills, funding, and leverage constraints are accurately represented.
How to interpret the system conceptually
Vol targeting effect
When volatility rises, volMult falls, so the strategy de risks and the equity curve typically becomes smoother. When volatility compresses, volMult rises, so the system takes more exposure and tries to maintain a stable risk budget.
This is why volatility targeting is often used as a “risk equalizer”, it can reduce the “biggest drawdowns happen only because vol expanded” problem, at the cost of potentially under participating in explosive upside if volatility rises during a trend.
Long short directional effect
Because direction is an EMA cross:
In strong trends, the direction stays stable and the scaled return stream compounds in that trend direction.
In choppy ranges, the EMA cross can flip and create whipsaws, which is where fees and regime filtering matter most.
Regime filter effect
The 50 and 200 style filter tries to:
Keep the system active in sustained up regimes.
Reduce exposure during long down regimes or extended weakness.
It will always be late at turning points, by design. It is a slow filter meant to reduce deep participation, not to catch bottoms.
Common applications
This script is mainly for understanding and research, but conceptually, volatility targeting overlays are used for:
Risk budgeting normalize risk so your exposure is not accidentally huge in high vol regimes.
System comparison see how a simple trend model behaves with and without vol scaling.
Parameter exploration test how target volatility, lookback length, and regime lengths change the shape of equity and drawdowns.
Framework building as a reference blueprint before implementing a proper strategy() version with trade based execution logic.
Tuning guidance
Lookback lower values react faster to vol shifts but can create unstable scaling, higher values smooth scaling but react slower to regime changes.
Target volatility higher targets increase exposure and drawdown potential, lower targets reduce exposure and usually lower drawdowns, but can under perform in strong trends.
Signal EMAs tighter EMAs increase trade frequency, wider EMAs reduce churn but react slower.
Regime EMAs slower regime filters reduce false toggles but will miss early trend transitions.
Fees if you crank this up you will see how sensitive higher turnover parameter sets are to friction.
Final note
This is a compact educational demonstration of a volatility targeted, long short single asset framework with a regime gate and a synthetic equity curve. If you want a production ready implementation, the correct next step is to convert this concept into a strategy() script, add realistic execution and cost modeling, test across multiple timeframes and market regimes, and validate out of sample before making any decision based on the results.

ALMA v1 ATR Bands With Trend BarsALMA v1 ATR Bands With Trend Bars is a trend-context overlay indicator designed to visualize price structure, momentum direction, and volatility expansion directly on the chart.
It combines the Arnaud Legoux Moving Average (ALMA) with ATR-based dynamic bands and a dual-momentum bar-coloring model, providing a clear visual framework for interpreting trend conditions without compressing market behavior into a single decision output.
Conceptual Architecture
The indicator is built around three complementary layers, each serving a distinct analytical role:
1. ALMA Trend Curve
The core trend line is computed using the Arnaud Legoux Moving Average, which emphasizes responsiveness while maintaining smoothness through controlled offset and sigma parameters.
An optional adaptive filter suppresses minor fluctuations, allowing the curve to focus on structural price movement rather than short-term noise.
Color changes in the ALMA line reflect directional slope state, not trading actions.
2. ATR Volatility Bands
ATR-based bands are calculated around the filtered ALMA curve:
The bands expand and contract dynamically with volatility.
They provide a contextual envelope that helps visualize price dispersion relative to the underlying trend.
These bands are intended as a volatility reference, not fixed support or resistance levels.
3. Trend Bars (Momentum State Layer)
Price candles are recolored using a dual-CCI momentum model:
A fast and a slow CCI operate together to classify momentum agreement.
When both momentum measures align, bars reflect directional bias.
When momentum disagrees, bars shift to a neutral state.
This layer highlights momentum consistency, not execution timing.
Trend State Visualization:
Discrete visual markers may appear when the slope direction of the ALMA curve changes.
These markers indicate structural trend transitions based on confirmed bar closes and do not repaint.
They are intended to support visual interpretation of trend evolution, not to automate decisions.
Reliability:
No repainting: all states, colors, and markers are confirmed on bar close.
Consistent behavior across instruments and timeframes.
Designed for stable visual output during live market conditions.
Customization Options:
ALMA length, offset, sigma, and optional shift.
Adaptive filtering sensitivity.
ATR period and deviation multiplier.
Momentum sensitivity modes for bar coloring.
Fully customizable color palette.
Optional alerts for structural trend changes.

Dynamic Equity Allocation Model"Cash is Trash"? Not Always. Here's Why Science Beats Guesswork.
Every retail trader knows the frustration: you draw support and resistance lines, you spot patterns, you follow market gurus on social media—and still, when the next bear market hits, your portfolio bleeds red. Meanwhile, institutional investors seem to navigate market turbulence with ease, preserving capital when markets crash and participating when they rally. What's their secret?
The answer isn't insider information or access to exotic derivatives. It's systematic, scientifically validated decision-making. While most retail traders rely on subjective chart analysis and emotional reactions, professional portfolio managers use quantitative models that remove emotion from the equation and process multiple streams of market information simultaneously.
This document presents exactly such a system—not a proprietary black box available only to hedge funds, but a fully transparent, academically grounded framework that any serious investor can understand and apply. The Dynamic Equity Allocation Model (DEAM) synthesizes decades of financial research from Nobel laureates and leading academics into a practical tool for tactical asset allocation.
Stop drawing colorful lines on your chart and start thinking like a quant. This isn't about predicting where the market goes next week—it's about systematically adjusting your risk exposure based on what the data actually tells you. When valuations scream danger, when volatility spikes, when credit markets freeze, when multiple warning signals align—that's when cash isn't trash. That's when cash saves your portfolio.
The irony of "cash is trash" rhetoric is that it ignores timing. Yes, being 100% cash for decades would be disastrous. But being 100% equities through every crisis is equally foolish. The sophisticated approach is dynamic: aggressive when conditions favor risk-taking, defensive when they don't. This model shows you how to make that decision systematically, not emotionally.
Whether you're managing your own retirement portfolio or seeking to understand how institutional allocation strategies work, this comprehensive analysis provides the theoretical foundation, mathematical implementation, and practical guidance to elevate your investment approach from amateur to professional.
The choice is yours: keep hoping your chart patterns work out, or start using the same quantitative methods that professionals rely on. The tools are here. The research is cited. The methodology is explained. All you need to do is read, understand, and apply.
The Dynamic Equity Allocation Model (DEAM) is a quantitative framework for systematic allocation between equities and cash, grounded in modern portfolio theory and empirical market research. The model integrates five scientifically validated dimensions of market analysis—market regime, risk metrics, valuation, sentiment, and macroeconomic conditions—to generate dynamic allocation recommendations ranging from 0% to 100% equity exposure. This work documents the theoretical foundations, mathematical implementation, and practical application of this multi-factor approach.
1. Introduction and Theoretical Background
1.1 The Limitations of Static Portfolio Allocation
Traditional portfolio theory, as formulated by Markowitz (1952) in his seminal work "Portfolio Selection," assumes an optimal static allocation where investors distribute their wealth across asset classes according to their risk aversion. This approach rests on the assumption that returns and risks remain constant over time. However, empirical research demonstrates that this assumption does not hold in reality. Fama and French (1989) showed that expected returns vary over time and correlate with macroeconomic variables such as the spread between long-term and short-term interest rates. Campbell and Shiller (1988) demonstrated that the price-earnings ratio possesses predictive power for future stock returns, providing a foundation for dynamic allocation strategies.
The academic literature on tactical asset allocation has evolved considerably over recent decades. Ilmanen (2011) argues in "Expected Returns" that investors can improve their risk-adjusted returns by considering valuation levels, business cycles, and market sentiment. The Dynamic Equity Allocation Model presented here builds on this research tradition and operationalizes these insights into a practically applicable allocation framework.
1.2 Multi-Factor Approaches in Asset Allocation
Modern financial research has shown that different factors capture distinct aspects of market dynamics and together provide a more robust picture of market conditions than individual indicators. Ross (1976) developed the Arbitrage Pricing Theory, a model that employs multiple factors to explain security returns. Following this multi-factor philosophy, DEAM integrates five complementary analytical dimensions, each tapping different information sources and collectively enabling comprehensive market understanding.
2. Data Foundation and Data Quality
2.1 Data Sources Used
The model draws its data exclusively from publicly available market data via the TradingView platform. This transparency and accessibility is a significant advantage over proprietary models that rely on non-public data. The data foundation encompasses several categories of market information, each capturing specific aspects of market dynamics.
First, price data for the S&P 500 Index is obtained through the SPDR S&P 500 ETF (ticker: SPY). The use of a highly liquid ETF instead of the index itself has practical reasons, as ETF data is available in real-time and reflects actual tradability. In addition to closing prices, high, low, and volume data are captured, which are required for calculating advanced volatility measures.
Fundamental corporate metrics are retrieved via TradingView's Financial Data API. These include earnings per share, price-to-earnings ratio, return on equity, debt-to-equity ratio, dividend yield, and share buyback yield. Cochrane (2011) emphasizes in "Presidential Address: Discount Rates" the central importance of valuation metrics for forecasting future returns, making these fundamental data a cornerstone of the model.
Volatility indicators are represented by the CBOE Volatility Index (VIX) and related metrics. The VIX, often referred to as the market's "fear gauge," measures the implied volatility of S&P 500 index options and serves as a proxy for market participants' risk perception. Whaley (2000) describes in "The Investor Fear Gauge" the construction and interpretation of the VIX and its use as a sentiment indicator.
Macroeconomic data includes yield curve information through US Treasury bonds of various maturities and credit risk premiums through the spread between high-yield bonds and risk-free government bonds. These variables capture the macroeconomic conditions and financing conditions relevant for equity valuation. Estrella and Hardouvelis (1991) showed that the shape of the yield curve has predictive power for future economic activity, justifying the inclusion of these data.
2.2 Handling Missing Data
A practical problem when working with financial data is dealing with missing or unavailable values. The model implements a fallback system where a plausible historical average value is stored for each fundamental metric. When current data is unavailable for a specific point in time, this fallback value is used. This approach ensures that the model remains functional even during temporary data outages and avoids systematic biases from missing data. The use of average values as fallback is conservative, as it generates neither overly optimistic nor pessimistic signals.
3. Component 1: Market Regime Detection
3.1 The Concept of Market Regimes
The idea that financial markets exist in different "regimes" or states that differ in their statistical properties has a long tradition in financial science. Hamilton (1989) developed regime-switching models that allow distinguishing between different market states with different return and volatility characteristics. The practical application of this theory consists of identifying the current market state and adjusting portfolio allocation accordingly.
DEAM classifies market regimes using a scoring system that considers three main dimensions: trend strength, volatility level, and drawdown depth. This multidimensional view is more robust than focusing on individual indicators, as it captures various facets of market dynamics. Classification occurs into six distinct regimes: Strong Bull, Bull Market, Neutral, Correction, Bear Market, and Crisis.
3.2 Trend Analysis Through Moving Averages
Moving averages are among the oldest and most widely used technical indicators and have also received attention in academic literature. Brock, Lakonishok, and LeBaron (1992) examined in "Simple Technical Trading Rules and the Stochastic Properties of Stock Returns" the profitability of trading rules based on moving averages and found evidence for their predictive power, although later studies questioned the robustness of these results when considering transaction costs.
The model calculates three moving averages with different time windows: a 20-day average (approximately one trading month), a 50-day average (approximately one quarter), and a 200-day average (approximately one trading year). The relationship of the current price to these averages and the relationship of the averages to each other provide information about trend strength and direction. When the price trades above all three averages and the short-term average is above the long-term, this indicates an established uptrend. The model assigns points based on these constellations, with longer-term trends weighted more heavily as they are considered more persistent.
3.3 Volatility Regimes
Volatility, understood as the standard deviation of returns, is a central concept of financial theory and serves as the primary risk measure. However, research has shown that volatility is not constant but changes over time and occurs in clusters—a phenomenon first documented by Mandelbrot (1963) and later formalized through ARCH and GARCH models (Engle, 1982; Bollerslev, 1986).
DEAM calculates volatility not only through the classic method of return standard deviation but also uses more advanced estimators such as the Parkinson estimator and the Garman-Klass estimator. These methods utilize intraday information (high and low prices) and are more efficient than simple close-to-close volatility estimators. The Parkinson estimator (Parkinson, 1980) uses the range between high and low of a trading day and is based on the recognition that this information reveals more about true volatility than just the closing price difference. The Garman-Klass estimator (Garman and Klass, 1980) extends this approach by additionally considering opening and closing prices.
The calculated volatility is annualized by multiplying it by the square root of 252 (the average number of trading days per year), enabling standardized comparability. The model compares current volatility with the VIX, the implied volatility from option prices. A low VIX (below 15) signals market comfort and increases the regime score, while a high VIX (above 35) indicates market stress and reduces the score. This interpretation follows the empirical observation that elevated volatility is typically associated with falling markets (Schwert, 1989).
3.4 Drawdown Analysis
A drawdown refers to the percentage decline from the highest point (peak) to the lowest point (trough) during a specific period. This metric is psychologically significant for investors as it represents the maximum loss experienced. Calmar (1991) developed the Calmar Ratio, which relates return to maximum drawdown, underscoring the practical relevance of this metric.
The model calculates current drawdown as the percentage distance from the highest price of the last 252 trading days (one year). A drawdown below 3% is considered negligible and maximally increases the regime score. As drawdown increases, the score decreases progressively, with drawdowns above 20% classified as severe and indicating a crisis or bear market regime. These thresholds are empirically motivated by historical market cycles, in which corrections typically encompassed 5-10% drawdowns, bear markets 20-30%, and crises over 30%.
3.5 Regime Classification
Final regime classification occurs through aggregation of scores from trend (40% weight), volatility (30%), and drawdown (30%). The higher weighting of trend reflects the empirical observation that trend-following strategies have historically delivered robust results (Moskowitz, Ooi, and Pedersen, 2012). A total score above 80 signals a strong bull market with established uptrend, low volatility, and minimal losses. At a score below 10, a crisis situation exists requiring defensive positioning. The six regime categories enable a differentiated allocation strategy that not only distinguishes binarily between bullish and bearish but allows gradual gradations.
4. Component 2: Risk-Based Allocation
4.1 Volatility Targeting as Risk Management Approach
The concept of volatility targeting is based on the idea that investors should maximize not returns but risk-adjusted returns. Sharpe (1966, 1994) defined with the Sharpe Ratio the fundamental concept of return per unit of risk, measured as volatility. Volatility targeting goes a step further and adjusts portfolio allocation to achieve constant target volatility. This means that in times of low market volatility, equity allocation is increased, and in times of high volatility, it is reduced.
