PineStats█ OVERVIEW
PineStats is a comprehensive statistical analysis library for Pine Script v6, providing 104 functions across 6 modules. Built for quantitative traders, researchers, and indicator developers who need professional-grade statistics without reinventing the wheel.
For building mean-reversion strategies, analyzing return distributions, measuring correlations, or testing for market regimes.
█ MODULES
CORE STATISTICS (20 functions)
• Central tendency: mean, median, WMA, EMA
• Dispersion: variance, stdev, MAD, range
• Standardization: z-score, robust z-score, normalize, percentile
• Distribution shape: skewness, kurtosis
PROBABILITY DISTRIBUTIONS (17 functions)
• Normal: PDF, CDF, inverse CDF (quantile function)
• Power-law: Hill estimator, MLE alpha, survival function
• Exponential: PDF, CDF, rate estimation
• Normality testing: Jarque-Bera test
ENTROPY (9 functions)
• Shannon entropy (information theory)
• Tsallis entropy (non-extensive, fat-tail sensitive)
• Permutation entropy (ordinal patterns)
• Approximate entropy (regularity measure)
• Entropy-based regime detection
PROBABILITY (21 functions)
• Win rates and expected value
• First passage time estimation
• TP/SL probability analysis
• Conditional probability and Bayes updates
• Streak and drawdown probabilities
REGRESSION (19 functions)
• Linear regression: slope, intercept, forecast
• Goodness of fit: R², adjusted R², standard error
• Statistical tests: t-statistic, p-value, significance
• Trend analysis: strength, angle, acceleration
• Quadratic regression
CORRELATION (18 functions)
• Pearson, Spearman, Kendall correlation
• Covariance, beta, alpha (Jensen's)
• Rolling correlation analysis
• Autocorrelation and cross-correlation
• Information ratio, tracking error
█ QUICK START
import HenriqueCentieiro/PineStats/1 as stats
// Z-score for mean reversion
z = stats.zscore(close, 20)
// Test if returns are normally distributed
returns = (close - close ) / close
isGaussian = stats.is_normal(returns, 100, 0.05)
// Regression channel
= stats.linreg_channel(close, 50, 2.0)
// Correlation with benchmark
spyReturns = request.security("SPY", timeframe.period, close/close - 1)
beta = stats.beta(returns, spyReturns, 60)
█ USE CASES
✓ Mean Reversion — z-scores, percentiles, Bollinger-style analysis
✓ Regime Detection — entropy measures, correlation regimes
✓ Risk Analysis — drawdown probability, VaR via quantiles
✓ Strategy Evaluation — expected value, win rates, R:R analysis
✓ Distribution Analysis — normality tests, fat-tail detection
✓ Multi-Asset — beta, alpha, correlation, relative strength
█ NOTES
• All functions return `na` on invalid inputs
• Designed for Pine Script v6
• Fully documented in the library header
• Part of the Pine ecosystem: PineStats, PineQuant, PineCriticality, PineWavelet
█ REFERENCES
• Abramowitz & Stegun — Normal CDF approximation
• Acklam's algorithm — Inverse normal CDF
• Hill estimator — Power-law tail estimation
• Tsallis statistics — Non-extensive entropy
Full documentation in the library header.
mean(src, length)
Calculates the arithmetic mean (simple moving average) over a lookback period
Parameters:
src (float) : Source series
length (simple int) : Lookback period (must be >= 1)
Returns: Arithmetic mean of the last `length` values, or `na` if inputs invalid
wma_custom(src, length)
Calculates weighted moving average with linearly decreasing weights
Parameters:
src (float) : Source series
length (simple int) : Lookback period (must be >= 1)
Returns: Weighted moving average, or `na` if inputs invalid
ema_custom(src, length)
Calculates exponential moving average
Parameters:
src (float) : Source series
length (simple int) : Lookback period (must be >= 1)
Returns: Exponential moving average, or `na` if inputs invalid
median(src, length)
Calculates the median value over a lookback period
Parameters:
src (float) : Source series
length (simple int) : Lookback period (must be >= 1)
Returns: Median value, or `na` if inputs invalid
variance(src, length)
Calculates population variance over a lookback period
Parameters:
src (float) : Source series
length (simple int) : Lookback period (must be >= 1)
Returns: Population variance, or `na` if inputs invalid
stdev(src, length)
Calculates population standard deviation over a lookback period
Parameters:
src (float) : Source series
length (simple int) : Lookback period (must be >= 1)
Returns: Population standard deviation, or `na` if inputs invalid
mad(src, length)
Calculates Median Absolute Deviation (MAD) - robust dispersion measure
Parameters:
src (float) : Source series
length (simple int) : Lookback period (must be >= 1)
Returns: MAD value, or `na` if inputs invalid
data_range(src, length)
Calculates the range (highest - lowest) over a lookback period
Parameters:
src (float) : Source series
length (simple int) : Lookback period (must be >= 1)
Returns: Range value, or `na` if inputs invalid
zscore(src, length)
Calculates z-score (number of standard deviations from mean)
Parameters:
src (float) : Source series
length (simple int) : Lookback period for mean and stdev calculation (must be >= 2)
Returns: Z-score, or `na` if inputs invalid or stdev is zero
zscore_robust(src, length)
Calculates robust z-score using median and MAD (resistant to outliers)
Parameters:
src (float) : Source series
length (simple int) : Lookback period (must be >= 2)
Returns: Robust z-score, or `na` if inputs invalid or MAD is zero
normalize(src, length)
Normalizes value to range using min-max scaling
Parameters:
src (float) : Source series
length (simple int) : Lookback period (must be >= 1)
Returns: Normalized value in , or `na` if inputs invalid or range is zero
percentile(src, length)
Calculates percentile rank of current value within lookback window
Parameters:
src (float) : Source series
length (simple int) : Lookback period (must be >= 1)
Returns: Percentile rank (0 to 100), or `na` if inputs invalid
winsorize(src, length, lower_pct, upper_pct)
Winsorizes values by clamping to percentile bounds (reduces outlier impact)
Parameters:
src (float) : Source series
length (simple int) : Lookback period (must be >= 1)
lower_pct (simple float) : Lower percentile bound (0-100, e.g., 5 for 5th percentile)
upper_pct (simple float) : Upper percentile bound (0-100, e.g., 95 for 95th percentile)
Returns: Winsorized value clamped to bounds
skewness(src, length)
Calculates sample skewness (measure of distribution asymmetry)
Parameters:
src (float) : Source series
length (simple int) : Lookback period (must be >= 3)
Returns: Skewness value (negative = left tail, positive = right tail), or `na` if invalid
kurtosis(src, length)
Calculates excess kurtosis (measure of distribution tail heaviness)
Parameters:
src (float) : Source series
length (simple int) : Lookback period (must be >= 4)
Returns: Excess kurtosis (>0 = heavy tails, <0 = light tails), or `na` if invalid
count_valid(src, length)
Counts non-na values in lookback window (useful for data quality checks)
Parameters:
src (float) : Source series
length (simple int) : Lookback period (must be >= 1)
Returns: Count of valid (non-na) values
sum(src, length)
Calculates sum over lookback period
Parameters:
src (float) : Source series
length (simple int) : Lookback period (must be >= 1)
Returns: Sum of values, or `na` if inputs invalid
cumsum(src)
Calculates cumulative sum (running total from first bar)
Parameters:
src (float) : Source series
Returns: Cumulative sum
change(src, length)
Returns the change (difference) from n bars ago
Parameters:
src (float) : Source series
length (simple int) : Number of bars to look back (must be >= 1)
Returns: Current value minus value from `length` bars ago
roc(src, length)
Calculates Rate of Change (percentage change from n bars ago)
Parameters:
src (float) : Source series
length (simple int) : Number of bars to look back (must be >= 1)
Returns: Percentage change as decimal (0.05 = 5%), or `na` if invalid
normal_pdf_standard(x)
Calculates the standard normal probability density function (PDF)
Parameters:
x (float) : The value to evaluate
Returns: PDF value at x for standard normal N(0,1)
normal_pdf(x, mu, sigma)
Calculates the normal probability density function (PDF)
Parameters:
x (float) : The value to evaluate
mu (float) : Mean of the distribution (default: 0)
sigma (float) : Standard deviation (default: 1, must be > 0)
Returns: PDF value at x for normal N(mu, sigma²)
normal_cdf_standard(x)
Calculates the standard normal cumulative distribution function (CDF)
Parameters:
x (float) : The value to evaluate
Returns: Probability P(X <= x) for standard normal N(0,1)
@description Uses Abramowitz & Stegun approximation (formula 7.1.26), accurate to ~1.5e-7
normal_cdf(x, mu, sigma)
Calculates the normal cumulative distribution function (CDF)
Parameters:
x (float) : The value to evaluate
mu (float) : Mean of the distribution (default: 0)
sigma (float) : Standard deviation (default: 1, must be > 0)
Returns: Probability P(X <= x) for normal N(mu, sigma²)
normal_inv_standard(p)
Calculates the inverse standard normal CDF (quantile function)
Parameters:
p (float) : Probability value (must be in (0, 1))
Returns: x such that P(X <= x) = p for standard normal N(0,1)
@description Uses Acklam's algorithm, accurate to ~1.15e-9
normal_inv(p, mu, sigma)
Calculates the inverse normal CDF (quantile function)
Parameters:
p (float) : Probability value (must be in (0, 1))
mu (float) : Mean of the distribution
sigma (float) : Standard deviation (must be > 0)
Returns: x such that P(X <= x) = p for normal N(mu, sigma²)
power_law_alpha(src, length, tail_pct)
Estimates power-law exponent (alpha) using Hill estimator
Parameters:
src (float) : Source series (typically absolute returns or drawdowns)
length (simple int) : Lookback period (must be >= 10 for reliable estimates)
tail_pct (simple float) : Percentage of data to use for tail estimation (default: 0.1 = top 10%)
Returns: Estimated alpha (tail index), typically 2-4 for financial data
@description Alpha < 2 indicates infinite variance (very heavy tails)
@description Alpha < 3 indicates infinite kurtosis
@description Alpha > 4 suggests near-Gaussian behavior
power_law_alpha_mle(src, length, x_min)
Estimates power-law alpha using maximum likelihood (Clauset method)
Parameters:
src (float) : Source series (positive values expected)
length (simple int) : Lookback period (must be >= 20)
x_min (float) : Minimum threshold for power-law behavior
Returns: Estimated alpha using MLE
power_law_pdf(x, alpha, x_min)
Calculates power-law probability density (Pareto Type I)
Parameters:
x (float) : Value to evaluate (must be >= x_min)
alpha (float) : Power-law exponent (must be > 1)
x_min (float) : Minimum value / scale parameter (must be > 0)
Returns: PDF value
power_law_survival(x, alpha, x_min)