Moreira and Muir (2017) showed in "Volatility-Managed Portfolios" that strategies that adjust their exposure based on volatility forecasts achieve higher Sharpe Ratios than passive buy-and-hold strategies. DEAM implements this principle by defining a target portfolio volatility (default 12% annualized) and adjusting equity allocation to achieve it. The mathematical foundation is simple: if market volatility is 20% and target volatility is 12%, equity allocation should be 60% (12/20 = 0.6), with the remaining 40% held in cash with zero volatility.
4.2 Market Volatility Calculation
Estimating current market volatility is central to the risk-based allocation approach. The model uses several volatility estimators in parallel and selects the higher value between traditional close-to-close volatility and the Parkinson estimator. This conservative choice ensures the model does not underestimate true volatility, which could lead to excessive risk exposure.
Traditional volatility calculation uses logarithmic returns, as these have mathematically advantageous properties (additive linkage over multiple periods). The logarithmic return is calculated as ln(P_t / P_{t-1}), where P_t is the price at time t. The standard deviation of these returns over a rolling 20-trading-day window is then multiplied by √252 to obtain annualized volatility. This annualization is based on the assumption of independently identically distributed returns, which is an idealization but widely accepted in practice.
The Parkinson estimator uses additional information from the trading range (High minus Low) of each day. The formula is: σ_P = (1/√(4ln2)) × √(1/n × Σln²(H_i/L_i)) × √252, where H_i and L_i are high and low prices. Under ideal conditions, this estimator is approximately five times more efficient than the close-to-close estimator (Parkinson, 1980), as it uses more information per observation.
4.3 Drawdown-Based Position Size Adjustment
In addition to volatility targeting, the model implements drawdown-based risk control. The logic is that deep market declines often signal further losses and therefore justify exposure reduction. This behavior corresponds with the concept of path-dependent risk tolerance: investors who have already suffered losses are typically less willing to take additional risk (Kahneman and Tversky, 1979).
The model defines a maximum portfolio drawdown as a target parameter (default 15%). Since portfolio volatility and portfolio drawdown are proportional to equity allocation (assuming cash has neither volatility nor drawdown), allocation-based control is possible. For example, if the market exhibits a 25% drawdown and target portfolio drawdown is 15%, equity allocation should be at most 60% (15/25).
4.4 Dynamic Risk Adjustment
An advanced feature of DEAM is dynamic adjustment of risk-based allocation through a feedback mechanism. The model continuously estimates what actual portfolio volatility and portfolio drawdown would result at the current allocation. If risk utilization (ratio of actual to target risk) exceeds 1.0, allocation is reduced by an adjustment factor that grows exponentially with overutilization. This implements a form of dynamic feedback that avoids overexposure.
Mathematically, a risk adjustment factor r_adjust is calculated: if risk utilization u > 1, then r_adjust = exp(-0.5 × (u - 1)). This exponential function ensures that moderate overutilization is gently corrected, while strong overutilization triggers drastic reductions. The factor 0.5 in the exponent was empirically calibrated to achieve a balanced ratio between sensitivity and stability.
5. Component 3: Valuation Analysis
5.1 Theoretical Foundations of Fundamental Valuation
DEAM's valuation component is based on the fundamental premise that the intrinsic value of a security is determined by its future cash flows and that deviations between market price and intrinsic value are eventually corrected. Graham and Dodd (1934) established in "Security Analysis" the basic principles of fundamental analysis that remain relevant today. Translated into modern portfolio context, this means that markets with high valuation metrics (high price-earnings ratios) should have lower expected returns than cheaply valued markets.
Campbell and Shiller (1988) developed the Cyclically Adjusted P/E Ratio (CAPE), which smooths earnings over a full business cycle. Their empirical analysis showed that this ratio has significant predictive power for 10-year returns. Asness, Moskowitz, and Pedersen (2013) demonstrated in "Value and Momentum Everywhere" that value effects exist not only in individual stocks but also in asset classes and markets.
5.2 Equity Risk Premium as Central Valuation Metric
The Equity Risk Premium (ERP) is defined as the expected excess return of stocks over risk-free government bonds. It is the theoretical heart of valuation analysis, as it represents the compensation investors demand for bearing equity risk. Damodaran (2012) discusses in "Equity Risk Premiums: Determinants, Estimation and Implications" various methods for ERP estimation.
DEAM calculates ERP not through a single method but combines four complementary approaches with different weights. This multi-method strategy increases estimation robustness and avoids dependence on single, potentially erroneous inputs.
The first method (35% weight) uses earnings yield, calculated as 1/P/E or directly from operating earnings data, and subtracts the 10-year Treasury yield. This method follows Fed Model logic (Yardeni, 2003), although this model has theoretical weaknesses as it does not consistently treat inflation (Asness, 2003).
The second method (30% weight) extends earnings yield by share buyback yield. Share buybacks are a form of capital return to shareholders and increase value per share. Boudoukh et al. (2007) showed in "The Total Shareholder Yield" that the sum of dividend yield and buyback yield is a better predictor of future returns than dividend yield alone.
The third method (20% weight) implements the Gordon Growth Model (Gordon, 1962), which models stock value as the sum of discounted future dividends. Under constant growth g assumption: Expected Return = Dividend Yield + g. The model estimates sustainable growth as g = ROE × (1 - Payout Ratio), where ROE is return on equity and payout ratio is the ratio of dividends to earnings. This formula follows from equity theory: unretained earnings are reinvested at ROE and generate additional earnings growth.
The fourth method (15% weight) combines total shareholder yield (Dividend + Buybacks) with implied growth derived from revenue growth. This method considers that companies with strong revenue growth should generate higher future earnings, even if current valuations do not yet fully reflect this.
The final ERP is the weighted average of these four methods. A high ERP (above 4%) signals attractive valuations and increases the valuation score to 95 out of 100 possible points. A negative ERP, where stocks have lower expected returns than bonds, results in a minimal score of 10.
5.3 Quality Adjustments to Valuation
Valuation metrics alone can be misleading if not interpreted in the context of company quality. A company with a low P/E may be cheap or fundamentally problematic. The model therefore implements quality adjustments based on growth, profitability, and capital structure.
Revenue growth above 10% annually adds 10 points to the valuation score, moderate growth above 5% adds 5 points. This adjustment reflects that growth has independent value (Modigliani and Miller, 1961, extended by later growth theory). Net margin above 15% signals pricing power and operational efficiency and increases the score by 5 points, while low margins below 8% indicate competitive pressure and subtract 5 points.
Return on equity (ROE) above 20% characterizes outstanding capital efficiency and increases the score by 5 points. Piotroski (2000) showed in "Value Investing: The Use of Historical Financial Statement Information" that fundamental quality signals such as high ROE can improve the performance of value strategies.
Capital structure is evaluated through the debt-to-equity ratio. A conservative ratio below 1.0 multiplies the valuation score by 1.2, while high leverage above 2.0 applies a multiplier of 0.8. This adjustment reflects that high debt constrains financial flexibility and can become problematic in crisis times (Korteweg, 2010).
6. Component 4: Sentiment Analysis
6.1 The Role of Sentiment in Financial Markets
Investor sentiment, defined as the collective psychological attitude of market participants, influences asset prices independently of fundamental data. Baker and Wurgler (2006, 2007) developed a sentiment index and showed that periods of high sentiment are followed by overvaluations that later correct. This insight justifies integrating a sentiment component into allocation decisions.
Sentiment is difficult to measure directly but can be proxied through market indicators. The VIX is the most widely used sentiment indicator, as it aggregates implied volatility from option prices. High VIX values reflect elevated uncertainty and risk aversion, while low values signal market comfort. Whaley (2009) refers to the VIX as the "Investor Fear Gauge" and documents its role as a contrarian indicator: extremely high values typically occur at market bottoms, while low values occur at tops.
6.2 VIX-Based Sentiment Assessment
DEAM uses statistical normalization of the VIX by calculating the Z-score: z = (VIX_current - VIX_average) / VIX_standard_deviation. The Z-score indicates how many standard deviations the current VIX is from the historical average. This approach is more robust than absolute thresholds, as it adapts to the average volatility level, which can vary over longer periods.
A Z-score below -1.5 (VIX is 1.5 standard deviations below average) signals exceptionally low risk perception and adds 40 points to the sentiment score. This may seem counterintuitive—shouldn't low fear be bullish? However, the logic follows the contrarian principle: when no one is afraid, everyone is already invested, and there is limited further upside potential (Zweig, 1973). Conversely, a Z-score above 1.5 (extreme fear) adds -40 points, reflecting market panic but simultaneously suggesting potential buying opportunities.
6.3 VIX Term Structure as Sentiment Signal
The VIX term structure provides additional sentiment information. Normally, the VIX trades in contango, meaning longer-term VIX futures have higher prices than short-term. This reflects that short-term volatility is currently known, while long-term volatility is more uncertain and carries a risk premium. The model compares the VIX with VIX9D (9-day volatility) and identifies backwardation (VIX > 1.05 × VIX9D) and steep backwardation (VIX > 1.15 × VIX9D).
Backwardation occurs when short-term implied volatility is higher than longer-term, which typically happens during market stress. Investors anticipate immediate turbulence but expect calming. Psychologically, this reflects acute fear. The model subtracts 15 points for backwardation and 30 for steep backwardation, as these constellations signal elevated risk. Simon and Wiggins (2001) analyzed the VIX futures curve and showed that backwardation is associated with market declines.
6.4 Safe-Haven Flows
During crisis times, investors flee from risky assets into safe havens: gold, US dollar, and Japanese yen. This "flight to quality" is a sentiment signal. The model calculates the performance of these assets relative to stocks over the last 20 trading days. When gold or the dollar strongly rise while stocks fall, this indicates elevated risk aversion.
The safe-haven component is calculated as the difference between safe-haven performance and stock performance. Positive values (safe havens outperform) subtract up to 20 points from the sentiment score, negative values (stocks outperform) add up to 10 points. The asymmetric treatment (larger deduction for risk-off than bonus for risk-on) reflects that risk-off movements are typically sharper and more informative than risk-on phases.
Baur and Lucey (2010) examined safe-haven properties of gold and showed that gold indeed exhibits negative correlation with stocks during extreme market movements, confirming its role as crisis protection.
7. Component 5: Macroeconomic Analysis
7.1 The Yield Curve as Economic Indicator
The yield curve, represented as yields of government bonds of various maturities, contains aggregated expectations about future interest rates, inflation, and economic growth. The slope of the yield curve has remarkable predictive power for recessions. Estrella and Mishkin (1998) showed that an inverted yield curve (short-term rates higher than long-term) predicts recessions with high reliability. This is because inverted curves reflect restrictive monetary policy: the central bank raises short-term rates to combat inflation, dampening economic activity.
DEAM calculates two spread measures: the 2-year-minus-10-year spread and the 3-month-minus-10-year spread. A steep, positive curve (spreads above 1.5% and 2% respectively) signals healthy growth expectations and generates the maximum yield curve score of 40 points. A flat curve (spreads near zero) reduces the score to 20 points. An inverted curve (negative spreads) is particularly alarming and results in only 10 points.
The choice of two different spreads increases analysis robustness. The 2-10 spread is most established in academic literature, while the 3M-10Y spread is often considered more sensitive, as the 3-month rate directly reflects current monetary policy (Ang, Piazzesi, and Wei, 2006).
7.2 Credit Conditions and Spreads
Credit spreads—the yield difference between risky corporate bonds and safe government bonds—reflect risk perception in the credit market. Gilchrist and Zakrajšek (2012) constructed an "Excess Bond Premium" that measures the component of credit spreads not explained by fundamentals and showed this is a predictor of future economic activity and stock returns.
The model approximates credit spread by comparing the yield of high-yield bond ETFs (HYG) with investment-grade bond ETFs (LQD). A narrow spread below 200 basis points signals healthy credit conditions and risk appetite, contributing 30 points to the macro score. Very wide spreads above 1000 basis points (as during the 2008 financial crisis) signal credit crunch and generate zero points.
Additionally, the model evaluates whether "flight to quality" is occurring, identified through strong performance of Treasury bonds (TLT) with simultaneous weakness in high-yield bonds. This constellation indicates elevated risk aversion and reduces the credit conditions score.
7.3 Financial Stability at Corporate Level
While the yield curve and credit spreads reflect macroeconomic conditions, financial stability evaluates the health of companies themselves. The model uses the aggregated debt-to-equity ratio and return on equity of the S&P 500 as proxies for corporate health.
A low leverage level below 0.5 combined with high ROE above 15% signals robust corporate balance sheets and generates 20 points. This combination is particularly valuable as it represents both defensive strength (low debt means crisis resistance) and offensive strength (high ROE means earnings power). High leverage above 1.5 generates only 5 points, as it implies vulnerability to interest rate increases and recessions.
Korteweg (2010) showed in "The Net Benefits to Leverage" that optimal debt maximizes firm value, but excessive debt increases distress costs. At the aggregated market level, high debt indicates fragilities that can become problematic during stress phases.
8. Component 6: Crisis Detection
8.1 The Need for Systematic Crisis Detection
Financial crises are rare but extremely impactful events that suspend normal statistical relationships. During normal market volatility, diversified portfolios and traditional risk management approaches function, but during systemic crises, seemingly independent assets suddenly correlate strongly, and losses exceed historical expectations (Longin and Solnik, 2001). This justifies a separate crisis detection mechanism that operates independently of regular allocation components.
Reinhart and Rogoff (2009) documented in "This Time Is Different: Eight Centuries of Financial Folly" recurring patterns in financial crises: extreme volatility, massive drawdowns, credit market dysfunction, and asset price collapse. DEAM operationalizes these patterns into quantifiable crisis indicators.
8.2 Multi-Signal Crisis Identification
The model uses a counter-based approach where various stress signals are identified and aggregated. This methodology is more robust than relying on a single indicator, as true crises typically occur simultaneously across multiple dimensions. A single signal may be a false alarm, but the simultaneous presence of multiple signals increases confidence.
The first indicator is a VIX above the crisis threshold (default 40), adding one point. A VIX above 60 (as in 2008 and March 2020) adds two additional points, as such extreme values are historically very rare. This tiered approach captures the intensity of volatility.
The second indicator is market drawdown. A drawdown above 15% adds one point, as corrections of this magnitude can be potential harbingers of larger crises. A drawdown above 25% adds another point, as historical bear markets typically encompass 25-40% drawdowns.