Calculates power-law survival function P(X > x)
Parameters:
x (float) : Value to evaluate (must be >= x_min)
alpha (float) : Power-law exponent (must be > 1)
x_min (float) : Minimum value / scale parameter (must be > 0)
Returns: Probability of exceeding x
power_law_ks(src, length, alpha, x_min)
Tests if data follows power-law using simplified Kolmogorov-Smirnov
Parameters:
src (float) : Source series
length (simple int) : Lookback period
alpha (float) : Estimated alpha from power_law_alpha()
x_min (float) : Threshold value
Returns: KS statistic (lower = better fit, typically < 0.1 for good fit)
is_power_law(src, length, tail_pct, ks_threshold)
Simple test if distribution appears to follow power-law
Parameters:
src (float) : Source series
length (simple int) : Lookback period
tail_pct (simple float) : Tail percentage for alpha estimation
ks_threshold (simple float) : Maximum KS statistic for acceptance (default: 0.1)
Returns: true if KS test suggests power-law fit
exp_pdf(x, lambda)
Calculates exponential probability density function
Parameters:
x (float) : Value to evaluate (must be >= 0)
lambda (float) : Rate parameter (must be > 0)
Returns: PDF value
exp_cdf(x, lambda)
Calculates exponential cumulative distribution function
Parameters:
x (float) : Value to evaluate (must be >= 0)
lambda (float) : Rate parameter (must be > 0)
Returns: Probability P(X <= x)
exp_lambda(src, length)
Estimates exponential rate parameter (lambda) using MLE
Parameters:
src (float) : Source series (positive values)
length (simple int) : Lookback period
Returns: Estimated lambda (1/mean)
jarque_bera(src, length)
Calculates Jarque-Bera test statistic for normality
Parameters:
src (float) : Source series
length (simple int) : Lookback period (must be >= 10)
Returns: JB statistic (higher = more deviation from normality)
@description Under normality, JB ~ chi-squared(2). JB > 6 suggests non-normality at 5% level
is_normal(src, length, significance)
Tests if distribution is approximately normal
Parameters:
src (float) : Source series
length (simple int) : Lookback period
significance (simple float) : Significance level (default: 0.05)
Returns: true if Jarque-Bera test does not reject normality
shannon_entropy(src, length, n_bins)
Calculates Shannon entropy from a probability distribution
Parameters:
src (float) : Source series
length (simple int) : Lookback period (must be >= 10)
n_bins (simple int) : Number of histogram bins for discretization (default: 10)
Returns: Shannon entropy in bits (log base 2)
@description Higher entropy = more randomness/uncertainty, lower = more predictability
shannon_entropy_norm(src, length, n_bins)
Calculates normalized Shannon entropy
Parameters:
src (float) : Source series
length (simple int) : Lookback period
n_bins (simple int) : Number of histogram bins
Returns: Normalized entropy where 0 = perfectly predictable, 1 = maximum randomness
tsallis_entropy(src, length, q, n_bins)
Calculates Tsallis entropy with q-parameter
Parameters:
src (float) : Source series
length (simple int) : Lookback period (must be >= 10)
q (float) : Entropic index (q=1 recovers Shannon entropy)
n_bins (simple int) : Number of histogram bins
Returns: Tsallis entropy value
@description q < 1: emphasizes rare events (fat tails)
@description q = 1: equivalent to Shannon entropy
@description q > 1: emphasizes common events
optimal_q(src, length)
Estimates optimal q parameter from kurtosis
Parameters:
src (float) : Source series
length (simple int) : Lookback period
Returns: Estimated q value that best captures the distribution's tail behavior
@description Uses relationship: q ≈ (5 + kurtosis) / (3 + kurtosis) for kurtosis > 0
tsallis_q_gaussian(x, q, beta)
Calculates Tsallis q-Gaussian probability density
Parameters:
x (float) : Value to evaluate
q (float) : Tsallis q parameter (must be < 3)
beta (float) : Width parameter (inverse temperature, must be > 0)
Returns: q-Gaussian PDF value
@description q=1 recovers standard Gaussian
permutation_entropy(src, length, order)
Calculates permutation entropy (ordinal pattern complexity)
Parameters:
src (float) : Source series
length (simple int) : Lookback period (must be >= 20)
order (simple int) : Embedding dimension / pattern length (2-5, default: 3)
Returns: Normalized permutation entropy
@description Measures complexity of temporal ordering patterns
@description 0 = perfectly predictable sequence, 1 = random
approx_entropy(src, length, m, r)
Calculates Approximate Entropy (ApEn) - regularity measure
Parameters:
src (float) : Source series
length (simple int) : Lookback period (must be >= 50)
m (simple int) : Embedding dimension (default: 2)
r (simple float) : Tolerance as fraction of stdev (default: 0.2)
Returns: Approximate entropy value (higher = more irregular/complex)
@description Lower ApEn indicates more self-similarity and predictability
entropy_regime(src, length, q, n_bins)
Detects market regime based on entropy level
Parameters:
src (float) : Source series (typically returns)
length (simple int) : Lookback period
q (float) : Tsallis q parameter (use optimal_q() or default 1.5)
n_bins (simple int) : Number of histogram bins
Returns: Regime indicator: -1 = trending (low entropy), 0 = transition, 1 = ranging (high entropy)
entropy_risk(src, length)
Calculates entropy-based risk indicator
Parameters:
src (float) : Source series (typically returns)
length (simple int) : Lookback period
Returns: Risk score where 1 = maximum divergence from Gaussian 1
hit_rate(src, length)
Calculates hit rate (probability of positive outcome) over lookback
Parameters:
src (float) : Source series (positive values count as hits)
length (simple int) : Lookback period
Returns: Hit rate as decimal
hit_rate_cond(condition, length)
Calculates hit rate for custom condition over lookback
Parameters:
condition (bool) : Boolean series (true = hit)
length (simple int) : Lookback period
Returns: Hit rate as decimal
expected_value(src, length)
Calculates expected value of a series
Parameters:
src (float) : Source series
length (simple int) : Lookback period
Returns: Expected value (mean)
expected_value_trade(win_prob, take_profit, stop_loss)
Calculates expected value for a trade with TP and SL levels
Parameters:
win_prob (float) : Probability of hitting TP (0-1)
take_profit (float) : Take profit in price units or %
stop_loss (float) : Stop loss in price units or % (positive value)
Returns: Expected value per trade
@description EV = (win_prob * TP) - ((1 - win_prob) * SL)
breakeven_winrate(take_profit, stop_loss)
Calculates breakeven win rate for given TP/SL ratio
Parameters:
take_profit (float) : Take profit distance
stop_loss (float) : Stop loss distance
Returns: Required win rate for breakeven (EV = 0)
reward_risk_ratio(take_profit, stop_loss)
Calculates the reward-to-risk ratio
Parameters:
take_profit (float) : Take profit distance
stop_loss (float) : Stop loss distance
Returns: R:R ratio
fpt_probability(src, length, target, max_bars)
Estimates probability of price reaching target within N bars
Parameters:
src (float) : Source series (typically returns)
length (simple int) : Lookback for volatility estimation
target (float) : Target move (in same units as src, e.g., % return)
max_bars (simple int) : Maximum bars to consider
Returns: Probability of reaching target within max_bars
@description Based on random walk with drift approximation
fpt_mean(src, length, target)
Estimates mean first passage time to target level
Parameters:
src (float) : Source series (typically returns)
length (simple int) : Lookback for volatility estimation
target (float) : Target move
Returns: Expected number of bars to reach target (can be infinite)
fpt_historical(src, length, target)
Counts historical bars to reach target from each point
Parameters:
src (float) : Source series (typically price or returns)
length (simple int) : Lookback period
target (float) : Target move from each starting point
Returns: Array of first passage times (na if target not reached within lookback)
tp_probability(src, length, tp_distance, sl_distance)
Estimates probability of hitting TP before SL
Parameters:
src (float) : Source series (typically returns)
length (simple int) : Lookback for estimation
tp_distance (float) : Take profit distance (positive)
sl_distance (float) : Stop loss distance (positive)
Returns: Probability of TP being hit first
trade_probability(src, length, tp_pct, sl_pct)
Calculates complete trade probability and EV analysis
Parameters:
src (float) : Source series (typically returns)
length (simple int) : Lookback period
tp_pct (float) : Take profit percentage
sl_pct (float) : Stop loss percentage
Returns: Tuple:
cond_prob(condition_a, condition_b, length)
Calculates conditional probability P(B|A) from historical data
Parameters:
condition_a (bool) : Condition A (the given condition)
condition_b (bool) : Condition B (the outcome)
length (simple int) : Lookback period
Returns: P(B|A) = P(A and B) / P(A)
bayes_update(prior, likelihood, false_positive)
Updates probability using Bayes' theorem
Parameters:
prior (float) : Prior probability P(H)
likelihood (float) : P(E|H) - probability of evidence given hypothesis
false_positive (float) : P(E|~H) - probability of evidence given hypothesis is false
Returns: Posterior probability P(H|E)
streak_prob(win_rate, streak_length)
Calculates probability of N consecutive wins given win rate
Parameters:
win_rate (float) : Single-trade win probability
streak_length (simple int) : Number of consecutive wins
Returns: Probability of streak
losing_streak_prob(win_rate, streak_length)
Calculates probability of experiencing N consecutive losses
Parameters:
win_rate (float) : Single-trade win probability
streak_length (simple int) : Number of consecutive losses
Returns: Probability of losing streak
drawdown_prob(src, length, dd_threshold)
Estimates probability of drawdown exceeding threshold
Parameters:
src (float) : Source series (returns)
length (simple int) : Lookback period
dd_threshold (float) : Drawdown threshold (as positive decimal, e.g., 0.10 = 10%)
Returns: Historical probability of exceeding drawdown threshold
prob_to_odds(prob)
Calculates odds from probability
Parameters:
prob (float) : Probability (0-1)
Returns: Odds (prob / (1 - prob))
odds_to_prob(odds)
Calculates probability from odds
Parameters:
odds (float) : Odds ratio
Returns: Probability (0-1)
implied_prob(decimal_odds)
Calculates implied probability from decimal odds (betting)
Parameters:
decimal_odds (float) : Decimal odds (e.g., 2.5 means $2.50 return per $1 bet)
Returns: Implied probability
logit(prob)
Calculates log-odds (logit) from probability
Parameters:
prob (float) : Probability (must be in (0, 1))
Returns: Log-odds
inv_logit(log_odds)
Calculates probability from log-odds (inverse logit / sigmoid)
Parameters:
log_odds (float) : Log-odds value
Returns: Probability (0-1)
linreg_slope(src, length)
Calculates linear regression slope
Parameters:
src (float) : Source series
length (simple int) : Lookback period (must be >= 2)
Returns: Slope coefficient (change per bar)
linreg_intercept(src, length)
Calculates linear regression intercept
Parameters:
src (float) : Source series
length (simple int) : Lookback period (must be >= 2)
Returns: Intercept (predicted value at oldest bar in window)
linreg_value(src, length)
Calculates predicted value at current bar using linear regression
Parameters:
src (float) : Source series
length (simple int) : Lookback period
Returns: Predicted value at current bar (end of regression line)
linreg_forecast(src, length, offset)
Forecasts value N bars ahead using linear regression
Parameters:
src (float) : Source series
length (simple int) : Lookback period for regression
offset (simple int) : Bars ahead to forecast (positive = future)
Returns: Forecasted value
linreg_channel(src, length, mult)
Calculates linear regression channel with bands
Parameters:
src (float) : Source series
length (simple int) : Lookback period
mult (simple float) : Standard deviation multiplier for bands
Returns: Tuple:
r_squared(src, length)
Calculates R-squared (coefficient of determination)
Parameters:
src (float) : Source series
length (simple int) : Lookback period
Returns: R² value where 1 = perfect linear fit
adj_r_squared(src, length)
Calculates adjusted R-squared (accounts for sample size)
Parameters:
src (float) : Source series
length (simple int) : Lookback period
Returns: Adjusted R² value
std_error(src, length)
Calculates standard error of estimate (residual standard deviation)
Parameters:
src (float) : Source series
length (simple int) : Lookback period
Returns: Standard error
residual(src, length)
Calculates residual at current bar
Parameters:
src (float) : Source series
length (simple int) : Lookback period
Returns: Residual (actual - predicted)
residuals(src, length)
Returns array of all residuals in lookback window
Parameters:
src (float) : Source series
length (simple int) : Lookback period
Returns: Array of residuals
t_statistic(src, length)
Calculates t-statistic for slope coefficient
Parameters:
src (float) : Source series
length (simple int) : Lookback period
Returns: T-statistic (slope / standard error of slope)
slope_pvalue(src, length)
Approximates p-value for slope t-test (two-tailed)
Parameters:
src (float) : Source series
length (simple int) : Lookback period
Returns: Approximate p-value
is_significant(src, length, alpha)
Tests if regression slope is statistically significant
Parameters:
src (float) : Source series
length (simple int) : Lookback period
alpha (simple float) : Significance level (default: 0.05)
Returns: true if slope is significant at alpha level
trend_strength(src, length)
Calculates normalized trend strength based on R² and slope
Parameters:
src (float) : Source series
length (simple int) : Lookback period
Returns: Trend strength where sign indicates direction
trend_angle(src, length)
Calculates trend angle in degrees
Parameters:
src (float) : Source series
length (simple int) : Lookback period
Returns: Angle in degrees (positive = uptrend, negative = downtrend)
linreg_acceleration(src, length)
Calculates trend acceleration (second derivative)
Parameters:
src (float) : Source series
length (simple int) : Lookback period for each regression
Returns: Acceleration (change in slope)
linreg_deviation(src, length)
Calculates deviation from regression line in standard error units
Parameters:
src (float) : Source series
length (simple int) : Lookback period
Returns: Deviation in standard error units (like z-score)
quadreg_coefficients(src, length)
Fits quadratic regression and returns coefficients
Parameters:
src (float) : Source series
length (simple int) : Lookback period (must be >= 4)
Returns: Tuple: for y = a*x² + b*x + c
quadreg_value(src, length)
Calculates quadratic regression value at current bar
Parameters:
src (float) : Source series
length (simple int) : Lookback period
Returns: Predicted value from quadratic fit
correlation(x, y, length)
Calculates Pearson correlation coefficient between two series
Parameters:
x (float) : First series
y (float) : Second series
length (simple int) : Lookback period (must be >= 3)
Returns: Correlation coefficient
covariance(x, y, length)
Calculates sample covariance between two series
Parameters:
x (float) : First series
y (float) : Second series
length (simple int) : Lookback period (must be >= 2)
Returns: Covariance value
beta(asset, benchmark, length)
Calculates beta coefficient (slope of regression of y on x)
Parameters:
asset (float) : Asset returns series
benchmark (float) : Benchmark returns series
length (simple int) : Lookback period
Returns: Beta coefficient
@description Beta = Cov(asset, benchmark) / Var(benchmark)
alpha(asset, benchmark, length, risk_free)
Calculates alpha (Jensen's alpha / intercept)
Parameters:
asset (float) : Asset returns series
benchmark (float) : Benchmark returns series
length (simple int) : Lookback period
risk_free (float) : Risk-free rate (default: 0)
Returns: Alpha value (excess return not explained by beta)
spearman(x, y, length)
Calculates Spearman rank correlation coefficient
Parameters:
x (float) : First series
y (float) : Second series
length (simple int) : Lookback period (must be >= 3)
Returns: Spearman correlation
@description More robust to outliers than Pearson correlation
kendall_tau(x, y, length)
Calculates Kendall's tau rank correlation (simplified)
Parameters:
x (float) : First series
y (float) : Second series
length (simple int) : Lookback period (must be >= 3)
Returns: Kendall's tau
correlation_change(x, y, length, change_period)
Calculates change in correlation over time
Parameters:
x (float) : First series
y (float) : Second series
length (simple int) : Lookback period for correlation
change_period (simple int) : Period over which to measure change
Returns: Change in correlation
correlation_regime(x, y, length, ma_length)
Detects correlation regime based on level and stability
Parameters:
x (float) : First series
y (float) : Second series
length (simple int) : Lookback period for correlation
ma_length (simple int) : Moving average length for smoothing
Returns: Regime: -1 = negative, 0 = uncorrelated, 1 = positive
correlation_stability(x, y, length, stability_length)
Calculates correlation stability (inverse of volatility)
Parameters:
x (float) : First series
y (float) : Second series
length (simple int) : Lookback for correlation
stability_length (simple int) : Lookback for stability calculation
Returns: Stability score where 1 = perfectly stable
relative_strength(asset, benchmark, length)
Calculates relative strength of asset vs benchmark
Parameters:
asset (float) : Asset price series
benchmark (float) : Benchmark price series
length (simple int) : Smoothing period
Returns: Relative strength ratio (normalized)
tracking_error(asset, benchmark, length)
Calculates tracking error (standard deviation of excess returns)
Parameters:
asset (float) : Asset returns
benchmark (float) : Benchmark returns
length (simple int) : Lookback period
Returns: Tracking error (annualize by multiplying by sqrt(252) for daily data)
information_ratio(asset, benchmark, length)
Calculates information ratio (risk-adjusted excess return)
Parameters:
asset (float) : Asset returns
benchmark (float) : Benchmark returns
length (simple int) : Lookback period
Returns: Information ratio
capture_ratio(asset, benchmark, length, up_capture)
Calculates up/down capture ratio
Parameters:
asset (float) : Asset returns
benchmark (float) : Benchmark returns
length (simple int) : Lookback period
up_capture (simple bool) : If true, calculate up capture; if false, down capture
Returns: Capture ratio
autocorrelation(src, length, lag)
Calculates autocorrelation at specified lag
Parameters:
src (float) : Source series
length (simple int) : Lookback period
lag (simple int) : Lag for autocorrelation (default: 1)
Returns: Autocorrelation at specified lag
partial_autocorr(src, length)
Calculates partial autocorrelation at lag 1
Parameters:
src (float) : Source series
length (simple int) : Lookback period
Returns: PACF at lag 1 (equals ACF at lag 1)
autocorr_test(src, length, max_lag)
Tests for significant autocorrelation (Ljung-Box inspired)
Parameters:
src (float) : Source series
length (simple int) : Lookback period
max_lag (simple int) : Maximum lag to test
Returns: Sum of squared autocorrelations (higher = more autocorrelation)
cross_correlation(x, y, length, lag)
Calculates cross-correlation at specified lag
Parameters:
x (float) : First series
y (float) : Second series (lagged)
length (simple int) : Lookback period
lag (simple int) : Lag to apply to y (positive = y leads x)
Returns: Cross-correlation at specified lag
cross_correlation_peak(x, y, length, max_lag)
Finds lag with maximum cross-correlation
Parameters:
x (float) : First series
y (float) : Second series
length (simple int) : Lookback period
max_lag (simple int) : Maximum lag to search (both directions)
Returns: Tuple:
Probability

Trade Decision MatrixTrade Decision Matrix (TDM)
Trade Decision Matrix (TDM) is a professional-grade, multi-phase market intelligence indicator designed to assist traders in understanding market structure, regime behavior, capital confidence, and execution readiness using a systematic, probabilistic framework.
This indicator does not generate trade signals. Instead, it provides a structured decision matrix similar to institutional trading desks, combining regime analytics, entropy confidence, Bayesian reliability, capital allocation logic, and scenario interpretation.
🔹 Core Architecture
TDM is built using a nine-phase institutional decision pipeline:
Phase 1 — Market Context
Spot–future basis, volatility normalization, and structural slope detection.
Phase 2 — Regime Engine
Probabilistic classification of Trend, Breakout, Range, or Mean Reversion environments.
Phase 3 — Orthogonal Model Cores
Independent statistical, trend, breakout, and mean-reversion cores.
Phase 4 — Bayesian Reliability Engine
Adaptive reliability scoring for each core using Bayesian reinforcement.
Phase 5 — Capital Engine
Capital confidence and capital mode based on opportunity quality, regime clarity, entropy confidence, and risk filters.
Phase 6 — Decision Matrix
Bias, participation level, and trade quality grading.
Phase 7 — Scenario Engine
Contextual scenario interpretation such as Trend Expansion, Breakout Failure, Range Compression, etc.
Phase 8 — Execution Gate
Execution readiness filter based on capital and model alignment.
Phase 9 — Reversal Engine
Probabilistic reversal risk estimation using multi-factor logic.