The third indicator is credit market spreads above 500 basis points, adding one point. Such wide spreads occur only during significant credit market disruptions, as in 2008 during the Lehman crisis.
The fourth indicator identifies simultaneous losses in stocks and bonds. Normally, Treasury bonds act as a hedge against equity risk (negative correlation), but when both fall simultaneously, this indicates systemic liquidity problems or inflation/stagflation fears. The model checks whether both SPY and TLT have fallen more than 10% and 5% respectively over 5 trading days, adding two points.
The fifth indicator is a volume spike combined with negative returns. Extreme trading volumes (above twice the 20-day average) with falling prices signal panic selling. This adds one point.
A crisis situation is diagnosed when at least 3 indicators trigger, a severe crisis at 5 or more indicators. These thresholds were calibrated through historical backtesting to identify true crises (2008, 2020) without generating excessive false alarms.
8.3 Crisis-Based Allocation Override
When a crisis is detected, the system overrides the normal allocation recommendation and caps equity allocation at maximum 25%. In a severe crisis, the cap is set at 10%. This drastic defensive posture follows the empirical observation that crises typically require time to develop and that early reduction can avoid substantial losses (Faber, 2007).
This override logic implements a "safety first" principle: in situations of existential danger to the portfolio, capital preservation becomes the top priority. Roy (1952) formalized this approach in "Safety First and the Holding of Assets," arguing that investors should primarily minimize ruin probability.
9. Integration and Final Allocation Calculation
9.1 Component Weighting
The final allocation recommendation emerges through weighted aggregation of the five components. The standard weighting is: Market Regime 35%, Risk Management 25%, Valuation 20%, Sentiment 15%, Macro 5%. These weights reflect both theoretical considerations and empirical backtesting results.
The highest weighting of market regime is based on evidence that trend-following and momentum strategies have delivered robust results across various asset classes and time periods (Moskowitz, Ooi, and Pedersen, 2012). Current market momentum is highly informative for the near future, although it provides no information about long-term expectations.
The substantial weighting of risk management (25%) follows from the central importance of risk control. Wealth preservation is the foundation of long-term wealth creation, and systematic risk management is demonstrably value-creating (Moreira and Muir, 2017).
The valuation component receives 20% weight, based on the long-term mean reversion of valuation metrics. While valuation has limited short-term predictive power (bull and bear markets can begin at any valuation), the long-term relationship between valuation and returns is robustly documented (Campbell and Shiller, 1988).
Sentiment (15%) and Macro (5%) receive lower weights, as these factors are subtler and harder to measure. Sentiment is valuable as a contrarian indicator at extremes but less informative in normal ranges. Macro variables such as the yield curve have strong predictive power for recessions, but the transmission from recessions to stock market performance is complex and temporally variable.
9.2 Model Type Adjustments
DEAM allows users to choose between four model types: Conservative, Balanced, Aggressive, and Adaptive. This choice modifies the final allocation through additive adjustments.
Conservative mode subtracts 10 percentage points from allocation, resulting in consistently more cautious positioning. This is suitable for risk-averse investors or those with limited investment horizons. Aggressive mode adds 10 percentage points, suitable for risk-tolerant investors with long horizons.
Adaptive mode implements procyclical adjustment based on short-term momentum: if the market has risen more than 5% in the last 20 days, 5 percentage points are added; if it has declined more than 5%, 5 points are subtracted. This logic follows the observation that short-term momentum persists (Jegadeesh and Titman, 1993), but the moderate size of adjustment avoids excessive timing bets.
Balanced mode makes no adjustment and uses raw model output. This neutral setting is suitable for investors who wish to trust model recommendations unchanged.
9.3 Smoothing and Stability
The allocation resulting from aggregation undergoes final smoothing through a simple moving average over 3 periods. This smoothing is crucial for model practicality, as it reduces frequent trading and thus transaction costs. Without smoothing, the model could fluctuate between adjacent allocations with every small input change.
The choice of 3 periods as smoothing window is a compromise between responsiveness and stability. Longer smoothing would excessively delay signals and impede response to true regime changes. Shorter or no smoothing would allow too much noise. Empirical tests showed that 3-period smoothing offers an optimal ratio between these goals.
10. Visualization and Interpretation
10.1 Main Output: Equity Allocation
DEAM's primary output is a time series from 0 to 100 representing the recommended percentage allocation to equities. This representation is intuitive: 100% means full investment in stocks (specifically: an S&P 500 ETF), 0% means complete cash position, and intermediate values correspond to mixed portfolios. A value of 60% means, for example: invest 60% of wealth in SPY, hold 40% in money market instruments or cash.
The time series is color-coded to enable quick visual interpretation. Green shades represent high allocations (above 80%, bullish), red shades low allocations (below 20%, bearish), and neutral colors middle allocations. The chart background is dynamically colored based on the signal, enhancing readability in different market phases.
10.2 Dashboard Metrics
A tabular dashboard presents key metrics compactly. This includes current allocation, cash allocation (complement), an aggregated signal (BULLISH/NEUTRAL/BEARISH), current market regime, VIX level, market drawdown, and crisis status.
Additionally, fundamental metrics are displayed: P/E Ratio, Equity Risk Premium, Return on Equity, Debt-to-Equity Ratio, and Total Shareholder Yield. This transparency allows users to understand model decisions and form their own assessments.
Component scores (Regime, Risk, Valuation, Sentiment, Macro) are also displayed, each normalized on a 0-100 scale. This shows which factors primarily drive the current recommendation. If, for example, the Risk score is very low (20) while other scores are moderate (50-60), this indicates that risk management considerations are pulling allocation down.
10.3 Component Breakdown (Optional)
Advanced users can display individual components as separate lines in the chart. This enables analysis of component dynamics: do all components move synchronously, or are there divergences? Divergences can be particularly informative. If, for example, the market regime is bullish (high score) but the valuation component is very negative, this signals an overbought market not fundamentally supported—a classic "bubble warning."
This feature is disabled by default to keep the chart clean but can be activated for deeper analysis.
10.4 Confidence Bands
The model optionally displays uncertainty bands around the main allocation line. These are calculated as ±1 standard deviation of allocation over a rolling 20-period window. Wide bands indicate high volatility of model recommendations, suggesting uncertain market conditions. Narrow bands indicate stable recommendations.
This visualization implements a concept of epistemic uncertainty—uncertainty about the model estimate itself, not just market volatility. In phases where various indicators send conflicting signals, the allocation recommendation becomes more volatile, manifesting in wider bands. Users can understand this as a warning to act more cautiously or consult alternative information sources.
11. Alert System
11.1 Allocation Alerts
DEAM implements an alert system that notifies users of significant events. Allocation alerts trigger when smoothed allocation crosses certain thresholds. An alert is generated when allocation reaches 80% (from below), signaling strong bullish conditions. Another alert triggers when allocation falls to 20%, indicating defensive positioning.
These thresholds are not arbitrary but correspond with boundaries between model regimes. An allocation of 80% roughly corresponds to a clear bull market regime, while 20% corresponds to a bear market regime. Alerts at these points are therefore informative about fundamental regime shifts.
11.2 Crisis Alerts
Separate alerts trigger upon detection of crisis and severe crisis. These alerts have highest priority as they signal large risks. A crisis alert should prompt investors to review their portfolio and potentially take defensive measures beyond the automatic model recommendation (e.g., hedging through put options, rebalancing to more defensive sectors).
11.3 Regime Change Alerts
An alert triggers upon change of market regime (e.g., from Neutral to Correction, or from Bull Market to Strong Bull). Regime changes are highly informative events that typically entail substantial allocation changes. These alerts enable investors to proactively respond to changes in market dynamics.
11.4 Risk Breach Alerts
A specialized alert triggers when actual portfolio risk utilization exceeds target parameters by 20%. This is a warning signal that the risk management system is reaching its limits, possibly because market volatility is rising faster than allocation can be reduced. In such situations, investors should consider manual interventions.
12. Practical Application and Limitations
12.1 Portfolio Implementation
DEAM generates a recommendation for allocation between equities (S&P 500) and cash. Implementation by an investor can take various forms. The most direct method is using an S&P 500 ETF (e.g., SPY, VOO) for equity allocation and a money market fund or savings account for cash allocation.
A rebalancing strategy is required to synchronize actual allocation with model recommendation. Two approaches are possible: (1) rule-based rebalancing at every 10% deviation between actual and target, or (2) time-based monthly rebalancing. Both have trade-offs between responsiveness and transaction costs. Empirical evidence (Jaconetti, Kinniry, and Zilbering, 2010) suggests rebalancing frequency has moderate impact on performance, and investors should optimize based on their transaction costs.
12.2 Adaptation to Individual Preferences
The model offers numerous adjustment parameters. Component weights can be modified if investors place more or less belief in certain factors. A fundamentally-oriented investor might increase valuation weight, while a technical trader might increase regime weight.
Risk target parameters (target volatility, max drawdown) should be adapted to individual risk tolerance. Younger investors with long investment horizons can choose higher target volatility (15-18%), while retirees may prefer lower volatility (8-10%). This adjustment systematically shifts average equity allocation.
Crisis thresholds can be adjusted based on preference for sensitivity versus specificity of crisis detection. Lower thresholds (e.g., VIX > 35 instead of 40) increase sensitivity (more crises are detected) but reduce specificity (more false alarms). Higher thresholds have the reverse effect.
12.3 Limitations and Disclaimers
DEAM is based on historical relationships between indicators and market performance. There is no guarantee these relationships will persist in the future. Structural changes in markets (e.g., through regulation, technology, or central bank policy) can break established patterns. This is the fundamental problem of induction in financial science (Taleb, 2007).
The model is optimized for US equities (S&P 500). Application to other markets (international stocks, bonds, commodities) would require recalibration. The indicators and thresholds are specific to the statistical properties of the US equity market.
The model cannot eliminate losses. Even with perfect crisis prediction, an investor following the model would lose money in bear markets—just less than a buy-and-hold investor. The goal is risk-adjusted performance improvement, not risk elimination.
Transaction costs are not modeled. In practice, spreads, commissions, and taxes reduce net returns. Frequent trading can cause substantial costs. Model smoothing helps minimize this, but users should consider their specific cost situation.
The model reacts to information; it does not anticipate it. During sudden shocks (e.g., 9/11, COVID-19 lockdowns), the model can only react after price movements, not before. This limitation is inherent to all reactive systems.
12.4 Relationship to Other Strategies
DEAM is a tactical asset allocation approach and should be viewed as a complement, not replacement, for strategic asset allocation. Brinson, Hood, and Beebower (1986) showed in their influential study "Determinants of Portfolio Performance" that strategic asset allocation (long-term policy allocation) explains the majority of portfolio performance, but this leaves room for tactical adjustments based on market timing.
The model can be combined with value and momentum strategies at the individual stock level. While DEAM controls overall market exposure, within-equity decisions can be optimized through stock-picking models. This separation between strategic (market exposure) and tactical (stock selection) levels follows classical portfolio theory.
The model does not replace diversification across asset classes. A complete portfolio should also include bonds, international stocks, real estate, and alternative investments. DEAM addresses only the US equity allocation decision within a broader portfolio.
13. Scientific Foundation and Evaluation
13.1 Theoretical Consistency
DEAM's components are based on established financial theory and empirical evidence. The market regime component follows from regime-switching models (Hamilton, 1989) and trend-following literature. The risk management component implements volatility targeting (Moreira and Muir, 2017) and modern portfolio theory (Markowitz, 1952). The valuation component is based on discounted cash flow theory and empirical value research (Campbell and Shiller, 1988; Fama and French, 1992). The sentiment component integrates behavioral finance (Baker and Wurgler, 2006). The macro component uses established business cycle indicators (Estrella and Mishkin, 1998).
This theoretical grounding distinguishes DEAM from purely data-mining-based approaches that identify patterns without causal theory. Theory-guided models have greater probability of functioning out-of-sample, as they are based on fundamental mechanisms, not random correlations (Lo and MacKinlay, 1990).
13.2 Empirical Validation
While this document does not present detailed backtest analysis, it should be noted that rigorous validation of a tactical asset allocation model should include several elements:
In-sample testing establishes whether the model functions at all in the data on which it was calibrated. Out-of-sample testing is crucial: the model should be tested in time periods not used for development. Walk-forward analysis, where the model is successively trained on rolling windows and tested in the next window, approximates real implementation.
Performance metrics should be risk-adjusted. Pure return consideration is misleading, as higher returns often only compensate for higher risk. Sharpe Ratio, Sortino Ratio, Calmar Ratio, and Maximum Drawdown are relevant metrics. Comparison with benchmarks (Buy-and-Hold S&P 500, 60/40 Stock/Bond portfolio) contextualizes performance.
Robustness checks test sensitivity to parameter variation. If the model only functions at specific parameter settings, this indicates overfitting. Robust models show consistent performance over a range of plausible parameters.
13.3 Comparison with Existing Literature
DEAM fits into the broader literature on tactical asset allocation. Faber (2007) presented a simple momentum-based timing system that goes long when the market is above its 10-month average, otherwise cash. This simple system avoided large drawdowns in bear markets. DEAM can be understood as a sophistication of this approach that integrates multiple information sources.
Ilmanen (2011) discusses various timing factors in "Expected Returns" and argues for multi-factor approaches. DEAM operationalizes this philosophy. Asness, Moskowitz, and Pedersen (2013) showed that value and momentum effects work across asset classes, justifying cross-asset application of regime and valuation signals.
Ang (2014) emphasizes in "Asset Management: A Systematic Approach to Factor Investing" the importance of systematic, rule-based approaches over discretionary decisions. DEAM is fully systematic and eliminates emotional biases that plague individual investors (overconfidence, hindsight bias, loss aversion).
References
Ang, A. (2014) *Asset Management: A Systematic Approach to Factor Investing*. Oxford: Oxford University Press.
Ang, A., Piazzesi, M. and Wei, M. (2006) 'What does the yield curve tell us about GDP growth?', *Journal of Econometrics*, 131(1-2), pp. 359-403.
Asness, C.S. (2003) 'Fight the Fed Model', *The Journal of Portfolio Management*, 30(1), pp. 11-24.
Asness, C.S., Moskowitz, T.J. and Pedersen, L.H. (2013) 'Value and Momentum Everywhere', *The Journal of Finance*, 68(3), pp. 929-985.
Baker, M. and Wurgler, J. (2006) 'Investor Sentiment and the Cross-Section of Stock Returns', *The Journal of Finance*, 61(4), pp. 1645-1680.