🔹 Regime Entropy Confidence
TDM uses Shannon entropy to measure regime uncertainty and converts it into a confidence score.
Lower entropy = higher regime confidence.
Higher entropy = unstable or transitional market state.
This prevents over-confidence in noisy conditions.
🔹 Institutional Commentary Engine
A professional commentary layer interprets all internal engines and outputs institutional-style guidance such as:
• Institutional Alignment
• Capital Protection Mode
• Regime Uncertainty
• Momentum Continuation
• Structural Breakout
• Volatility Coiling
• Reversal Risk Elevated
This commentary is designed for situational awareness, not signal generation.
🔹 Dashboard
The dark-theme dashboard provides a compact institutional decision panel:
• Regime
• Entropy Confidence
• Scenario
• Bias
• Strength
• Capital Confidence
• Capital Mode
• Trade Quality
• Execution State
• Commentary
• Reversal Risk
All values are color-coded with heat shading for instant visual interpretation.
🔹 How To Use
TDM is best used as a decision support layer alongside your own trading strategy.
Typical workflow:
Identify regime and entropy confidence.
Observe capital confidence and capital mode.
Check scenario and bias alignment.
Confirm execution readiness.
Monitor reversal risk before entering or holding positions.
This tool is ideal for:
• Intraday traders
• Swing traders
• Options traders
• Index traders
• Systematic discretionary traders
🔹 Important Notes
• This indicator does NOT produce buy/sell signals.
• It is a decision intelligence framework.
• It should not be used as a standalone trading system.
• Always apply personal risk management.
🔹 Disclaimer
This indicator is provided for educational and informational purposes only.It does not constitute financial advice or investment recommendations.Trading involves risk. Users are responsible for their own trading decisions.

Advanced Momentum TrackerThe Advanced Momentum Tracker (AMT) is a technical indicator designed to identify high-probability trend reversals and momentum shifts in real-time. Unlike traditional indicators that rely solely on mathematical formulas, AMT analyzes price action structure and historical patterns to detect when market momentum is shifting from bullish to bearish (and vice versa).
Core Methodology:
The indicator tracks consecutive price movements and maintains a comprehensive database of historical momentum patterns. It identifies trend changes by analyzing:
Sequential candle relationships (opens and closes)
Break of key trailing stop levels formed by recent price action
Historical success rates of similar momentum patterns
Key Features
1. Dynamic Levels:
Automatically plots real-time dynamic trailing stop levels based on current momentum
Color-coded lines: Green for bullish momentum, Red for bearish momentum
These levels act as trigger points for potential trend changes
2. Entry Signal Markers:
Clear BUY (↑) and SELL (↓) arrows when momentum shifts are detected
Arrows positioned above/below candles for maximum visibility ,Signals only appear on confirmed trend changes
3. Momentum Score Display:
Shows statistical probability based on historical pattern analysis
Displays strength percentage of current momentum continuation
Helps traders assess confidence level of the current trend
4. Exit Zone Indicator:
Plots recommended exit levels for active positions
Dynamic color coding: Red for long exits, Green for short exits
Warning system (orange) when price breaches exit zones
5. Position Management Filter:
Optional risk filter to avoid trades with excessive distance from trigger level
Customizable position threshold percentage
Helps maintain consistent risk-reward ratios
6. Comprehensive Alert System:
Customizable alert messages for both long and short signals
Configurable alert frequency (once per bar or once per bar close)
Real-time notifications for all signal types
Customization Options-
Visual Settings:
Toggle visibility of current price level, momentum score, and exit zones
Customizable colors for all elements (bullish/bearish themes)
Adjustable line thickness for dynamic levels
Entry Markers:
Custom colors for long and short entry signals
Adjustable arrow distance from candles
Core Parameters:
Historical Depth: Amount of past data to analyze (default: 20,000 bars)
Sensitivity Level: Controls how strong a move must be to trigger signals (default: 4)
Higher values = fewer but stronger signals
Lower values = more signals with earlier entries
Position Management:
Enable/disable position filter
Set maximum acceptable risk threshold as percentage
How It Works:-
Momentum Detection Engine: The script continuously monitors price action, tracking each bullish and bearish leg. It maintains arrays of opens, closes, and counts to build a comprehensive picture of market structure.
Pattern Recognition: When price breaks key levels (minimum/maximum of recent candles based on sensitivity), the indicator recognizes a potential momentum shift.
Statistical Validation: The script compares the current pattern against its historical database to calculate the probability of momentum continuation.
Signal Generation: When a valid trend change is detected (and passes the position filter if enabled), entry signals are displayed with corresponding exit zones.
Best Use Cases:
Swing trading on any timeframe (works on 1m to 1D charts)
Trend reversal identification
Momentum trading strategies
Works on all markets: Forex, Stocks, Crypto, Indices, Commodities etc
Recommended Settings:
Scalping/Day Trading: Sensitivity 2-3, Historical Depth 10,000-20,000
Swing Trading: Sensitivity 3-4, Historical Depth 20,000-30,000
Position Trading: Sensitivity 4-5, Historical Depth 30,000+
Important Notes:
Signals appear only on confirmed bars (not on real-time candles unless confirmed)
The momentum score becomes more accurate as more historical data is processed
Position filter should be adjusted based on the volatility of the instrument being traded
Best used in conjunction with proper risk management and position sizing
What Makes This Indicator Unique:
Unlike indicators that simply apply mathematical formulas to price data, AMT learns from historical price behavior. It doesn't just tell you what happened—it tells you what's likely to happen next based on thousands of similar situations in the past. The statistical momentum score provides an edge that pure technical indicators cannot offer.
Disclaimer: This indicator is a tool for technical analysis and should not be used as the sole basis for trading decisions. Always use proper risk management and combine with your own analysis. Happy Trading !!

Probability-Based Adaptive Detection🙏🏻 PBAD (Probability-Based Adaptive Detection) : adaptive control tool for outliers || novelty detection, made for worst case data & processes, for the highest time complexity O(n^2) compared with the alternatives (would be explained in a sec). Thresholds are completely data driven and axiomatic, no need in provided hyperparameters, are not learned or optimized. The method accepts multiple weights, e.g. both temporal and volatility weights.
Method briefly explained (I can go deeper if any1 asks explicitly):
Performs weighted KDE on initial input data, finds KDE global maximum (mode), creates new “residuals” dataset by centering initial data around this value;
Performs weighted KDE on residuals, uses sigmoid based probability mass targets with increasing probability coverage to construct a set of non-disjoint High Density Intervals (also called HDR, HPD in Bayesian terms);
Uses these intervals to calculate analogs of centralized & standardized moments;
Uses these ^^ moments to construct a set of control thresholds. The scheme used in PBAD is not only based on a central threshold, or on neighboring ones, it utilizes all previous thresholds, gaining more information.
...
The most important part is to understand whether you really need PBAD. Because even tho it seems to be the best one given highest algocomplexity, irl it would work worse in cases when it’s not required by your data.
Here’s the menu (aka taxonomy omg) of methods you can use that would let you make the right choice:
Moment-Based Adaptive Detection (MBAD) :
Norm: L2
Time complexity: original O(n), successfully reduced to O(1) in online version
Use case: default, general purpose
Based on: method of moments (powers of residuals from mean)
Thresholds architecture: centralized
Quantile-Based Adaptive Detection (QBAD):
Norm: L1
Time complexity: O(nlogn)
Use case: either bad data Or process instability
Based on: quantile moments (dyadic percentiles of residuals from median)
Thresholds architecture: chained/recursive/sequential
Probability-Based Adaptive Detection (PBAD):
Norm: L0
Time complexity: O(n^2)
Use case: both bad data And process instability
Based on: probability moments (target probability masses of residuals from KDE mode)
Thresholds architecture: decentralized (for lack of a better name xd, the idea is that these thresholds gain information from the all other threshold and are Not exclusively based on the central or neighboring thresholds)
...
Examples of true use cases:
^^ an appropriate financial instrument to use PBAD
^^ and another one
...
Additional details about how to use it:
Keep the student5 kernel, it’s the best you can do. I added others mostly for comparisons and if you want to use the tool Not for its primary purpose (on a fine data)
“Calculate for N bars” and “Starting at bar N” options allow to reduce calculation period only on the N number of last bars or next bars from a chosen one. It's vital, because calculations here are heavy
Keep plotting offset at 1 (allows to visually compare current bar with the previous threshold values). This is the way it should be done on price data.
HLC3 is the optimal source input, unless you want to use your own better one point estimate of each datapoint (in the best case done by using PBAD itself on OHLC+ values).
In essence it should be used just like MBAD or QBAD, fade/push extensions and limit, fade/push/skip deviations & basis, or other strategies of your. Again, the only reason for 3 methods to exist is to be chosen for according data characteristics.
Btw:
This is the initial version, I don’t consider it perfected tbh, even tho it works as expected, however this method is very situational anyways.
In this script KDE function is modified to ensure the outcoming probabilities Do sum up to 1. I didn’t do this normalization in Weighted KDE Mode script , but there it’s not required since we just need a KDE global max.
see ya
∞

Session ATR Progression Tracker📊 Session ATR Progression Tracker - SIYL Regression Trading Tool
Track how much of your instrument's 7-day Average True Range (ATR) has been covered during the current trading session. This indicator is specifically designed for regression traders who follow the "Stay In Your Lane" (SIYL) methodology, helping you identify when the probability of mean reversion significantly increases. If you are interested in more on that check out Rod Casselli and tradersdevgroup.com.
🎯 Key Features:
• Real-time ATR Coverage Percentage - See at a glance what percentage of the 7-day ATR has been covered in the current session
• SIYL-Optimized Thresholds - See at a glance when the instrument has achieved 80% and 100% ATR coverage, the proven thresholds where mean reversion probability increases (customizable)
• Flexible Session Modes:
- Daily: Resets at calendar day change
- Session: Uses exchange-defined trading sessions
- Custom Session: Set your exact session start/end times (perfect for futures traders and international markets)
• Visual Alerts - Color-coded display (gray → orange → red) and optional background highlighting
• Repositionable Display - Choose from 9 screen positions to avoid chart clutter
• Session Markers - Green triangles mark the start of each new session
• Detailed Stats - View current range, ATR value, session high/low, and session status
💡 Why Use This Indicator?
This tool is built around a proven concept: regression trading becomes significantly more effective once a session has achieved at least 80% of its 7-day ATR. At this threshold, the probability of price reverting to mean increases substantially, creating higher-probability trade setups for SIYL practitioners.
Benefits for regression traders:
- Identify optimal entry points when mean reversion probability is highest (≥80% ATR coverage)
- Avoid premature regression entries before adequate range has been established
- Recognize when daily moves have "earned their range" and are ripe for reversal
- Time fade-the-move and counter-trend strategies with statistical backing
- Improve win rates by trading only after proven probability thresholds are met
⚙️ Setup Instructions:
1. Add the indicator to your chart
2. Select your preferred "Reset Mode" (recommend "Custom Session" for futures/international markets)
3. If using Custom Session, enter your session times in 24-hour format (e.g., 0930-1600 for US stocks, 1700-1600 for CME futures)
4. Adjust alert thresholds if desired (default: 80% and 100% - proven SIYL thresholds)
5. Position the display where it's most visible on your chart
📈 Works Across All Markets:
Stocks • Futures • Forex • Indices • Crypto • Commodities
Perfect for regression traders, mean reversion specialists, and SIYL practitioners who want to trade with probability on their side by entering only after the session has "earned its range."
---
Tip: For futures contracts with overnight sessions that span calendar days (like MES, MNQ, MYM), use "Custom Session" mode with your exchange's official session times for accurate tracking.

SMC N-Gram Probability Matrix [PhenLabs]📊 SMC N-Gram Probability Matrix
Version: PineScript™ v6
📌 Description
The SMC N-Gram Probability Matrix applies computational linguistics methodology to Smart Money Concepts trading. By treating SMC patterns as a discrete “alphabet” and analyzing their sequential relationships through N-gram modeling, this indicator calculates the statistical probability of which pattern will appear next based on historical transitions.
Traditional SMC analysis is reactive—traders identify patterns after they form and then anticipate the next move. This indicator inverts that approach by building a transition probability matrix from up to 5,000 bars of pattern history, enabling traders to see which SMC formations most frequently follow their current market sequence.
The indicator detects and classifies 11 distinct SMC patterns including Fair Value Gaps, Order Blocks, Liquidity Sweeps, Break of Structure, and Change of Character in both bullish and bearish variants, then tracks how these patterns transition from one to another over time.
🚀 Points of Innovation
First indicator to apply N-gram sequence modeling from computational linguistics to SMC pattern analysis
Dynamic transition matrix rebuilds every 50 bars for adaptive probability calculations
Supports bigram (2), trigram (3), and quadgram (4) sequence lengths for varying analysis depth
Priority-based pattern classification ensures higher-significance patterns (CHoCH, BOS) take precedence
Configurable minimum occurrence threshold filters out statistically insignificant predictions
Real-time probability visualization with graphical confidence bars
🔧 Core Components
Pattern Alphabet System: 11 discrete SMC patterns encoded as integers for efficient matrix indexing and transition tracking
Swing Point Detection: Uses ta.pivothigh/pivotlow with configurable sensitivity for non-repainting structure identification
Transition Count Matrix: Flattened array storing occurrence counts for all possible pattern sequence transitions
Context Encoder: Converts N-gram pattern sequences into unique integer IDs for matrix lookup
Probability Calculator: Transforms raw transition counts into percentage probabilities for each possible next pattern
🔥 Key Features
Multi-Pattern SMC Detection: Simultaneously identifies FVGs, Order Blocks, Liquidity Sweeps, BOS, and CHoCH formations
Adjustable N-Gram Length: Choose between 2-4 pattern sequences to balance specificity against sample size
Flexible Lookback Range: Analyze anywhere from 100 to 5,000 historical bars for matrix construction
Pattern Toggle Controls: Enable or disable individual SMC pattern types to customize analysis focus
Probability Threshold Filtering: Set minimum occurrence requirements to ensure prediction reliability
Alert Integration: Built-in alert conditions trigger when high-probability predictions emerge
🎨 Visualization
Probability Table: Displays current pattern, recent sequence, sample count, and top N predicted patterns with percentage probabilities
Graphical Probability Bars: Visual bar representation (█░) showing relative probability strength at a glance
Chart Pattern Markers: Color-coded labels placed directly on price bars identifying detected SMC formations
Pattern Short Codes: Compact notation (F+, F-, O+, O-, L↑, L↓, B+, B-, C+, C-) for quick pattern identification
Customizable Table Position: Place probability display in any corner of your chart
📖 Usage Guidelines
N-Gram Configuration
N-Gram Length: Default 2, Range 2-4. Lower values provide more samples but less specificity. Higher values capture complex sequences but require more historical data.
Matrix Lookback Bars: Default 500, Range 100-5000. More bars increase statistical significance but may include outdated market behavior.
Min Occurrences for Prediction: Default 2, Range 1-10. Higher values filter noise but may reduce prediction availability.
SMC Detection Settings
Swing Detection Length: Default 5, Range 2-20. Controls pivot sensitivity for structure analysis.
FVG Minimum Size: Default 0.1%, Range 0.01-2.0%. Filters insignificant gaps.
Order Block Lookback: Default 10, Range 3-30. Bars to search for OB formations.
Liquidity Sweep Threshold: Default 0.3%, Range 0.05-1.0%. Minimum wick extension beyond swing points.
Display Settings
Show Probability Table: Toggle the probability matrix display on/off.
Show Top N Probabilities: Default 5, Range 3-10. Number of predicted patterns to display.
Show SMC Markers: Toggle on-chart pattern labels.
✅ Best Use Cases
Anticipating continuation or reversal patterns after liquidity sweeps
Identifying high-probability BOS/CHoCH sequences for trend trading
Filtering FVG and Order Block signals based on historical follow-through rates
Building confluence by comparing predicted patterns with other technical analysis
Studying how SMC patterns typically sequence on specific instruments or timeframes
⚠️ Limitations
Predictions are based solely on historical pattern frequency and do not account for fundamental factors
Low sample counts produce unreliable probabilities—always check the Samples display
Market regime changes can invalidate historical transition patterns
The indicator requires sufficient historical data to build meaningful probability matrices
Pattern detection uses standardized parameters that may not capture all institutional activity
💡 What Makes This Unique
Linguistic Modeling Applied to Markets: Treats SMC patterns like words in a language, analyzing how they “flow” together
Quantified Pattern Relationships: Transforms subjective SMC analysis into objective probability percentages
Adaptive Learning: Matrix rebuilds periodically to incorporate recent pattern behavior
Comprehensive SMC Coverage: Tracks all major Smart Money Concepts in a unified probability framework
🔬 How It Works
1. Pattern Detection Phase
Each bar is analyzed for SMC formations using configurable detection parameters
A priority hierarchy assigns the most significant pattern when multiple detections occur
2. Sequence Encoding Phase
Detected patterns are stored in a rolling history buffer of recent classifications
The current N-gram context is encoded into a unique integer identifier
3. Matrix Construction Phase
Historical pattern sequences are iterated to count transition occurrences
Each context-to-next-pattern transition increments the appropriate matrix cell
4. Probability Calculation Phase
Current context ID retrieves corresponding transition counts from the matrix
Raw counts are converted to percentages based on total context occurrences
5. Visualization Phase
Probabilities are sorted and the top N predictions are displayed in the table
Chart markers identify the current detected pattern for visual reference
💡 Note:
This indicator performs best when used as a confluence tool alongside traditional SMC analysis. The probability predictions highlight statistically common pattern sequences but should not be used as standalone trading signals. Always verify predictions against price action context, higher timeframe structure, and your overall trading plan. Monitor the sample count to ensure predictions are based on adequate historical data.

Per Bak Self-Organized CriticalityTL;DR: This indicator measures market fragility. It measures the system's vulnerability to cascade failures and phase transitions. I've added four independent stress vectors: tail risk, volatility regime, credit stress, and positioning extremes. This allows us to quantify how susceptible markets are to disproportionate moves from small shocks, similar to how a steep sandpile is primed for avalanches.
Avalanches, forest fires, earthquakes, pandemic outbreaks, and market crashes. What do they all have in common? They are not random.
These events follow power laws - stable systems that naturally evolve toward critical states where small triggers can unleash catastrophic cascades.
For example, if you are building a sandpile, there will be a point with a little bit additional sand will cause a landslide.
Markets build fragility grain by grain, like a sandpile approaching avalanche.
The Per Bak Self-Organized Criticality (SOC) indicator detects when the markets are a few grains away from collapse.
This indicator is highly inspired by the work of Per Bak related to the science of self-organized criticality .
As Bak said:
"The earthquake does not 'know how large it will become'. Thus, any precursor state of a large event is essentially identical to a precursor state of a small event."
For markets, this means:
We cannot predict individual crash size from initial conditions
We can predict statistical distribution of crashes
We can identify periods of increased systemic risk (proximity to critical state)
BTW, this is a forwarding looking indicator and doesn't reprint. :)
The Story of Per Bak
In 1987, Danish physicist Per Bak and his colleagues discovered an important pattern in nature: self-organized criticality.
Their sandpile experiment revealed something: drop grains of sand one by one onto a pile, and the system naturally evolves toward a critical state. Most grains cause nothing. Some trigger small slides. But occasionally a single grain triggers a massive avalanche.
The key insight is that we cannot predict which grain will trigger the avalanche, but you can measure when the pile has reached a critical state.
Why Markets Are the Ultimate SOC System?
Financial markets exhibit all the hallmarks of self-organized criticality:
Interconnected agents (traders, institutions, algorithms) with feedback loops
Non-linear interactions where small events can cascade through the system
Power-law distributions of returns (fat tails, not normal distributions)
Natural evolution toward fragility as leverage builds, correlations tighten, and positioning crowds
Phase transitions where calm markets suddenly shift to crisis regimes
Mathematical Foundation
Power Law Distributions
Traditional finance assumes returns follow a normal distribution. "Markets return 10% on average." But I disagree. Markets follow power laws:
P(x) ∝ x^(-α)
Where P(x) is the probability of an event of size x, and α is the power law exponent (typically 3-4 for financial markets).
What this means: Small moves happen constantly. Medium moves are less frequent. Catastrophic moves are rare but follow predictable probability distributions. The "fat tails" are features of critical systems.
Critical Slowing Down
As systems approach phase transitions, they exhibit critical slowing down—reduced ability to absorb shocks. Mathematically, this appears as:
τ ∝ |T - T_c|^(-ν)
Where τ is the relaxation time, T is the current state, T_c is the critical threshold, and ν is the critical exponent.