Baker, M. and Wurgler, J. (2007) 'Investor Sentiment in the Stock Market', *Journal of Economic Perspectives*, 21(2), pp. 129-152.
Baur, D.G. and Lucey, B.M. (2010) 'Is Gold a Hedge or a Safe Haven? An Analysis of Stocks, Bonds and Gold', *Financial Review*, 45(2), pp. 217-229.
Bollerslev, T. (1986) 'Generalized Autoregressive Conditional Heteroskedasticity', *Journal of Econometrics*, 31(3), pp. 307-327.
Boudoukh, J., Michaely, R., Richardson, M. and Roberts, M.R. (2007) 'On the Importance of Measuring Payout Yield: Implications for Empirical Asset Pricing', *The Journal of Finance*, 62(2), pp. 877-915.
Brinson, G.P., Hood, L.R. and Beebower, G.L. (1986) 'Determinants of Portfolio Performance', *Financial Analysts Journal*, 42(4), pp. 39-44.
Brock, W., Lakonishok, J. and LeBaron, B. (1992) 'Simple Technical Trading Rules and the Stochastic Properties of Stock Returns', *The Journal of Finance*, 47(5), pp. 1731-1764.
Calmar, T.W. (1991) 'The Calmar Ratio', *Futures*, October issue.
Campbell, J.Y. and Shiller, R.J. (1988) 'The Dividend-Price Ratio and Expectations of Future Dividends and Discount Factors', *Review of Financial Studies*, 1(3), pp. 195-228.
Cochrane, J.H. (2011) 'Presidential Address: Discount Rates', *The Journal of Finance*, 66(4), pp. 1047-1108.
Damodaran, A. (2012) *Equity Risk Premiums: Determinants, Estimation and Implications*. Working Paper, Stern School of Business.
Engle, R.F. (1982) 'Autoregressive Conditional Heteroskedasticity with Estimates of the Variance of United Kingdom Inflation', *Econometrica*, 50(4), pp. 987-1007.
Estrella, A. and Hardouvelis, G.A. (1991) 'The Term Structure as a Predictor of Real Economic Activity', *The Journal of Finance*, 46(2), pp. 555-576.
Estrella, A. and Mishkin, F.S. (1998) 'Predicting U.S. Recessions: Financial Variables as Leading Indicators', *Review of Economics and Statistics*, 80(1), pp. 45-61.
Faber, M.T. (2007) 'A Quantitative Approach to Tactical Asset Allocation', *The Journal of Wealth Management*, 9(4), pp. 69-79.
Fama, E.F. and French, K.R. (1989) 'Business Conditions and Expected Returns on Stocks and Bonds', *Journal of Financial Economics*, 25(1), pp. 23-49.
Fama, E.F. and French, K.R. (1992) 'The Cross-Section of Expected Stock Returns', *The Journal of Finance*, 47(2), pp. 427-465.
Garman, M.B. and Klass, M.J. (1980) 'On the Estimation of Security Price Volatilities from Historical Data', *Journal of Business*, 53(1), pp. 67-78.
Gilchrist, S. and Zakrajšek, E. (2012) 'Credit Spreads and Business Cycle Fluctuations', *American Economic Review*, 102(4), pp. 1692-1720.
Gordon, M.J. (1962) *The Investment, Financing, and Valuation of the Corporation*. Homewood: Irwin.
Graham, B. and Dodd, D.L. (1934) *Security Analysis*. New York: McGraw-Hill.
Hamilton, J.D. (1989) 'A New Approach to the Economic Analysis of Nonstationary Time Series and the Business Cycle', *Econometrica*, 57(2), pp. 357-384.
Ilmanen, A. (2011) *Expected Returns: An Investor's Guide to Harvesting Market Rewards*. Chichester: Wiley.
Jaconetti, C.M., Kinniry, F.M. and Zilbering, Y. (2010) 'Best Practices for Portfolio Rebalancing', *Vanguard Research Paper*.
Jegadeesh, N. and Titman, S. (1993) 'Returns to Buying Winners and Selling Losers: Implications for Stock Market Efficiency', *The Journal of Finance*, 48(1), pp. 65-91.
Kahneman, D. and Tversky, A. (1979) 'Prospect Theory: An Analysis of Decision under Risk', *Econometrica*, 47(2), pp. 263-292.
Korteweg, A. (2010) 'The Net Benefits to Leverage', *The Journal of Finance*, 65(6), pp. 2137-2170.
Lo, A.W. and MacKinlay, A.C. (1990) 'Data-Snooping Biases in Tests of Financial Asset Pricing Models', *Review of Financial Studies*, 3(3), pp. 431-467.
Longin, F. and Solnik, B. (2001) 'Extreme Correlation of International Equity Markets', *The Journal of Finance*, 56(2), pp. 649-676.
Mandelbrot, B. (1963) 'The Variation of Certain Speculative Prices', *The Journal of Business*, 36(4), pp. 394-419.
Markowitz, H. (1952) 'Portfolio Selection', *The Journal of Finance*, 7(1), pp. 77-91.
Modigliani, F. and Miller, M.H. (1961) 'Dividend Policy, Growth, and the Valuation of Shares', *The Journal of Business*, 34(4), pp. 411-433.
Moreira, A. and Muir, T. (2017) 'Volatility-Managed Portfolios', *The Journal of Finance*, 72(4), pp. 1611-1644.
Moskowitz, T.J., Ooi, Y.H. and Pedersen, L.H. (2012) 'Time Series Momentum', *Journal of Financial Economics*, 104(2), pp. 228-250.
Parkinson, M. (1980) 'The Extreme Value Method for Estimating the Variance of the Rate of Return', *Journal of Business*, 53(1), pp. 61-65.
Piotroski, J.D. (2000) 'Value Investing: The Use of Historical Financial Statement Information to Separate Winners from Losers', *Journal of Accounting Research*, 38, pp. 1-41.
Reinhart, C.M. and Rogoff, K.S. (2009) *This Time Is Different: Eight Centuries of Financial Folly*. Princeton: Princeton University Press.
Ross, S.A. (1976) 'The Arbitrage Theory of Capital Asset Pricing', *Journal of Economic Theory*, 13(3), pp. 341-360.
Roy, A.D. (1952) 'Safety First and the Holding of Assets', *Econometrica*, 20(3), pp. 431-449.
Schwert, G.W. (1989) 'Why Does Stock Market Volatility Change Over Time?', *The Journal of Finance*, 44(5), pp. 1115-1153.
Sharpe, W.F. (1966) 'Mutual Fund Performance', *The Journal of Business*, 39(1), pp. 119-138.
Sharpe, W.F. (1994) 'The Sharpe Ratio', *The Journal of Portfolio Management*, 21(1), pp. 49-58.
Simon, D.P. and Wiggins, R.A. (2001) 'S&P Futures Returns and Contrary Sentiment Indicators', *Journal of Futures Markets*, 21(5), pp. 447-462.
Taleb, N.N. (2007) *The Black Swan: The Impact of the Highly Improbable*. New York: Random House.
Whaley, R.E. (2000) 'The Investor Fear Gauge', *The Journal of Portfolio Management*, 26(3), pp. 12-17.
Whaley, R.E. (2009) 'Understanding the VIX', *The Journal of Portfolio Management*, 35(3), pp. 98-105.
Yardeni, E. (2003) 'Stock Valuation Models', *Topical Study*, 51, Yardeni Research.
Zweig, M.E. (1973) 'An Investor Expectations Stock Price Predictive Model Using Closed-End Fund Premiums', *The Journal of Finance*, 28(1), pp. 67-78.
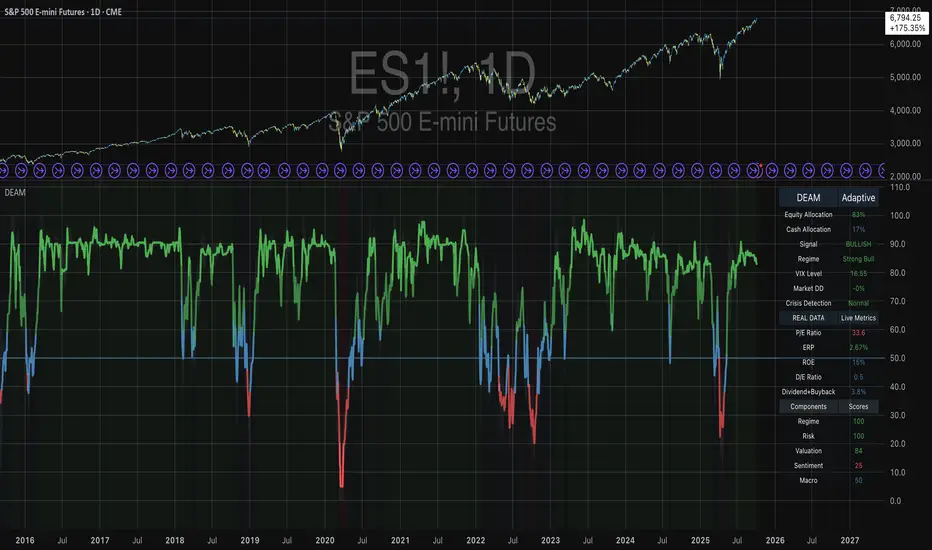
VB-MainLiteVB-MainLite – v1.0 Initial Release
Overview
VB-MainLite is a consolidated market-structure and execution framework designed to streamline decision-making into a single chart-level view. The script combines multi-timeframe trend, volatility, volume, and liquidity signals into one cohesive visual layer, reducing indicator clutter while preserving depth of information for active traders.
Core Architecture
Trend Backbone – EMA 200
Dedicated EMA 200 acts as the primary trend filter and higher-timeframe bias reference.
Serves as the “spine” of the system for contextualizing all secondary signals (swings, reversals, volume events, etc.).
Custom MA Suite (Envelope Ready)
Four configurable moving averages with flexible source, length, and smoothing.
Default configuration (preset idea: “8/89 Envelope”):
MA #1: EMA 8 on high
MA #2: EMA 8 on low
MA #3: EMA 89 on high
MA #4: EMA 89 on low
All four are disabled by default to keep the chart minimal. Users can toggle them on from the Custom MAs group for envelope or cloud-style configurations.
Nadaraya–Watson Smoother (Swing Framework)
Gaussian-kernel Nadaraya–Watson regression applied to price (hl2) to build a smooth synthetic curve.
Two layers of functionality:
Swing labels (▲ / ▼) at inflection points in the smoothed curve.
Optional curve line that visually tracks the turning structure over the last ~500 bars.
Designed to surface early swing potential before standard MAs react.
Hull Moving Average (Trend Overlay)
Optional Hull MA (HMA) for faster trend visualization.
Color-coded by slope (buy/sell bias).
Default: off to prevent overloading the chart; can be enabled under Hull MA settings.
Momentum, Exhaustion & Pattern Engine
CCI-Based Bar Coloring
CCI applied to close with configurable thresholds.
Overbought / oversold CCI zones map directly into candle coloring to visually highlight short-term momentum extremes.
RSI Top / Bottom Exhaustion Finder
RSI logic applied separately to high-driven (tops) and low-driven (bottoms) sequences.
Plots:
Top arrows where high-side RSI stretches into high-risk territory.
Bottom arrows where low-side RSI indicates exhaustion on the downside.
Useful as confluence around the Nadaraya swing turns and EMA 200 regime.
Engulfing + MA Trend Engine (“Fat Bull / Fat Bear”)
Detects bullish and bearish engulfing patterns, then combines them with MA trend cross logic.
Only when both pattern and MA regime align does the engine flag:
Fat Bull (Engulf + MA aligned long)
Fat Bear (Engulf + MA aligned short)
Candles are marked via conditional barcolor to highlight strong, structured shifts in control.
Fat Finger Detection (Wick Spikes / Stop Runs)
Identifies abnormal wick extensions relative to the prior bar’s body range with configurable tolerance.
Supports detection of potential liquidity grabs, stop runs, or “excess” that may precede reversals or mean-reversion behavior.
Volume & Liquidity Intelligence
Bull Snort (Aggressive Buy Spikes)
Flags events where:
Volume is significantly above the 50-period average, and
Price closes in the upper portion of the bar and above prior close.
Plots a labeled marker below the bar to indicate aggressive upside initiative by buyers.
Pocket Pivots (Accumulation Flags)
Compares current volume vs prior 10 sessions with a filter on prior “up” days.
Highlights pocket pivot days where current green candle volume outclasses recent down-day volumes, suggesting stealth accumulation.
Delta Volume Core (Directional Volume by Price)
Internal volume-by-price style engine over a user-defined lookback.
Splits volume into up-close and down-close buckets across dynamic price bins.
Feeds into S&R and ICT zone logic to quantify where buying vs selling pressure built up.
Structural Context: S&R and ICT Zones
S&R Power Channel
Computes local high/low band over a configurable lookback window.
Renders:
Upper and lower S&R channel lines.
Shaded support / resistance zones using boxes.
Adds Buy Power / Sell Power metrics based on the ratio of up vs down bars inside the window, displayed directly in the zone overlays.
Drops ◈ markers where price interacts dynamically with the top or bottom band, highlighting reaction points.
ICT-Style Premium / Discount & Macro Zones
Two tiered structures:
Local Premium / Discount zones over a shorter SR window.
Macro Premium / Discount zones over a longer macro window.
Each zone:
Uses underlying directional volume to annotate accumulation vs distribution bias.
Provides Delta Volume Bias shading in the mid-band region, visually encoding whether local power flows are net-buying or net-selling.
Enables traders to quickly see whether current trade location is in a local/macro discount or premium context while still respecting volume profile.
Positioning Intelligence: PCD (Stocks)
Position Cost Distribution (PCD) – Stocks Only
Available for stock symbols on intraday up to daily timeframe (≤ 1D).
Uses:
TOTAL_SHARES_OUTSTANDING fundamentals,
Daily OHLCV snapshot, and
A bucketed distribution engine
to approximate cost basis distribution across price.
Outputs:
Horizontal “PCD bars” to the right of current price, density-scaled by estimated share concentration.
Color-coding by profitability relative to current price (profitable vs unprofitable positions).
Labels for:
Current price
Average cost
Profit ratio (share % below current price)
90% cost range
70% cost range
Range overlap as a measure of clustering / concentration.
Multi-Timeframe Trend: Two-Pole Gaussian Dashboard
Two-Pole Gaussian Filter (Line + Cloud)
Smooths a user-selected source (default: close) using a two-pole Gaussian filter with tunable alpha.
Plots:
A thin Gaussian trend line, and
A thick Gaussian “cloud” line with transparency, colored by slope vs past (offsetG).