Translation: Near criticality, markets take longer to recover from perturbations. Fragility compounds.
Component Aggregation & Non-Linear Emergence
The Per Bak SOC our index aggregates four normalized components (each scaled 0-100) with tunable weights:
SOC = w₁·C_tail + w₂·C_vol + w₃·C_credit + w₄·C_position
Default weights (you can change this):
w₁ = 0.34 (Tail Risk via SKEW)
w₂ = 0.26 (Volatility Regime via VIX term structure)
w₃ = 0.18 (Credit Stress via HYG/LQD + TED spread)
w₄ = 0.22 (Positioning Extremes via Put/Call ratio)
Each component uses percentile ranking over a 252-day lookback combined with absolute thresholds to capture both relative regime shifts and extreme absolute levels.
The Four Pillars Explained
1. Tail Risk (SKEW Index)
Measures options market pricing of fat-tail events. High SKEW indicates elevated outlier probability.
C_tail = 0.7·percentrank(SKEW, 252) + 0.3·((SKEW - 115)/0.5)
2. Volatility Regime (VIX Term Structure)
Combines VIX level with term structure slope. Backwardation signals acute stress.
C_vol = 0.4·VIX_level + 0.35·VIX_slope + 0.25·VIX_ratio
3. Credit Stress (HYG/LQD + TED Spread)
Tracks high-yield deterioration versus investment-grade and interbank lending stress.
C_credit = 0.65·percentrank(LQD/HYG, 252) + 0.35·(TED/0.75)·100
4. Positioning Extremes (Put/Call Ratio)
Detects extreme hedging demand through percentile ranking and z-score analysis.
C_position = 0.6·percentrank(P/C, 252) + 0.4·zscore_normalized
What the Indicator Really Measures?
Not Volatility but Fragility
Markets Going Down ≠ Fragility Building (actually when markets go down, risk and fragility are released)
The 0-100 Scale & Regime Thresholds
The indicator outputs a 0-100 fragility score with four regimes:
🟢 Safe (0-39): System resilient, can absorb normal shocks
🟡 Building (40-54): Early fragility signs, watch for deterioration
🟠 Elevated (55-69): System vulnerable
🔴 Critical (70-100): Highly susceptible to cascade failures
Further Reading for Nerds
Bak, P., Tang, C., & Wiesenfeld, K. (1987). "Self-organized criticality: An explanation of 1/f noise." Physical Review Letters.
Bak, P. & Chen, K. (1991). "Self-organized criticality." Scientific American.
Bak, P. (1996). How Nature Works: The Science of Self-Organized Criticality. Copernicus.
Feedback is appreciated :)

Weighted KDE Mode🙏🏻 The ‘ultimate’ typical value estimator, for the highest computational cost @ time complexity O(n^2). I am not afraid to say: this is the last resort BFG9000 you can ‘ever’ get to make dem market demons kneel before y’all
Quickguide
pls read it, you won’t find it anywhere else in open access
When to use:
If current market activity is so crazy || things on your charts are really so bad (contaminated data && (data has very heavy tails || very pronounced peak)), the only option left is to use the peak (mode) of Kernel Density Estimate , instead of median not even mentioning mean. So when WMA won’t help, when WPNR won’t help, you need this thing.
Setting it up:
Interval: choose what u need, you can use usual moving windows, but I also added yearly and session anchors alike in old VWAP (always prefer 24h instead of Session if your plan allows). Other options like cumulative window are also there.
Parameters: this script ain't no joke, it needs time to make calculations, so I added a setting to calculate only for the last N bars (when “starting at bar N” is put on 0). If it’s not zero it acts as a starting point after which the calculations happen (useful for backtesting). Other parameters keep em as they are, keep student5 kernel , turn off appropriate weights if u apply it to other than chart data, on other studies etc.
But instead of listening to me just experiment with parameters and see what they change, would take 5 mins max
Been always saying that VWAP is ish, not time-aware etc, volume info is incorporated in a lil bit wrong way… So I decided not just to fix VWAP (you can do it yourself in 5 mins), but instead to drop there the Ultimate xD typical value estimator that is ever possible to do. Time aware, volume / inferred volume aware, resistant to all kinds of BS. This is your shieldwall.
How it works:
You can easily do a weighted kernel density estimation, in our case including temporal and intensity information while accumulating densities. Here are some details worth mentioning about the thing:
Kernels are raw (not unit variance), that’s easier to work with later.
h_constants for each kernel were calculated ^^ given that ^^ with python mpmath module with high decimal precision.
In bandwidth calculation instead of using empirical standard deviation as a scaler, I use... ta.range(src, len) / math.sqrt(12)
...that takes data range and converts it to standard deviation, assuming data is uniformly distributed. That’s exactly what we need: a scaler that is coherent with the KDE, that has nothing to do with stdevs, as the kernels except for gaussian ones (that we don’t even need to use). More importantly, if u take multiple windows and see over time which distro they approach on the long term, that would be the uniform one (not the normal one as many think). Sometimes windows are multimodal, sometimes Laplace like etc, so in general all together they are uniform ish.
The one and only kernel you really need is Student t with v = 5 , for the use case I highlighted in the first part of the post for TV users. It’s as far as u can get until ish becomes crazy like undefined variance etc. It has the highest kurtosis = 9 of all distros, perfect for the real use case I mentioned. Otherwise, you don’t even need KDE 4 real, but still I included other senseful kernels for comparison or in case I am trippin there.
Btw, don’t believe in all that hype about Epanechnikov kernel which in essence is made from beta distribution with alpha = beta = 2, idk why folk call it with that weird name, it’s beta2 kernel. Yes on papers it really minimises AMISE (that’s how I calculated h constants for all dem kernels in the script), but for really crazy data (proper use case for us), it ain't provides even ‘closely’ compared with student5 kernel. Not much else to add.
Shout out to @RicardoSantos for inspiration, I saw your KDE script a long time ago brotha, finna got my hands on it.
∞

NBarForwardOdds# N Bar Forward Odds
## Description
Calculates the probability of a closing price exceeding a closing price at a specified interval away from the
current bar. It does this by iterating through a series of intervals (1 to 20) and determining if the closing
price of the current bar is greater than the closing price of the bar at that interval.
## Usage:
Selectable base interval from the input configuration panel is calculated with a value step in a range `1:20` to get the final interval displayed.

First Passage Time - Distribution AnalysisThe First Passage Time (FPT) Distribution Analysis indicator is a sophisticated probabilistic tool that answers one of the most critical questions in trading: "How long will it take for price to reach my target, and what are the odds of getting there first?"
Unlike traditional technical indicators that focus on what might happen, this indicator tells you when it's likely to happen.
Mathematical Foundation: First Passage Time Theory
What is First Passage Time?
First Passage Time (FPT) is a concept in stochastic processes that measures the time it takes for a random process to reach a specific threshold for the first time. Originally developed in physics and mathematics, FPT has applications in:
Quantitative Finance: Option pricing, risk management, and algorithmic trading
Neuroscience: Modeling neural firing patterns
Biology: Population dynamics and disease spread
Engineering: Reliability analysis and failure prediction
The Mathematics Behind It
This indicator uses Geometric Brownian Motion (GBM), the same stochastic model used in the Black-Scholes option pricing formula:
dS = μS dt + σS dW
Where:
S = Asset price
μ = Drift (trend component)
σ = Volatility (uncertainty component)
dW = Wiener process (random walk)
Through Monte Carlo simulation, the indicator runs 1,000+ price path simulations to statistically determine:
When each threshold (+X% or -X%) is likely to be hit
Which threshold is hit first (directional bias)
How often each scenario occurs (probability distribution)
🎯 How This Indicator Works
Core Algorithm Workflow:
Calculate Historical Statistics
Measures recent price volatility (standard deviation of log returns)
Calculates drift (average directional movement)
Annualizes these metrics for meaningful comparison
Run Monte Carlo Simulations
Generates 1,000+ random price paths based on historical behavior
Tracks when each path hits the upside (+X%) or downside (-X%) threshold
Records which threshold was hit first in each simulation
Aggregate Statistical Results
Calculates percentile distributions (10th, 25th, 50th, 75th, 90th)
Computes "first hit" probabilities (upside vs downside)
Determines average and median time-to-target
Visual Representation
Displays thresholds as horizontal lines
Shows gradient risk zones (purple-to-blue)
Provides comprehensive statistics table
📈 Use Cases
1. Options Trading
Selling Options: Determine if your strike price is likely to be hit before expiration
Buying Options: Estimate probability of reaching profit targets within your time window
Time Decay Management: Compare expected time-to-target vs theta decay
Example: You're considering selling a 30-day call option 5% out of the money. The indicator shows there's a 72% chance price hits +5% within 12 days. This tells you the trade has high assignment risk.
2. Swing Trading
Entry Timing: Wait for higher probability setups when directional bias is strong
Target Setting: Use median time-to-target to set realistic profit expectations
Stop Loss Placement: Understand probability of hitting your stop before target
Example: The indicator shows 85% upside probability with median time of 3.2 days. You can confidently enter long positions with appropriate position sizing.
3. Risk Management
Position Sizing: Larger positions when probability heavily favors one direction
Portfolio Allocation: Reduce exposure when probabilities are near 50/50 (high uncertainty)
Hedge Timing: Know when to add protective positions based on downside probability
Example: Indicator shows 55% upside vs 45% downside—nearly neutral. This signals high uncertainty, suggesting reduced position size or wait for better setup.
4. Market Regime Detection
Trending Markets: High directional bias (70%+ one direction)
Range-bound Markets: Balanced probabilities (45-55% both directions)
Volatility Regimes: Compare actual vs theoretical minimum time
Example: Consistent 90%+ bullish bias across multiple timeframes confirms strong uptrend—stay long and avoid counter-trend trades.
First Hit Rate (Most Important!)
Shows which threshold is likely to be hit FIRST:
Upside %: Probability of hitting upside target before downside
Downside %: Probability of hitting downside target before upside
These always sum to 100%
⚠️ Warning: If you see "Low Hit Rate" warning, increase this parameter!
Advanced Parameters
Drift Mode
Allows you to explore different scenarios:
Historical: Uses actual recent trend (default—most realistic)
Zero (Neutral): Assumes no trend, only volatility (symmetric probabilities)
50% Reduced: Dampens trend effect (conservative scenario)
Use Case: Switch to "Zero (Neutral)" to see what happens in a pure volatility environment, useful for range-bound markets.
Distribution Type
Percentile: Shows 10%, 25%, 50%, 75%, 90% levels (recommended for most users)
Sigma: Shows standard deviation levels (1σ, 2σ)—useful for statistical analysis
⚠️ Important Limitations & Best Practices
Limitations
Assumes GBM: Real markets have fat tails, jumps, and regime changes not captured by GBM
Historical Parameters: Uses recent volatility/drift—may not predict regime shifts
No Fundamental Events: Cannot predict earnings, news, or macro shocks
Computational: Runs only on last bar—doesn't give historical signals
Remember: Probabilities are not certainties. Use this indicator as part of a comprehensive trading plan with proper risk management.
Created by: Henrique Centieiro. feedback is more than welcome!

Hummingbird Probability Mapping IndicatorHummingbird Probability Mapping Indicator - A nature inspired indicator that utilizes combinations of the following trend patterns and projects a probability mapping with greater than 70% accuracy based on real-time analysis.
EMA Trend
MACD
RSI
VWAP Spread
Burst
Squeeze
Volatility (ATRp)
Qi Dass

Institutional Levels (CNN) - [PhenLabs]📊Institutional Levels (Convolutional Neural Network-inspired)
Version : PineScript™v6
📌Description
The CNN-IL Institutional Levels indicator represents a breakthrough in automated zone detection technology, combining convolutional neural network principles with advanced statistical modeling. This sophisticated tool identifies high-probability institutional trading zones by analyzing pivot patterns, volume dynamics, and price behavior using machine learning algorithms.
The indicator employs a proprietary 9-factor logistic regression model that calculates real-time reaction probabilities for each detected zone. By incorporating CNN-inspired filtering techniques and dynamic zone management, it provides traders with unprecedented accuracy in identifying where institutional money is likely to react to price action.
🚀Points of Innovation
● CNN-Inspired Pivot Analysis - Advanced binning system using convolutional neural network principles for superior pattern recognition
● Real-Time Probability Engine - Live reaction probability calculations using 9-factor logistic regression model
● Dynamic Zone Intelligence - Automatic zone merging using Intersection over Union (IoU) algorithms
● Volume-Weighted Scoring - Time-of-day volume Z-score analysis for enhanced zone strength assessment
● Adaptive Decay System - Intelligent zone lifecycle management based on touch frequency and recency
● Multi-Filter Architecture - Optional gradient, smoothing, and Difference of Gaussians (DoG) convolution filters
🔧Core Components
● Pivot Detection Engine - Advanced pivot identification with configurable left/right bars and ATR-normalized strength calculations
● Neural Network Binning - Price level clustering using CNN-inspired algorithms with ATR-based bin sizing
● Logistic Regression Model - 9-factor probability calculation including distance, width, volume, VWAP deviation, and trend analysis
● Zone Management System - Intelligent creation, merging, and decay algorithms for optimal zone lifecycle control
● Visualization Layer - Dynamic line drawing with opacity-based scoring and optional zone fills
🔥Key Features
● High-Probability Zone Detection - Automatically identifies institutional levels with reaction probabilities above configurable thresholds
● Real-Time Probability Scoring - Live calculation of zone reaction likelihood using advanced statistical modeling
● Session-Aware Analysis - Optional filtering to specific trading sessions for enhanced accuracy during active market hours
● Customizable Parameters - Full control over lookback periods, zone sensitivity, merge thresholds, and probability models
● Performance Optimized - Efficient processing with controlled update frequencies and pivot processing limits
● Non-Repainting Mode - Strict mode available for backtesting accuracy and live trading reliability
🎨Visualization
● Dynamic Zone Lines - Color-coded support and resistance levels with opacity reflecting zone strength and confidence scores
● Probability Labels - Real-time display of reaction probabilities, touch counts, and historical hit rates for active zones
● Zone Fills - Optional semi-transparent zone highlighting for enhanced visual clarity and immediate pattern recognition
● Adaptive Styling - Automatic color and opacity adjustments based on zone scoring and statistical significance
📖Usage Guidelines
● Lookback Bars - Default 500, Range 100-1000, Controls the historical data window for pivot analysis and zone calculation
● Pivot Left/Right - Default 3, Range 1-10, Defines the pivot detection sensitivity and confirmation requirements
● Bin Size ATR units - Default 0.25, Range 0.1-2.0, Controls price level clustering granularity for zone creation
● Base Zone Half-Width ATR units - Default 0.25, Range 0.1-1.0, Sets the minimum zone width in ATR units for institutional level boundaries
● Zone Merge IoU Threshold - Default 0.5, Range 0.1-0.9, Intersection over Union threshold for automatic zone merging algorithms
● Max Active Zones - Default 5, Range 3-20, Maximum number of zones displayed simultaneously to prevent chart clutter
● Probability Threshold for Labels - Default 0.6, Range 0.3-0.9, Minimum reaction probability required for zone label display and alerts
● Distance Weight w1 - Controls influence of price distance from zone center on reaction probability
● Width Weight w2 - Adjusts impact of zone width on probability calculations
● Volume Weight w3 - Modifies volume Z-score influence on zone strength assessment
● VWAP Weight w4 - Controls VWAP deviation impact on institutional level significance
● Touch Count Weight w5 - Adjusts influence of historical zone interactions on probability scoring
● Hit Rate Weight w6 - Controls prior success rate impact on future reaction likelihood predictions
● Wick Penetration Weight w7 - Modifies wick penetration analysis influence on probability calculations
● Trend Weight w8 - Adjusts trend context impact using ADX analysis for directional bias assessment
✅Best Use Cases
● Swing Trading Entries - Enter positions at high-probability institutional zones with 60%+ reaction scores
● Scalping Opportunities - Quick entries and exits around frequently tested institutional levels
● Risk Management - Use zones as dynamic stop-loss and take-profit levels based on institutional behavior
● Market Structure Analysis - Identify key institutional levels that define current market structure and sentiment
● Confluence Trading - Combine with other technical indicators for high-probability trade setups
● Session-Based Strategies - Focus analysis during high-volume sessions for maximum effectiveness
⚠️Limitations
● Historical Pattern Dependency - Algorithm effectiveness relies on historical patterns that may not repeat in changing market conditions
● Computational Intensity - Complex calculations may impact chart performance on lower-end devices or with multiple indicators
● Probability Estimates - Reaction probabilities are statistical estimates and do not guarantee actual market outcomes
● Session Sensitivity - Performance may vary significantly between different market sessions and volatility regimes
● Parameter Sensitivity - Results can be highly dependent on input parameters requiring optimization for different instruments
💡What Makes This Unique
● CNN Architecture - First indicator to apply convolutional neural network principles to institutional-level detection
● Real-Time ML Scoring - Live machine learning probability calculations for each zone interaction
● Advanced Zone Management - Sophisticated algorithms for zone lifecycle management and automatic optimization
● Statistical Rigor - Comprehensive 9-factor logistic regression model with extensive backtesting validation
● Performance Optimization - Efficient processing algorithms designed for real-time trading applications
🔬How It Works
● Multi-timeframe pivot identification - Uses configurable sensitivity parameters for advanced pivot detection
● ATR-normalized strength calculations - Standardizes pivot significance across different volatility regimes
● Volume Z-score integration - Enhanced pivot weighting based on time-of-day volume patterns
● Price level clustering - Neural network binning algorithms with ATR-based sizing for zone creation
● Recency decay applications - Weights recent pivots more heavily than historical data for relevance
● Statistical filtering - Eliminates low-significance price levels and reduces market noise
● Dynamic zone generation - Creates zones from statistically significant pivot clusters with minimum support thresholds
● IoU-based merging algorithms - Combines overlapping zones while maintaining accuracy using Intersection over Union
● Adaptive decay systems - Automatic removal of outdated or low-performing zones for optimal performance
● 9-factor logistic regression - Incorporates distance, width, volume, VWAP, touch history, and trend analysis
● Real-time scoring updates - Zone interaction calculations with configurable threshold filtering
● Optional CNN filters - Gradient detection, smoothing, and Difference of Gaussians processing for enhanced accuracy
💡Note
This indicator represents advanced quantitative analysis and should be used by traders familiar with statistical modeling concepts. The probability scores are mathematical estimates based on historical patterns and should be combined with proper risk management and additional technical analysis for optimal trading decisions.
Mean Reversion Probability Zones [BigBeluga]🔵 OVERVIEW
The Mean Reversion Probability Zones indicator measures the likelihood of price reverting back toward its mean . By analyzing oscillator dynamics (RSI, MFI, or Stochastic), it calculates probability zones both above and below the oscillator. These zones are visualized as histograms, colored regions on the main chart, and a compact dashboard, helping traders spot when the market is statistically stretched and more likely to revert.
🔵 CONCEPTS
Mean Reversion : The tendency of price to return to its average after significant extensions.
Oscillator-Based Analysis : Uses RSI, MFI, or Stochastic as the base signal for detecting overextension.
Probability Model : The probability of reversion is computed using three factors:
Whether the oscillator is rising or declining.
Whether the oscillator is above or below user-defined thresholds.
The oscillator’s actual value (distance from equilibrium).
Dual-Zone Output :
Upper histogram = probability of downward mean reversion.
Lower histogram = probability of upward mean reversion.
Historical Extremes : The dashboard highlights the recent maximum probability values for both upward and downward scenarios.
🔵 FEATURES
Oscillator Choice : Switch between RSI, MFI, and Stochastic.
Customizable Zones : User-defined upper/lower thresholds with independent colors.
Probability Histograms :
Above oscillator → down reversion probability.
Below oscillator → up reversion probability.
Colored Gradient Zones on Chart : Visual overlays showing where mean reversion probabilities are strongest.
Probability Labels : Percentages displayed next to histogram values for clarity.
Dashboard : Compact table in the corner showing the recent maximum probabilities for both upward and downward mean reversion.
Overlay Compatibility : Works in both chart pane and sub-pane with oscillators.
🔵 HOW TO USE
Set Oscillator : Choose RSI, MFI, or Stochastic depending on your strategy style.
Adjust Zones : Define upper/lower bounds for when oscillator values indicate strong overbought/oversold conditions.
Interpret Histograms :
Orange (upper) histogram → higher chance of a pullback/downward mean reversion.
Green (lower) histogram → higher chance of upward reversion/bounce.
Watch Gradient Zones : On the main chart, shaded areas highlight where probability of mean reversion is elevated.
Consult Dashboard : Use the “Recent MAX” values to understand how strong recent reversion probabilities have been in either direction.