Functions as a responsive trend backbone that is more sensitive than EMA 200 but less noisy than raw price.
Multi-Timeframe Gaussian Dashboard
Evaluates Gaussian trend direction across up to six timeframes (e.g., 1H / 2H / 4H / Daily / Weekly).
Renders a compact bottom-right table:
Header: symbol + overall bias arrow (up / down) based on average trend alignment.
Row of colored cells per timeframe (green for uptrend, magenta for downtrend) with human-readable TF labels (e.g., “60M”, “4H”, “1D”).
Gives an immediate read on whether intraday, swing, and higher-timeframe flows are aligned or fragmented.
Default Configuration & Usage Guidance
Default state after adding the script:
Enabled by default:
EMA 200 trend backbone
Nadaraya–Watson swing labels and curve
CCI bar coloring
RSI top/bottom arrows
Fat Bull / Fat Bear engine
Bull Snort & Pocket Pivots
S&R Power Channel
ICT Local + Macro zones
Two-pole Gaussian line + cloud + dashboard
PCD engine for stocks (auto-active where data is available)
Disabled by default (opt-in):
Custom MA suite (4x MAs, preset as EMA 8/8/89/89)
Hull MA overlay
How traders can use VB-MainLite in practice:
Use EMA 200 + Gaussian dashboard to define top-down directional bias and avoid trading directly against multi-TF trend.
Use Nadaraya swing labels, RSI exhaustion arrows, and CCI bar colors to time entries within that higher-timeframe bias.
Use Fat Bull / Fat Bear events as structured confirmation that both pattern and MA regime have flipped in the same direction.
Use Bull Snort, Pocket Pivots, and S&R / ICT zones to align execution with liquidity, volume, and location (premium vs discount).
On stocks, use PCD as a positioning map to understand trapped supply, support zones near crowded cost basis, and where profit-taking is likely.

LogNormalLibrary "LogNormal"
A collection of functions used to model skewed distributions as log-normal.
Prices are commonly modeled using log-normal distributions (ie. Black-Scholes) because they exhibit multiplicative changes with long tails; skewed exponential growth and high variance. This approach is particularly useful for understanding price behavior and estimating risk, assuming continuously compounding returns are normally distributed.
Because log space analysis is not as direct as using math.log(price) , this library extends the Error Functions library to make working with log-normally distributed data as simple as possible.
- - -
QUICK START
Import library into your project
Initialize model with a mean and standard deviation
Pass model params between methods to compute various properties
var LogNorm model = LN.init(arr.avg(), arr.stdev()) // Assumes the library is imported as LN
var mode = model.mode()
Outputs from the model can be adjusted to better fit the data.
var Quantile data = arr.quantiles()
var more_accurate_mode = mode.fit(model, data) // Fits value from model to data
Inputs to the model can also be adjusted to better fit the data.
datum = 123.45
model_equivalent_datum = datum.fit(data, model) // Fits value from data to the model
area_from_zero_to_datum = model.cdf(model_equivalent_datum)
- - -
TYPES
There are two requisite UDTs: LogNorm and Quantile . They are used to pass parameters between functions and are set automatically (see Type Management ).
LogNorm
Object for log space parameters and linear space quantiles .
Fields:
mu (float) : Log space mu ( µ ).
sigma (float) : Log space sigma ( σ ).
variance (float) : Log space variance ( σ² ).
quantiles (Quantile) : Linear space quantiles.
Quantile
Object for linear quantiles, most similar to a seven-number summary .
Fields:
Q0 (float) : Smallest Value
LW (float) : Lower Whisker Endpoint
LC (float) : Lower Whisker Crosshatch
Q1 (float) : First Quartile
Q2 (float) : Second Quartile
Q3 (float) : Third Quartile
UC (float) : Upper Whisker Crosshatch
UW (float) : Upper Whisker Endpoint
Q4 (float) : Largest Value
IQR (float) : Interquartile Range
MH (float) : Midhinge
TM (float) : Trimean
MR (float) : Mid-Range
- - -
TYPE MANAGEMENT
These functions reliably initialize and update the UDTs. Because parameterization is interdependent, avoid setting the LogNorm and Quantile fields directly .
init(mean, stdev, variance)
Initializes a LogNorm object.
Parameters:
mean (float) : Linearly measured mean.
stdev (float) : Linearly measured standard deviation.
variance (float) : Linearly measured variance.
Returns: LogNorm Object
set(ln, mean, stdev, variance)
Transforms linear measurements into log space parameters for a LogNorm object.
Parameters:
ln (LogNorm) : Object containing log space parameters.
mean (float) : Linearly measured mean.
stdev (float) : Linearly measured standard deviation.
variance (float) : Linearly measured variance.
Returns: LogNorm Object
quantiles(arr)
Gets empirical quantiles from an array of floats.
Parameters:
arr (array) : Float array object.
Returns: Quantile Object
- - -
DESCRIPTIVE STATISTICS
Using only the initialized LogNorm parameters, these functions compute a model's central tendency and standardized moments.
mean(ln)
Computes the linear mean from log space parameters.
Parameters:
ln (LogNorm) : Object containing log space parameters.
Returns: Between 0 and ∞
median(ln)
Computes the linear median from log space parameters.
Parameters:
ln (LogNorm) : Object containing log space parameters.
Returns: Between 0 and ∞
mode(ln)
Computes the linear mode from log space parameters.
Parameters:
ln (LogNorm) : Object containing log space parameters.
Returns: Between 0 and ∞
variance(ln)
Computes the linear variance from log space parameters.
Parameters:
ln (LogNorm) : Object containing log space parameters.
Returns: Between 0 and ∞
skewness(ln)
Computes the linear skewness from log space parameters.
Parameters:
ln (LogNorm) : Object containing log space parameters.
Returns: Between 0 and ∞
kurtosis(ln, excess)
Computes the linear kurtosis from log space parameters.
Parameters:
ln (LogNorm) : Object containing log space parameters.
excess (bool) : Excess Kurtosis (true) or regular Kurtosis (false).
Returns: Between 0 and ∞
hyper_skewness(ln)
Computes the linear hyper skewness from log space parameters.
Parameters:
ln (LogNorm) : Object containing log space parameters.
Returns: Between 0 and ∞
hyper_kurtosis(ln, excess)
Computes the linear hyper kurtosis from log space parameters.
Parameters:
ln (LogNorm) : Object containing log space parameters.
excess (bool) : Excess Hyper Kurtosis (true) or regular Hyper Kurtosis (false).
Returns: Between 0 and ∞
- - -
DISTRIBUTION FUNCTIONS
These wrap Gaussian functions to make working with model space more direct. Because they are contained within a log-normal library, they describe estimations relative to a log-normal curve, even though they fundamentally measure a Gaussian curve.
pdf(ln, x, empirical_quantiles)
A Probability Density Function estimates the probability density . For clarity, density is not a probability .
Parameters:
ln (LogNorm) : Object of log space parameters.
x (float) : Linear X coordinate for which a density will be estimated.
empirical_quantiles (Quantile) : Quantiles as observed in the data (optional).
Returns: Between 0 and ∞
cdf(ln, x, precise)
A Cumulative Distribution Function estimates the area under a Log-Normal curve between Zero and a linear X coordinate.
Parameters:
ln (LogNorm) : Object of log space parameters.
x (float) : Linear X coordinate .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and 1
ccdf(ln, x, precise)
A Complementary Cumulative Distribution Function estimates the area under a Log-Normal curve between a linear X coordinate and Infinity.
Parameters:
ln (LogNorm) : Object of log space parameters.
x (float) : Linear X coordinate .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and 1
cdfinv(ln, a, precise)
An Inverse Cumulative Distribution Function reverses the Log-Normal cdf() by estimating the linear X coordinate from an area.
Parameters:
ln (LogNorm) : Object of log space parameters.
a (float) : Normalized area .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and ∞
ccdfinv(ln, a, precise)
An Inverse Complementary Cumulative Distribution Function reverses the Log-Normal ccdf() by estimating the linear X coordinate from an area.
Parameters:
ln (LogNorm) : Object of log space parameters.
a (float) : Normalized area .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and ∞
cdfab(ln, x1, x2, precise)
A Cumulative Distribution Function from A to B estimates the area under a Log-Normal curve between two linear X coordinates (A and B).
Parameters:
ln (LogNorm) : Object of log space parameters.
x1 (float) : First linear X coordinate .
x2 (float) : Second linear X coordinate .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and 1
ott(ln, x, precise)
A One-Tailed Test transforms a linear X coordinate into an absolute Z Score before estimating the area under a Log-Normal curve between Z and Infinity.
Parameters:
ln (LogNorm) : Object of log space parameters.
x (float) : Linear X coordinate .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and 0.5
ttt(ln, x, precise)
A Two-Tailed Test transforms a linear X coordinate into symmetrical ± Z Scores before estimating the area under a Log-Normal curve from Zero to -Z, and +Z to Infinity.
Parameters:
ln (LogNorm) : Object of log space parameters.
x (float) : Linear X coordinate .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and 1
ottinv(ln, a, precise)
An Inverse One-Tailed Test reverses the Log-Normal ott() by estimating a linear X coordinate for the right tail from an area.
Parameters:
ln (LogNorm) : Object of log space parameters.
a (float) : Half a normalized area .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and ∞
tttinv(ln, a, precise)
An Inverse Two-Tailed Test reverses the Log-Normal ttt() by estimating two linear X coordinates from an area.
Parameters:
ln (LogNorm) : Object of log space parameters.
a (float) : Normalized area .
precise (bool) : Double precision (true) or single precision (false).
Returns: Linear space tuple :
- - -
UNCERTAINTY
Model-based measures of uncertainty, information, and risk.
sterr(sample_size, fisher_info)
The standard error of a sample statistic.
Parameters:
sample_size (float) : Number of observations.
fisher_info (float) : Fisher information.
Returns: Between 0 and ∞
surprisal(p, base)
Quantifies the information content of a single event.
Parameters:
p (float) : Probability of the event .
base (float) : Logarithmic base (optional).
Returns: Between 0 and ∞
entropy(ln, base)
Computes the differential entropy (average surprisal).
Parameters:
ln (LogNorm) : Object of log space parameters.
base (float) : Logarithmic base (optional).
Returns: Between 0 and ∞
perplexity(ln, base)
Computes the average number of distinguishable outcomes from the entropy.
Parameters:
ln (LogNorm)
base (float) : Logarithmic base used for Entropy (optional).
Returns: Between 0 and ∞
value_at_risk(ln, p, precise)
Estimates a risk threshold under normal market conditions for a given confidence level.
Parameters:
ln (LogNorm) : Object of log space parameters.
p (float) : Probability threshold, aka. the confidence level .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and ∞
value_at_risk_inv(ln, value_at_risk, precise)
Reverses the value_at_risk() by estimating the confidence level from the risk threshold.
Parameters:
ln (LogNorm) : Object of log space parameters.
value_at_risk (float) : Value at Risk.
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and 1
conditional_value_at_risk(ln, p, precise)
Estimates the average loss beyond a confidence level, aka. expected shortfall.
Parameters:
ln (LogNorm) : Object of log space parameters.
p (float) : Probability threshold, aka. the confidence level .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and ∞
conditional_value_at_risk_inv(ln, conditional_value_at_risk, precise)
Reverses the conditional_value_at_risk() by estimating the confidence level of an average loss.
Parameters:
ln (LogNorm) : Object of log space parameters.
conditional_value_at_risk (float) : Conditional Value at Risk.
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and 1
partial_expectation(ln, x, precise)
Estimates the partial expectation of a linear X coordinate.
Parameters:
ln (LogNorm) : Object of log space parameters.
x (float) : Linear X coordinate .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and µ
partial_expectation_inv(ln, partial_expectation, precise)
Reverses the partial_expectation() by estimating a linear X coordinate.
Parameters:
ln (LogNorm) : Object of log space parameters.
partial_expectation (float) : Partial Expectation .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and ∞
conditional_expectation(ln, x, precise)
Estimates the conditional expectation of a linear X coordinate.
Parameters:
ln (LogNorm) : Object of log space parameters.
x (float) : Linear X coordinate .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between X and ∞
conditional_expectation_inv(ln, conditional_expectation, precise)
Reverses the conditional_expectation by estimating a linear X coordinate.
Parameters:
ln (LogNorm) : Object of log space parameters.
conditional_expectation (float) : Conditional Expectation .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and ∞
fisher(ln, log)
Computes the Fisher Information Matrix for the distribution, not a linear X coordinate.
Parameters:
ln (LogNorm) : Object of log space parameters.
log (bool) : Sets if the matrix should be in log (true) or linear (false) space.
Returns: FIM for the distribution
fisher(ln, x, log)
Computes the Fisher Information Matrix for a linear X coordinate, not the distribution itself.
Parameters:
ln (LogNorm) : Object of log space parameters.
x (float) : Linear X coordinate .
log (bool) : Sets if the matrix should be in log (true) or linear (false) space.
Returns: FIM for the linear X coordinate
confidence_interval(ln, x, sample_size, confidence, precise)
Estimates a confidence interval for a linear X coordinate.
Parameters:
ln (LogNorm) : Object of log space parameters.
x (float) : Linear X coordinate .
sample_size (float) : Number of observations.
confidence (float) : Confidence level .
precise (bool) : Double precision (true) or single precision (false).
Returns: CI for the linear X coordinate
- - -
CURVE FITTING
An overloaded function that helps transform values between spaces. The primary function uses quantiles, and the overloads wrap the primary function to make working with LogNorm more direct.
fit(x, a, b)
Transforms X coordinate between spaces A and B.
Parameters:
x (float) : Linear X coordinate from space A .
a (LogNorm | Quantile | array) : LogNorm, Quantile, or float array.
b (LogNorm | Quantile | array) : LogNorm, Quantile, or float array.
Returns: Adjusted X coordinate
- - -
EXPORTED HELPERS
Small utilities to simplify extensibility.
z_score(ln, x)
Converts a linear X coordinate into a Z Score.
Parameters:
ln (LogNorm) : Object of log space parameters.
x (float) : Linear X coordinate.
Returns: Between -∞ and +∞
x_coord(ln, z)
Converts a Z Score into a linear X coordinate.
Parameters:
ln (LogNorm) : Object of log space parameters.
z (float) : Standard normal Z Score.
Returns: Between 0 and ∞
iget(arr, index)
Gets an interpolated value of a pseudo -element (fictional element between real array elements). Useful for quantile mapping.
Parameters:
arr (array) : Float array object.
index (float) : Index of the pseudo element.
Returns: Interpolated value of the arrays pseudo element.

Polynomial Regression HeatmapPolynomial Regression Heatmap – Advanced Trend & Volatility Visualizer
Overview
The Polynomial Regression Heatmap is a sophisticated trading tool designed for traders who require a clear and precise understanding of market trends and volatility. By applying a second-degree polynomial regression to price data, the indicator generates a smooth trend curve, augmented with adaptive volatility bands and a dynamic heatmap. This framework allows users to instantly recognize trend direction, potential reversals, and areas of market strength or weakness, translating complex price action into a visually intuitive map.
Unlike static trend indicators, the Polynomial Regression Heatmap adapts to changing market conditions. Its visual design—including color-coded candles, regression bands, optional polynomial channels, and breakout markers—ensures that price behavior is easy to interpret. This makes it suitable for scalping, swing trading, and longer-term strategies across multiple asset classes.
How It Works
The core of the indicator relies on fitting a second-degree polynomial to a defined lookback period of price data. This regression curve captures the non-linear nature of market movements, revealing the true trajectory of price beyond the distortions of noise or short-term volatility.
Adaptive upper and lower bands are constructed using ATR-based scaling, surrounding the regression line to reflect periods of high and low volatility. When price moves toward or beyond these bands, it signals areas of potential overextension or support/resistance.
The heatmap colors each candle based on its relative position within the bands. Green shades indicate proximity to the upper band, red shades indicate proximity to the lower band, and neutral tones represent mid-range positioning. This continuous gradient visualization provides immediate feedback on trend strength, market balance, and potential turning points.
Optional polynomial channels can be overlaid around the regression curve. These three-line channels are based on regression residuals and a fixed width multiplier, offering additional reference points for analyzing price deviations, trend continuation, and reversion zones.
Signals and Breakouts
The Polynomial Regression Heatmap includes statistical pivot-based signals to highlight actionable price movements:
Buy Signals – A triangular marker appears below the candle when a pivot low occurs below the lower regression band.
Sell Signals – A triangular marker appears above the candle when a pivot high occurs above the upper regression band.
These markers identify significant deviations from the regression curve while accounting for volatility, providing high-quality visual cues for potential entry points.
The indicator ensures clarity by spacing markers vertically using ATR-based calculations, preventing overlap during periods of high volatility. Users can rely on these signals in combination with heatmap intensity and regression slope for contextual confirmation.
Interpretation
Trend Analysis :
The slope of the polynomial regression line represents trend direction. A rising curve indicates bullish bias, a falling curve indicates bearish bias, and a flat curve indicates consolidation.
Steeper slopes suggest stronger momentum, while gradual slopes indicate more moderate trend conditions.
Volatility Assessment :
Band width provides an instant visual measure of market volatility. Narrow bands correspond to low volatility and potential consolidation, whereas wide bands indicate higher volatility and significant price swings.
Heatmap Coloring :
Candle colors visually represent price position within the bands. This allows traders to quickly identify zones of bullish or bearish pressure without performing complex calculations.
Channel Analysis (Optional) :
The polynomial channel defines zones for evaluating potential overextensions or retracements. Price interacting with these lines may suggest areas where mean-reversion or trend continuation is likely.
Breakout Signals :
Buy and Sell markers highlight pivot points relative to the regression and volatility bands. These are statistical signals, not arbitrary triggers, and should be interpreted in context with trend slope, band width, and heatmap intensity.
Strategy Integration
The Polynomial Regression Heatmap supports multiple trading approaches:
Trend Following – Enter trades in the direction of the regression slope while using the heatmap for momentum confirmation.
Pullback Entries – Use breakouts or deviations from the regression bands as low-risk entry points during trend continuation.
Mean Reversion – Price reaching outer channel boundaries can indicate potential reversal or retracement opportunities.
Multi-Timeframe Alignment – Overlay on higher and lower timeframes to filter noise and improve entry timing.
Stop-loss levels can be set just beyond the opposing regression band, while take-profit targets can be informed by the distance between the bands or the curvature of the polynomial line.
Advanced Techniques
For traders seeking greater precision:
Combine the Polynomial Regression Heatmap with volume, momentum, or volatility indicators to validate signals.
Observe the width and slope of the regression bands over time to anticipate expanding or contracting volatility.
Track sequences of breakout signals in conjunction with heatmap intensity for systematic trade management.
Adjusting regression length allows customization for different assets or timeframes, balancing responsiveness and smoothing. The combination of polynomial curve, adaptive bands, heatmap, and optional channels provides a comprehensive statistical framework for informed decision-making.
Inputs and Customization
Regression Length – Determines the number of bars used for polynomial fitting. Shorter lengths increase responsiveness; longer lengths improve smoothing.
Show Bands – Toggle visibility of the ATR-based regression bands.
Show Channel – Enable or disable the polynomial channel overlay.
Color Settings – Customize bullish, bearish, neutral, and accent colors for clarity and visual preference.
All other internal parameters are fixed to ensure consistent statistical behavior and minimize potential misconfiguration.
Why Use Polynomial Regression Heatmap
The Polynomial Regression Heatmap transforms complex price action into a clear, actionable visual framework. By combining non-linear trend mapping, adaptive volatility bands, heatmap visualization, and breakout signals, it provides a multi-dimensional perspective that is both quantitative and intuitive.
This indicator allows traders to focus on execution, interpret market structure at a glance, and evaluate trend strength, overextensions, and potential reversals in real time. Its design is compatible with scalping, swing trading, and long-term strategies, providing a robust tool for disciplined, data-driven trading.
Neural Pulse System [Alpha Extract]Neural Pulse System (NPS)
The Neural Pulse System (NPS) is a custom technical indicator that analyzes price action through a probabilistic lens, offering a dynamic view of bullish and bearish tendencies.
Unlike traditional binary classification models, NPS employs Ordinary Least Squares (OLS) regression with dynamically computed coefficients to produce a smooth probability output ranging from -1 to 1.
Paired with ATR-based bands, this indicator provides an intuitive and volatility-aware approach to trend analysis.
🔶 CALCULATION
The Neural Pulse System utilizes OLS regression to compute probabilities of bullish or bearish price action while incorporating ATR-based bands for volatility context:
Dynamic Coefficients: Coefficients are recalculated in real-time and scaled up to ensure the regression adapts to evolving market conditions.
Ordinary Least Squares (OLS): Uses OLS regression instead of gradient descent for more precise and efficient coefficient estimation.
ATR Bands: Smoothed Average True Range (ATR) bands serve as dynamic boundaries, framing the regression within market volatility.
Probability Output: Instead of a binary result, the output is a continuous probability curve (-1 to 1), helping traders gauge the strength of bullish or bearish momentum.
Formula:
OLS Regression = Line of best fit minimizing squared errors
Probability Signal = Transformed regression output scaled to -1 (bearish) to 1 (bullish)
ATR Bands = Smoothed Average True Range (ATR) to frame price movements within market volatility
🔶 DETAILS
📊 Visual Features:
Probability Curve: Smooth probability signal ranging from -1 (bearish) to 1 (bullish)
ATR Bands: Price action is constrained within volatility bands, preventing extreme deviations
Color-Coded Signals:
Blue to Green: Increasing probability of bullish momentum
Orange to Red: Increasing probability of bearish momentum
Interpretation:
Bullish Bias: Probability output consistently above 0 suggests a bullish trend.
Bearish Bias: Probability output consistently below 0 indicates bearish pressure.
Reversals: Extreme values near -1 or 1, followed by a move toward 0, may signal potential trend reversals.
🔶 EXAMPLES
📌 Trend Identification: Use the probability output to gauge trend direction.
📌Example: On a 1-hour chart, NPS moves from -0.5 to 0.8 as price breaks resistance, signaling a bullish trend.
Reversal Signals: Watch for probability extremes near -1 or 1 followed by a reversal toward 0.
Example: NPS hits 0.9, price touches the upper ATR band, then both retreat—indicating a potential pullback.
📌 Example snapshots:
Volatility Context: ATR bands help assess whether price action aligns with typical market conditions.
Example: During low volatility, the probability signal hovers near 0, and ATR bands tighten, suggesting a potential breakout.
🔶 SETTINGS
Customization Options:
ATR Period – Defines lookback length for ATR calculation (shorter = more responsive, longer = smoother).
ATR Multiplier – Adjusts band width for better volatility capture.
Regression Length – Controls how many bars feed into the coefficient calculation (longer = smoother, shorter = more reactive).
Scaling Factor – Adjusts the strength of regression coefficients.
Output Smoothing – Option to apply a moving average for a cleaner probability curve
Dynamic ALMA with signalsEnhanced ALMA with Signals
This TradingView indicator is designed to enhance your trading strategy by utilizing the Arnaud Legoux Moving Average (ALMA), a unique moving average that provides smoother price action while minimizing lag. The script not only plots the ALMA line but also dynamically adjusts its parameters based on market volatility to adapt to different trading conditions. Additionally, it highlights potential bounce points off the line, as well as breakout points, giving traders clear signals for potential support, resistance levels, and breakouts.
Key Features:
Dynamic ALMA Line with Glow Effect:
The core of this indicator is the ALMA line, which is dynamically adjusted to market volatility, providing more accurate signals in varying conditions. The line adapts to both trending and consolidating markets by adjusting its sensitivity in real time. A glow effect is created by plotting the ALMA line multiple times with increasing transparency, making it visually distinct.
Bounce Detection Signals with Volatility Filter:
The script detects and labels potential support and resistance bounces based on the crossover and crossunder of the price with the ALMA line, further filtered by a volatility condition. This helps in filtering out false signals during low-volatility conditions, making the signals more reliable.
Visual Enhancements:
Custom glow effects and labels for bounce detection enhance chart readability and help traders quickly identify key levels.
Inputs:
Base Window Size: Sets the number of bars used in calculating the ALMA, allowing traders to adjust the sensitivity of the moving average. This parameter is dynamically adjusted based on current market volatility.
Offset: Determines the position of the ALMA curve. Higher values move the curve further away from the price. This value remains constant for stability.
Sigma: Controls the smoothness of the ALMA curve; a higher sigma results in a smoother curve. This value also remains constant.
ATR Period and Threshold Multiplier: Used to calculate the Average True Range (ATR) for the volatility filter, which determines whether the market conditions are sufficiently volatile to consider bounce signals.
How It Works:
Dynamic ALMA Calculation:
The script calculates the ALMA (Arnaud Legoux Moving Average) using the ta.alma function, dynamically adjusting the window size based on market volatility measured by the ATR (Average True Range). This ensures that the ALMA line remains responsive in high-volatility environments and smooth in low-volatility conditions.
Glow Effect:
To create a glow effect around the ALMA line, the script plots the ALMA multiple times with varying degrees of transparency. This visual enhancement helps the ALMA line stand out on the chart.
Bounce Detection with Volatility Filter:
The script uses two conditions to detect potential bounces:
Support Bounce: Detected when the low of the bar crosses above the ALMA line (ta.crossover(low, alma)) and the close is above the ALMA, while the volatility filter confirms sufficient market activity. This suggests potential support at the ALMA line.
Resistance Bounce: Detected when the high of the bar crosses below the ALMA line (ta.crossunder(high, alma)) and the close is below the ALMA, while the volatility filter confirms sufficient market activity. This indicates potential resistance at the ALMA line.
Labeling Bounce Points:
When a bounce is detected, the script labels it on the chart:
Support Bounces (S): Labeled with a blue "S" below the bar where a support bounce is detected.
Resistance Bounces (R): Labeled with a white "R" above the bar where a resistance bounce is detected.
Usage:
This enhanced indicator helps traders visualize key support and resistance levels more effectively by dynamically adjusting the ALMA moving average to market conditions. By detecting and labeling potential bounce points and filtering these signals based on volatility, traders can better identify entry and exit points in their trading strategy. The dynamic adjustments and visual enhancements make it easier to spot critical levels quickly and adapt to changing market conditions.
Customize the inputs to fit your trading style, and use this enhanced ALMA indicator to gain a more refined understanding of market trends, potential reversals, and breakouts.
SMIIO + VolumeThis indicator generates long and short signals.
The operation of the indicator is as follows;
First, true strength index is calculated with closing prices. We call this the "ergodic" curve.
Then the average of the ergodic (ema) is calculated to obtain the "signal" curve.
To calculate the "oscillator", the signal is subtracted from ergodic (oscillator = ergodic - signal).
The last variable to be used in the calculation is the average volume, calculated with sma.
Calculation for long signal;
- If the ergodic curve cross up the zero line (ergodic > 0 AND ergodic < 0) and,
- If the current oscillator is greater than the previous oscillator (oscillator > oscillator ) and,
- If the current ergonic is greater than the previous signal (ergonic > signal) and,
- If the current volume is greater than the average volume (volume > averageVolume) and,
- If the current candle closing price is greater than the opening price (close > open)
If all the above conditions are fullfilled, the long input signal is issued with "Buy" label.
Calculation for short signal;
- If the ergodic curve cross down the zero line (ergodic < 0 AND ergodic > 0) and,
- If the current oscillator is smaller than the previous oscillator (oscillator < oscillator ) and,
- If the current ergonic is smaller than the previous signal (ergonic < signal) and,
- If the current volume is greater than the average volume (volume > averageVolume) and,
- If the current candle closing price is smaller than the opening price (close < open)
If all the above conditions are fullfilled, the short input signal is issued with "Sell" label.
Treasury Yields Heatmap [By MUQWISHI]▋ INTRODUCTION :
The “Treasury Yields Heatmap” generates a dynamic heat map table, showing treasury yield bond values corresponding with dates. In the last column, it presents the status of the yield curve, discerning whether it’s in a normal, flat, or inverted configuration, which determined by using Pearson's linear regression coefficient. This tool is built to offer traders essential insights for effectively tracking bond values and monitoring yield curve status, featuring the flexibility to input a starting period, timeframe, and select from a range of major countries' bond data.
_______________________
▋ OVERVIEW:
______________________
▋ YIELD CURVE:
It is determined through Pearson's linear regression coefficient and considered…
R ≥ 0.7 → Normal
0.7 > R ≥ 0.35 → Slight Normal
0.35 > R > -0.35 → Flat
-0.35 ≥ R > -0.7 → Slight Inverted
-0.7 ≥ R → Inverted
_______________________
▋ INDICATOR SETTINGS:
#Section One: Table Setting
#Section Two: Technical Setting
(1) Country: Select country’s treasury yields data
(2) Timeframe: Time interval.
(3) Fetch By:
(3A) Date: Retrieve data by beginning of date.
(3B) Period: Retrieve data by specifying the number of time series back.
Enjoy. Please let me know if you have any questions.
Thank you.

Crude Oil: Backwardation Vs ContangoCrude Oil, CL
Plots Futures Curve: Futures contract prices over the next 3.5 years; to easily visualize Backwardation Vs Contango(carrying charge) markets.
Carrying charge (contract prices increasing into the future) = normal, representing the costs of carrying/storage of a commodity. When this is flipped to Backwardation(As the above; contract prices decreasing into the future): it's a bullish sign: Buyers want this commodity, and they want it NOW.
Note: indicator does not map to time axis in the same way as price; it simply plots the progression of contract months out into the future; left to right; so timeframe DOESN'T MATTER for this plot
TO UPDATE (every year or so): in REQUEST CONTRACTS section, delete old contracts (top) and add new ones (bottom). Then in PLOTTING section, Delete old contract labels (bottom); add new contract labels (top); adjust the X in 'bar_index-(X+_historical)' numbers accordingly
This is one of several similar Futures Curve indicators: Meats | Metals | Grains | VIX | Crude Oil
If you want to build from this; to work on other commodities; be aware that Tradingview limits the number of contract calls to 40 (hence the multiple indicators)
Tips:
-Right click and reset chart if you can't see the plot; or if you have trouble with the scaling.
-Right click and add to new scale if you prefer this not to overlay directly on price. Or move to new pane below.
-If this takes too long to load (due to so many security calls); comment out the more distant future half of the contracts; and their respective labels. Or comment out every other contract and every other label if you prefer.
--Added historical input: input days back in time; to see the historical shape of the Futures curve via selecting 'days back' snapshot
updated 20th June 2022
© twingall
Nadaraya-Watson: Rational Quadratic Kernel (Opening Gap Shift)What we did to fix it: We didn't throw out the old data (that made it too jumpy early in the day).
Instead, we "tricked" the kernel by shifting all the previous day's prices up or down by the exact gap amount (e.g., if it gapped up 50 points, add 50 to every old price point). This makes the history "line up" with the new day's starting level.
Created so with a fresh session the Nadaraya-Watson Regression Kernel is relevant from the get go - no catch up on opening gaps.
All credit to jdehorty his full description is below.
What is Nadaraya–Watson Regression?
Nadaraya–Watson Regression is a type of Kernel Regression, which is a non-parametric method for estimating the curve of best fit for a dataset. Unlike Linear Regression or Polynomial Regression, Kernel Regression does not assume any underlying distribution of the data. For estimation, it uses a kernel function, which is a weighting function that assigns a weight to each data point based on how close it is to the current point. The computed weights are then used to calculate the weighted average of the data points.
How is this different from using a Moving Average?
A Simple Moving Average is actually a special type of Kernel Regression that uses a Uniform (Retangular) Kernel function. This means that all data points in the specified lookback window are weighted equally. In contrast, the Rational Quadratic Kernel function used in this indicator assigns a higher weight to data points that are closer to the current point. This means that the indicator will react more quickly to changes in the data.
Why use the Rational Quadratic Kernel over the Gaussian Kernel?
The Gaussian Kernel is one of the most commonly used Kernel functions and is used extensively in many Machine Learning algorithms due to its general applicability across a wide variety of datasets. The Rational Quadratic Kernel can be thought of as a Gaussian Kernel on steroids; it is equivalent to adding together many Gaussian Kernels of differing length scales. This allows the user even more freedom to tune the indicator to their specific needs.
The formula for the Rational Quadratic function is:
K(x, x') = (1 + ||x - x'||^2 / (2 * alpha * h^2))^(-alpha)
where x and x' data are points, alpha is a hyperparameter that controls the smoothness (i.e. overall "wiggle") of the curve, and h is the band length of the kernel.
Does this Indicator Repaint?
No, this indicator has been intentionally designed to NOT repaint. This means that once a bar has closed, the indicator will never change the values in its plot. This is useful for backtesting and for trading strategies that require a non-repainting indicator.
Settings:
Bandwidth. This is the number of bars that the indicator will use as a lookback window.
Relative Weighting Parameter. The alpha parameter for the Rational Quadratic Kernel function. This is a hyperparameter that controls the smoothness of the curve. A lower value of alpha will result in a smoother, more stretched-out curve, while a lower value will result in a more wiggly curve with a tighter fit to the data. As this parameter approaches 0, the longer time frames will exert more influence on the estimation, and as it approaches infinity, the curve will become identical to the one produced by the Gaussian Kernel.
Color Smoothing. Toggles the mechanism for coloring the estimation plot between rate of change and cross over modes.
SMC Structures and Multi-Timeframe FVG PYSMC Structures and Multi-Timeframe FVG Indicator
Tip: For optimal performance, adjust the number of FVGs displayed per timeframe in the settings. On high-performance devices, up to 8 FVGs per timeframe can be used without issues. If you experience slowdowns, reduce to 3 or 4 FVGs per timeframe. If the chart flashes, disable indicators one by one to identify conflicts, or try using the TradingView Mobile or Windows App for a smoother experience.
Overview
This Pine Script indicator enhances market analysis by integrating Smart Money Concepts (SMC) with Fair Value Gaps (FVG) across multiple timeframes. It identifies trend continuations (Break of Structure, BOS) and trend reversals (Change of Character, CHoCH) while highlighting liquidity zones through FVG detection. The indicator includes eight customizable Moving Average (MA) curve templates, disabled by default, to complement SMC and FVG analysis. Its originality lies in combining multi-timeframe FVG detection with SMC structure analysis, providing traders with a cohesive tool to visualize price action patterns and liquidity zones efficiently.
Features and Functionality
1. Fair Value Gaps (FVG)
The indicator detects and displays bullish, bearish, and mitigated FVGs, representing liquidity zones where price inefficiencies occur. These gaps are dynamically updated based on price action:
Bullish FVG: Displayed in green when unmitigated, indicating potential upward liquidity zones.
Bearish FVG: Displayed in red when unmitigated, signaling potential downward liquidity zones.
Mitigated FVG: Shown in gray once the gap is partially filled by price action.
Fully Mitigated FVG: Automatically removed from the chart when the gap is fully filled, reducing visual clutter.
Users can customize the number of historical FVGs displayed via the settings, allowing focus on recent liquidity zones for targeted analysis.
2. SMC Structures
The indicator identifies key SMC price action patterns:
Break of Structure (BOS): Marked with gray lines, indicating trend continuation when price breaks a significant high or low.
Change of Character (CHoCH): Highlighted with yellow lines, signaling potential trend reversals when price fails to maintain the current structure.
High/Low Values: Blue lines denote the highest high and lowest low of the current structure, providing reference points for market context.
3. Multi-Timeframe FVG Analysis
A standout feature is the ability to analyze FVGs across multiple timeframes simultaneously. This allows traders to align higher-timeframe liquidity zones with lower-timeframe entries, improving trade precision. The indicator fetches FVG data from user-selected timeframes, displaying them cohesively on the chart.
4. Moving Average (MA) Templates
The indicator includes eight customizable MA curve templates in the Settings > Template section, disabled by default. These templates allow users to overlay MAs (e.g., SMA, EMA, WMA) to complement SMC and FVG analysis. Each template is pre-configured with different periods and types, enabling quick adaptation to various trading strategies, such as trend confirmation or dynamic support/resistance.
How It Works
The script processes price action to detect FVGs by analyzing three-candle patterns where a gap forms between the high/low of the first and third candles. Multi-timeframe data is retrieved using Pine Script’s request.security() function, ensuring accurate FVG plotting across user-defined timeframes. BOS and CHoCH are identified by tracking swing highs and lows, with logic to differentiate trend continuation from reversals. The MA templates are computed using standard Pine Script TA functions, with user inputs controlling visibility and parameters.
How to Use
Add to Chart: Apply the indicator to any TradingView chart.
Configure Settings:
FVG Settings: Adjust the number of historical FVGs to display (default: 10). Enable/disable specific FVG types (bullish, bearish, mitigated).
Timeframe Selection: Choose up to three timeframes for FVG analysis (e.g., 1H, 4H, 1D) to align with your trading strategy.
Structure Settings: Toggle BOS (gray lines) and CHoCH (yellow lines) visibility. Adjust sensitivity for structure detection if needed.
MA Templates: Enable MA curves via the Template section. Select from eight pre-configured MA types and periods to suit your analysis.
Interpret Signals:
Use green/red FVGs for potential entry points targeting liquidity zones.
Monitor gray lines (BOS) for trend continuation and yellow lines (CHoCH) for reversal signals.
Align multi-timeframe FVGs with BOS/CHoCH for high-probability setups.
Optionally, use MA curves for trend confirmation or dynamic levels.
Clean Chart Usage: The indicator is designed to work standalone. Ensure no conflicting scripts are applied unless explicitly needed for your strategy.
Why This Indicator Is Unique
Unlike standalone FVG or SMC indicators, this script combines both concepts with multi-timeframe analysis, offering a comprehensive view of market structure and liquidity. The addition of customizable MA templates enhances flexibility, while the dynamic removal of mitigated FVGs keeps the chart clean. This mashup is purposeful, as it integrates complementary tools to streamline decision-making for traders using SMC strategies.
Credits
This indicator builds on foundational SMC and FVG concepts from the TradingView community. Some open-source code was reused, and do performance enhancement as you guys can read the code. This type of indicators has inspiration was drawn from public domain SMC methodologies. All code is partly original with manual work on performance optimization in Pine Script.
Notes
Ensure your chart is clean (no unnecessary drawings or indicators) to maximize clarity.
The indicator is open-source, and traders are encouraged to review the code for deeper understanding.
For optimal use, test the indicator on a demo account to familiarize yourself with its signals.

High Probability Order Blocks [AlgoAlpha]🟠 OVERVIEW
This script detects and visualizes high-probability order blocks by combining a volatility-based z-score trigger with a statistical survival model inspired by Kaplan-Meier estimation. It builds and manages bullish and bearish order blocks dynamically on the chart, displays live survival probabilities per block, and plots optional rejection signals. What makes this tool unique is its use of historical mitigation behavior to estimate and plot how likely each zone is to persist, offering traders a probabilistic perspective on order block strength—something rarely seen in retail indicators.
🟠 CONCEPTS
Order blocks are regions of strong institutional interest, often marked by large imbalances between buying and selling. This script identifies those areas using z-score thresholds on directional distance (up or down candles), detecting statistically significant moves that signal potential smart money footprints. A bullish block is drawn when a strong up-move (zUp > 4) follows a down candle, and vice versa for bearish blocks. Over time, each block is evaluated: if price “mitigates” it (i.e., closes cleanly past the opposite side and confirmed with a 1 bar delay), it’s considered resolved and logged. These resolved blocks then inform a Kaplan-Meier-like survival curve, estimating the likelihood that future blocks of a given age will remain unbroken. The indicator then draws a probability curve for each side (bull/bear), updating it in real time.
🟠 FEATURES
Live label inside each block showing survival probability or “N.E.D.” if insufficient data.
Kaplan-Meier survival curves drawn directly on the chart to show estimated strength decay.
Rejection markers (▲ ▼) if price bounces cleanly off an active order block.
Alerts for zone creation and rejection signals, supporting rule-based trading workflows.
🟠 USAGE
Read the label inside each block for Age | Survival% (or N.E.D. if there aren’t enough samples yet); higher survival % suggests blocks of that age have historically lasted longer.
Use the right-side survival curves to gauge how probability decays with age for bull vs bear blocks, and align entries with the side showing stronger survival at current age.
Treat ▲ (bullish rejection) and ▼ (bearish rejection) as optional confluence when price tests a boundary and fails to break.
Turn on alerts for “Bullish Zone Created,” “Bearish Zone Created,” and rejection signals so you don’t need to watch constantly.
If your chart gets crowded, enable Prevent Overlap ; tune Max Box Age to your timeframe; and adjust KM Training Window / Minimum Samples to trade off responsiveness vs stability.

Nonlinear Regression, Zero-lag Moving Average [Loxx]Nonlinear Regression and Zero-lag Moving Average
Technical indicators are widely used in financial markets to analyze price data and make informed trading decisions. This indicator presents an implementation of two popular indicators: Nonlinear Regression and Zero-lag Moving Average (ZLMA). Let's explore the functioning of these indicators and discuss their significance in technical analysis.
Nonlinear Regression
The Nonlinear Regression indicator aims to fit a nonlinear curve to a given set of data points. It calculates the best-fit curve by minimizing the sum of squared errors between the actual data points and the predicted values on the curve. The curve is determined by solving a system of equations derived from the data points.
We define a function "nonLinearRegression" that takes two parameters: "src" (the input data series) and "per" (the period over which the regression is calculated). It calculates the coefficients of the nonlinear curve using the least squares method and returns the predicted value for the current period. The nonlinear regression curve provides insights into the overall trend and potential reversals in the price data.
Zero-lag Moving Average (ZLMA)
Moving averages are widely used to smoothen price data and identify trend directions. However, traditional moving averages introduce a lag due to the inclusion of past data. The Zero-lag Moving Average (ZLMA) overcomes this lag by dynamically adjusting the weights of past values, resulting in a more responsive moving average.
We create a function named "zlma" that calculates the ZLMA. It takes two parameters: "src" (the input data series) and "per" (the period over which the ZLMA is calculated). The ZLMA is computed by first calculating a weighted moving average (LWMA) using a linearly decreasing weight scheme. The LWMA is then used to calculate the ZLMA by applying the same weight scheme again. The ZLMA provides a smoother representation of the price data while reducing lag.
Combining Nonlinear Regression and ZLMA
The ZLMA is applied to the input data series using the function "zlma(src, zlmaper)". The ZLMA values are then passed as input to the "nonLinearRegression" function, along with the specified period for nonlinear regression. The output of the nonlinear regression is stored in the variable "out".
To enhance the visual representation of the indicator, colors are assigned based on the relationship between the nonlinear regression value and a signal value (sig) calculated from the previous period's nonlinear regression value. If the current "out" value is greater than the previous "sig" value, the color is set to green; otherwise, it is set to red.
The indicator also includes optional features such as coloring the bars based on the indicator's values and displaying signals for potential long and short positions. The signals are generated based on the crossover and crossunder of the "out" and "sig" values.
Wrapping Up
This indicator combines two important concepts: Nonlinear Regression and Zero-lag Moving Average indicators, which are valuable tools for technical analysis in financial markets. These indicators help traders identify trends, potential reversals, and generate trading signals. By combining the nonlinear regression curve with the zero-lag moving average, this indicator provides a comprehensive view of the price dynamics. Traders can customize the indicator's settings and use it in conjunction with other analysis techniques to make well-informed trading decisions.

Any Oscillator Underlay [TTF]We are proud to release a new indicator that has been a while in the making - the Any Oscillator Underlay (AOU) !
Note: There is a lot to discuss regarding this indicator, including its intent and some of how it operates, so please be sure to read this entire description before using this indicator to help ensure you understand both the intent and some limitations with this tool.
Our intent for building this indicator was to accomplish the following:
Combine all of the oscillators that we like to use into a single indicator
Take up a bit less screen space for the underlay indicators for strategies that utilize multiple oscillators
Provide a tool for newer traders to be able to leverage multiple oscillators in a single indicator
Features:
Includes 8 separate, fully-functional indicators combined into one
Ability to easily enable/disable and configure each included indicator independently
Clearly named plots to support user customization of color and styling, as well as manual creation of alerts
Ability to customize sub-indicator title position and color
Ability to customize sub-indicator divider lines style and color
Indicators that are included in this initial release:
TSI
2x RSIs (dubbed the Twin RSI )
Stochastic RSI
Stochastic
Ultimate Oscillator
Awesome Oscillator
MACD
Outback RSI (Color-coding only)
Quick note on OB/OS:
Before we get into covering each included indicator, we first need to cover a core concept for how we're defining OB and OS levels. To help illustrate this, we will use the TSI as an example.
The TSI by default has a mid-point of 0 and a range of -100 to 100. As a result, a common practice is to place lines on the -30 and +30 levels to represent OS and OB zones, respectively. Most people tend to view these levels as distance from the edges/outer bounds or as absolute levels, but we feel a more way to frame the OB/OS concept is to instead define it as distance ("offset") from the mid-line. In keeping with the -30 and +30 levels in our example, the offset in this case would be "30".
Taking this a step further, let's say we decided we wanted an offset of 25. Since the mid-point is 0, we'd then calculate the OB level as 0 + 25 (+25), and the OS level as 0 - 25 (-25).
Now that we've covered the concept of how we approach defining OB and OS levels (based on offset/distance from the mid-line), and since we did apply some transformations, rescaling, and/or repositioning to all of the indicators noted above, we are going to discuss each component indicator to detail both how it was modified from the original to fit the stacked-indicator model, as well as the various major components that the indicator contains.
TSI:
This indicator contains the following major elements:
TSI and TSI Signal Line
Color-coded fill for the TSI/TSI Signal lines
Moving Average for the TSI
TSI Histogram
Mid-line and OB/OS lines
Default TSI fill color coding:
Green : TSI is above the signal line
Red : TSI is below the signal line
Note: The TSI traditionally has a range of -100 to +100 with a mid-point of 0 (range of 200). To fit into our stacking model, we first shrunk the range to 100 (-50 to +50 - cut it in half), then repositioned it to have a mid-point of 50. Since this is the "bottom" of our indicator-stack, no additional repositioning is necessary.
Twin RSI:
This indicator contains the following major elements:
Fast RSI (useful if you want to leverage 2x RSIs as it makes it easier to see the overlaps and crosses - can be disabled if desired)
Slow RSI (primary RSI)
Color-coded fill for the Fast/Slow RSI lines (if Fast RSI is enabled and configured)
Moving Average for the Slow RSI
Mid-line and OB/OS lines
Default Twin RSI fill color coding:
Dark Red : Fast RSI below Slow RSI and Slow RSI below Slow RSI MA
Light Red : Fast RSI below Slow RSI and Slow RSI above Slow RSI MA
Dark Green : Fast RSI above Slow RSI and Slow RSI below Slow RSI MA
Light Green : Fast RSI above Slow RSI and Slow RSI above Slow RSI MA
Note: The RSI naturally has a range of 0 to 100 with a mid-point of 50, so no rescaling or transformation is done on this indicator. The only manipulation done is to properly position it in the indicator-stack based on which other indicators are also enabled.
Stochastic and Stochastic RSI:
These indicators contain the following major elements:
Configurable lengths for the RSI (for the Stochastic RSI only), K, and D values
Configurable base price source
Mid-line and OB/OS lines
Note: The Stochastic and Stochastic RSI both have a normal range of 0 to 100 with a mid-point of 50, so no rescaling or transformations are done on either of these indicators. The only manipulation done is to properly position it in the indicator-stack based on which other indicators are also enabled.
Ultimate Oscillator (UO):
This indicator contains the following major elements:
Configurable lengths for the Fast, Middle, and Slow BP/TR components
Mid-line and OB/OS lines
Moving Average for the UO
Color-coded fill for the UO/UO MA lines (if UO MA is enabled and configured)
Default UO fill color coding:
Green : UO is above the moving average line
Red : UO is below the moving average line
Note: The UO naturally has a range of 0 to 100 with a mid-point of 50, so no rescaling or transformation is done on this indicator. The only manipulation done is to properly position it in the indicator-stack based on which other indicators are also enabled.
Awesome Oscillator (AO):
This indicator contains the following major elements:
Configurable lengths for the Fast and Slow moving averages used in the AO calculation
Configurable price source for the moving averages used in the AO calculation
Mid-line
Option to display the AO as a line or pseudo-histogram
Moving Average for the AO
Color-coded fill for the AO/AO MA lines (if AO MA is enabled and configured)
Default AO fill color coding (Note: Fill was disabled in the image above to improve clarity):
Green : AO is above the moving average line
Red : AO is below the moving average line
Note: The AO is technically has an infinite (unbound) range - -∞ to ∞ - and the effective range is bound to the underlying security price (e.g. BTC will have a wider range than SP500, and SP500 will have a wider range than EUR/USD). We employed some special techniques to rescale this indicator into our desired range of 100 (-50 to 50), and then repositioned it to have a midpoint of 50 (range of 0 to 100) to meet the constraints of our stacking model. We then do one final repositioning to place it in the correct position the indicator-stack based on which other indicators are also enabled. For more details on how we accomplished this, read our section "Binding Infinity" below.
MACD:
This indicator contains the following major elements:
Configurable lengths for the Fast and Slow moving averages used in the MACD calculation
Configurable price source for the moving averages used in the MACD calculation
Configurable length and calculation method for the MACD Signal Line calculation
Mid-line
Note: Like the AO, the MACD also technically has an infinite (unbound) range. We employed the same principles here as we did with the AO to rescale and reposition this indicator as well. For more details on how we accomplished this, read our section "Binding Infinity" below.
Outback RSI (ORSI):
This is a stripped-down version of the Outback RSI indicator (linked above) that only includes the color-coding background (suffice it to say that it was not technically feasible to attempt to rescale the other components in a way that could consistently be clearly seen on-chart). As this component is a bit of a niche/special-purpose sub-indicator, it is disabled by default, and we suggest it remain disabled unless you have some pre-defined strategy that leverages the color-coding element of the Outback RSI that you wish to use.
Binding Infinity - How We Incorporated the AO and MACD (Warning - Math Talk Ahead!)
Note: This applies only to the AO and MACD at time of original publication. If any other indicators are added in the future that also fall into the category of "binding an infinite-range oscillator", we will make that clear in the release notes when that new addition is published.
To help set the stage for this discussion, it's important to note that the broader challenge of "equalizing inputs" is nothing new. In fact, it's a key element in many of the most popular fields of data science, such as AI and Machine Learning. They need to take a diverse set of inputs with a wide variety of ranges and seemingly-random inputs (referred to as "features"), and build a mathematical or computational model in order to work. But, when the raw inputs can vary significantly from one another, there is an inherent need to do some pre-processing to those inputs so that one doesn't overwhelm another simply due to the difference in raw values between them. This is where feature scaling comes into play.
With this in mind, we implemented 2 of the most common methods of Feature Scaling - Min-Max Normalization (which we call "Normalization" in our settings), and Z-Score Normalization (which we call "Standardization" in our settings). Let's take a look at each of those methods as they have been implemented in this script.
Min-Max Normalization (Normalization)
This is one of the most common - and most basic - methods of feature scaling. The basic formula is: y = (x - min)/(max - min) - where x is the current data sample, min is the lowest value in the dataset, and max is the highest value in the dataset. In this transformation, the max would evaluate to 1, and the min would evaluate to 0, and any value in between the min and the max would evaluate somewhere between 0 and 1.
The key benefits of this method are:
It can be used to transform datasets of any range into a new dataset with a consistent and known range (0 to 1).
It has no dependency on the "shape" of the raw input dataset (i.e. does not assume the input dataset can be approximated to a normal distribution).
But there are a couple of "gotchas" with this technique...
First, it assumes the input dataset is complete, or an accurate representation of the population via random sampling. While in most situations this is a valid assumption, in trading indicators we don't really have that luxury as we're often limited in what sample data we can access (i.e. number of historical bars available).
Second, this method is highly sensitive to outliers. Since the crux of this transformation is based on the max-min to define the initial range, a single significant outlier can result in skewing the post-transformation dataset (i.e. major price movement as a reaction to a significant news event).
You can potentially mitigate those 2 "gotchas" by using a mechanism or technique to find and discard outliers (e.g. calculate the mean and standard deviation of the input dataset and discard any raw values more than 5 standard deviations from the mean), but if your most recent datapoint is an "outlier" as defined by that algorithm, processing it using the "scrubbed" dataset would result in that new datapoint being outside the intended range of 0 to 1 (e.g. if the new datapoint is greater than the "scrubbed" max, it's post-transformation value would be greater than 1). Even though this is a bit of an edge-case scenario, it is still sure to happen in live markets processing live data, so it's not an ideal solution in our opinion (which is why we chose not to attempt to discard outliers in this manner).
Z-Score Normalization (Standardization)
This method of rescaling is a bit more complex than the Min-Max Normalization method noted above, but it is also a widely used process. The basic formula is: y = (x – μ) / σ - where x is the current data sample, μ is the mean (average) of the input dataset, and σ is the standard deviation of the input dataset. While this transformation still results in a technically-infinite possible range, the output of this transformation has a 2 very significant properties - the mean (average) of the output dataset has a mean (μ) of 0 and a standard deviation (σ) of 1.
The key benefits of this method are:
As it's based on normalizing the mean and standard deviation of the input dataset instead of a linear range conversion, it is far less susceptible to outliers significantly affecting the result (and in fact has the effect of "squishing" outliers).
It can be used to accurately transform disparate sets of data into a similar range regardless of the original dataset's raw/actual range.
But there are a couple of "gotchas" with this technique as well...
First, it still technically does not do any form of range-binding, so it is still technically unbounded (range -∞ to ∞ with a mid-point of 0).
Second, it implicitly assumes that the raw input dataset to be transformed is normally distributed, which won't always be the case in financial markets.
The first "gotcha" is a bit of an annoyance, but isn't a huge issue as we can apply principles of normal distribution to conceptually limit the range by defining a fixed number of standard deviations from the mean. While this doesn't totally solve the "infinite range" problem (a strong enough sudden move can still break out of our "conceptual range" boundaries), the amount of movement needed to achieve that kind of impact will generally be pretty rare.
The bigger challenge is how to deal with the assumption of the input dataset being normally distributed. While most financial markets (and indicators) do tend towards a normal distribution, they are almost never going to match that distribution exactly. So let's dig a bit deeper into distributions are defined and how things like trending markets can affect them.
Skew (skewness): This is a measure of asymmetry of the bell curve, or put another way, how and in what way the bell curve is disfigured when comparing the 2 halves. The easiest way to visualize this is to draw an imaginary vertical line through the apex of the bell curve, then fold the curve in half along that line. If both halves are exactly the same, the skew is 0 (no skew/perfectly symmetrical) - which is what a normal distribution has (skew = 0). Most financial markets tend to have short, medium, and long-term trends, and these trends will cause the distribution curve to skew in one direction or another. Bullish markets tend to skew to the right (positive), and bearish markets to the left (negative).
Kurtosis: This is a measure of the "tail size" of the bell curve. Another way to state this could be how "flat" or "steep" the bell-shape is. If the bell is steep with a strong drop from the apex (like a steep cliff), it has low kurtosis. If the bell has a shallow, more sweeping drop from the apex (like a tall hill), is has high kurtosis. Translating this to financial markets, kurtosis is generally a metric of volatility as the bell shape is largely defined by the strength and frequency of outliers. This is effectively a measure of volatility - volatile markets tend to have a high level of kurtosis (>3), and stable/consolidating markets tend to have a low level of kurtosis (<3). A normal distribution (our reference), has a kurtosis value of 3.
So to try and bring all that back together, here's a quick recap of the Standardization rescaling method:
The Standardization method has an assumption of a normal distribution of input data by using the mean (average) and standard deviation to handle the transformation
Most financial markets do NOT have a normal distribution (as discussed above), and will have varying degrees of skew and kurtosis
Q: Why are we still favoring the Standardization method over the Normalization method, and how are we accounting for the innate skew and/or kurtosis inherent in most financial markets?
A: Well, since we're only trying to rescale oscillators that by-definition have a midpoint of 0, kurtosis isn't a major concern beyond the affect it has on the post-transformation scaling (specifically, the number of standard deviations from the mean we need to include in our "artificially-bound" range definition).
Q: So that answers the question about kurtosis, but what about skew?
A: So - for skew, the answer is in the formula - specifically the mean (average) element. The standard mean calculation assumes a complete dataset and therefore uses a standard (i.e. simple) average, but we're limited by the data history available to us. So we adapted the transformation formula to leverage a moving average that included a weighting element to it so that it favored recent datapoints more heavily than older ones. By making the average component more adaptive, we gained the effect of reducing the skew element by having the average itself be more responsive to recent movements, which significantly reduces the effect historical outliers have on the dataset as a whole. While this is certainly not a perfect solution, we've found that it serves the purpose of rescaling the MACD and AO to a far more well-defined range while still preserving the oscillator behavior and mid-line exceptionally well.
The most difficult parts to compensate for are periods where markets have low volatility for an extended period of time - to the point where the oscillators are hovering around the 0/midline (in the case of the AO), or when the oscillator and signal lines converge and remain close to each other (in the case of the MACD). It's during these periods where even our best attempt at ensuring accurate mirrored-behavior when compared to the original can still occasionally lead or lag by a candle.
Note: If this is a make-or-break situation for you or your strategy, then we recommend you do not use any of the included indicators that leverage this kind of bounding technique (the AO and MACD at time of publication) and instead use the Trandingview built-in versions!
We know this is a lot to read and digest, so please take your time and feel free to ask questions - we will do our best to answer! And as always, constructive feedback is always welcome!