Confluence Strategy : Combine with support/resistance, order flow, or trend filters to avoid counter-trend trades.
🔵 CONCLUSION
The Mean Reversion Probability Zones provides traders with an advanced way to quantify and visualize mean reversion opportunities. By blending oscillator momentum, threshold logic, and probability calculations, it highlights when markets are statistically stretched and primed for reversal. Whether you are a contrarian trader or simply looking for exhaustion signals to fade, this tool helps bring structure and clarity to mean reversion setups.

BUY & SELL Probability (M5..D1) - MTFMTF Probability Indicator (M5 to D1)
Indicator — Dual Histogram with Buy/Sell Labels
This indicator is designed to provide a probabilistic bias for bullish or bearish conditions by combining three different analytical components across multiple timeframes. The goal is to reduce noise from single-indicator signals and instead highlight confluence where trend, momentum, and strength agree.
Why this combination is useful
- EMA(200) Trend Filter: Identifies whether price is trading above or below a widely used long-term moving average.
- MACD Momentum: Detects short-term directional momentum through line crossovers.
- ADX Strength: Measures how strong the trend is, preventing signals in weak or flat markets.
By combining these, the indicator avoids situations where one tool signals a trade but others do not, helping to filter out low-probability setups.
How it works
- Each timeframe (M5, M15, H1, H4, D1) generates its own trend, momentum, and strength score.
- Scores are weighted according to user-defined importance and then aggregated into a single probability.
- Proximity to recent support and resistance levels can adjust the final score, accounting for nearby barriers.
- The final probability is displayed as:
- Histogram (subwindow): Green bars for bullish probability >50%, red bars for bearish <50%.
- On-chart labels: Showing exact buy/sell percentages on the last bar for quick reference.
Inputs
- EMA length (default 200), MACD settings, ADX period.
- Weights for each timeframe and component (trend, momentum, strength).
- Optional boost for the chart’s current timeframe.
- Smoothing length for probability values.
- Lookback period for support/resistance adjustment.
How to use it
- A green histogram above zero indicates bullish probability >50%.
- A red histogram below zero indicates bearish probability >50%.
- Neutral readings near 50% show low confluence and may be best avoided.
- Users can adjust weights to emphasize higher or lower timeframes, depending on their trading style.
Notes
- This script does not guarantee profitable trades.
- Best used together with price action, volume, or additional confirmation tools.
- Signals are calculated only on closed bars to avoid repainting.
- For testing and learning purposes — not financial advice.
Stop Loss vs Take Profit Probability and EVThis stop loss and take profit calculator uses a Monte Carlo simulation to calculate the probability of hitting your Stop Loss or Take Profit levels across different time horizons (expressed in bars).
It provides data-driven insights to optimize your risk management and position sizing by showing Expected Value for each scenario.
As a quant, I love using statistical data to help my decisions and get better EV from my trades.
🔬 How It's Calculated
Monte Carlo Simulation: Runs 1,000-10,000 price simulations using a random walk model
Volatility Analysis: Combines ATR-based and Historical Volatility for accurate price movement modeling
Expected Value: Calculates profit/loss expectation using formula: (TP_Probability × Reward) - (SL_Probability × Risk)
Time Horizons: Tests multiple timeframes (1, 5, 10, 20, 50 bars) to find optimal holding periods
Risk/Reward Ratios: Automatically calculates and displays R:R ratios for quick assessment
💡 Use Cases
Position Sizing - Determine optimal risk per trade based on Expected Value
Time Horizon Optimization - Find the best holding period for your strategy
Stop Loss Placement - Validate SL levels using probability analysis
Take Profit Optimization - Set TP levels with statistical backing
Strategy Backtesting - Compare different R:R setups before entering trades
Risk Management - Avoid trades with negative Expected Value
Swing vs Day Trading - Choose timeframes with highest success probability
🎯 How to Use
Setup Trade: Enter your entry price, stop loss, and take profit levels
You can add or remove time horizons denominated in bars. Say you are looking at 1h candles, adding a 24-bar time horizon means you are looking into 24 hours
Choose Direction: Select Long or Short position
Review Table
Analyze Expected Value: Focus on positive EV scenarios (green background)
Optimize Timing: Select time horizons with best risk/reward profile
Adjust Parameters: Modify volatility calculation method and simulation count if needed
Examples
Here's how you can read the tables.
Example 1:
In this chart, we are analyzing the TP and SL probabilities as well as the EV (expected value) for a stock. I want to check what the likelihood is that my SL and TP get triggered over the next 5 days. The stock market is open for 6.5 hours per day, which is 13 bars in this 30-minute bar chart. 26 bars is 2 days, 39 bars is 3 days and so on.
Although this trade is more likely to trigger my SL than my TP, in some of the time horizons we have a positive expected value because of the risk/reward of our trade (i.e. distance of the SL and TP from the price) and the probability of hitting SL and TP.
Example 2:
In this example, we have applied the indicator to gold. Because the TP is much closer to the price, the probability of hitting the TP is much higher.
We can also observe that the expected Value in the shorter time frames is better than in the longer ones. This can give us some clues to set up our trade. If we know that the EV is positive, we can allocate more to that specific trade.
Enjoy, and please let me know your feedback! 😊🥂

Advanced Range Analyzer ProAdvanced Range Analyzer Pro – Adaptive Range Detection & Breakout Forecasting
Overview
Advanced Range Analyzer Pro is a comprehensive trading tool designed to help traders identify consolidations, evaluate their strength, and forecast potential breakout direction. By combining volatility-adjusted thresholds, volume distribution analysis, and historical breakout behavior, the indicator builds an adaptive framework for navigating sideways price action. Instead of treating ranges as noise, this system transforms them into opportunities for mean reversion or breakout trading.
How It Works
The indicator continuously scans price action to identify active range environments. Ranges are defined by volatility compression, repeated boundary interactions, and clustering of volume near equilibrium. Once detected, the indicator assigns a strength score (0–100), which quantifies how well-defined and compressed the consolidation is.
Breakout probabilities are then calculated by factoring in:
Relative time spent near the upper vs. lower range boundaries
Historical breakout tendencies for similar structures
Volume distribution inside the range
Momentum alignment using auxiliary filters (RSI/MACD)
This creates a live probability forecast that updates as price evolves. The tool also supports range memory, allowing traders to analyze the last completed range after a breakout has occurred. A dynamic strength meter is displayed directly above each consolidation range, providing real-time insight into range compression and breakout potential.
Signals and Breakouts
Advanced Range Analyzer Pro includes a structured set of visual tools to highlight actionable conditions:
Range Zones – Gradient-filled boxes highlight active consolidations.
Strength Meter – A live score displayed in the dashboard quantifies compression.
Breakout Labels – Probability percentages show bias toward bullish or bearish continuation.
Breakout Highlights – When a breakout occurs, the range is marked with directional confirmation.
Dashboard Table – Displays current status, strength, live/last range mode, and probabilities.
These elements update in real time, ensuring that traders always see the current state of consolidation and breakout risk.
Interpretation
Range Strength : High scores (70–100) indicate strong consolidations likely to resolve explosively, while low scores suggest weak or choppy ranges prone to false signals.
Breakout Probability : Directional bias greater than 60% suggests meaningful breakout pressure. Equal probabilities indicate balanced compression, favoring mean-reversion strategies.
Market Context : Ranges aligned with higher timeframe trends often resolve in the dominant direction, while counter-trend ranges may lead to reversals or liquidity sweeps.
Volatility Insight : Tight ranges with low ATR imply imminent expansion; wide ranges signal extended consolidation or distribution phases.
Strategy Integration
Advanced Range Analyzer Pro can be applied across multiple trading styles:
Breakout Trading : Enter on probability shifts above 60% with confirmation of volume or momentum.
Mean Reversion : Trade inside ranges with high strength scores by fading boundaries and targeting equilibrium.
Trend Continuation : Focus on ranges that form mid-trend, anticipating continuation after consolidation.
Liquidity Sweeps : Use failed breakouts at boundaries to capture reversals.
Multi-Timeframe : Apply on higher timeframes to frame market context, then execute on lower timeframes.
Advanced Techniques
Combine with volume profiles to identify areas of institutional positioning within ranges.
Track sequences of strong consolidations for trend development or exhaustion signals.
Use breakout probability shifts in conjunction with order flow or momentum indicators to refine entries.
Monitor expanding/contracting range widths to anticipate volatility cycles.
Custom parameters allow fine-tuning sensitivity for different assets (crypto, forex, equities) and trading styles (scalping, intraday, swing).
Inputs and Customization
Range Detection Sensitivity : Controls how strictly ranges are defined.
Strength Score Settings : Adjust weighting of compression, volume, and breakout memory.
Probability Forecasting : Enable/disable directional bias and thresholds.
Gradient & Fill Options : Customize range visualization colors and opacity.
Dashboard Display : Toggle live vs last range, info table size, and position.
Breakout Highlighting : Choose border/zone emphasis on breakout events.
Why Use Advanced Range Analyzer Pro
This indicator provides a data-driven approach to trading consolidation phases, one of the most common yet underutilized market states. By quantifying range strength, mapping probability forecasts, and visually presenting risk zones, it transforms uncertainty into clarity.
Whether you’re trading breakouts, fading ranges, or mapping higher timeframe context, Advanced Range Analyzer Pro delivers a structured, adaptive framework that integrates seamlessly into multiple strategies.

Seasonality Monte Carlo Forecaster [BackQuant]Seasonality Monte Carlo Forecaster
Plain-English overview
This tool projects a cone of plausible future prices by combining two ideas that traders already use intuitively: seasonality and uncertainty. It watches how your market typically behaves around this calendar date, turns that seasonal tendency into a small daily “drift,” then runs many randomized price paths forward to estimate where price could land tomorrow, next week, or a month from now. The result is a probability cone with a clear expected path, plus optional overlays that show how past years tended to move from this point on the calendar. It is a planning tool, not a crystal ball: the goal is to quantify ranges and odds so you can size, place stops, set targets, and time entries with more realism.
What Monte Carlo is and why quants rely on it
• Definition . Monte Carlo simulation is a way to answer “what might happen next?” when there is randomness in the system. Instead of producing a single forecast, it generates thousands of alternate futures by repeatedly sampling random shocks and adding them to a model of how prices evolve.
• Why it is used . Markets are noisy. A single point forecast hides risk. Monte Carlo gives a distribution of outcomes so you can reason in probabilities: the median path, the 68% band, the 95% band, tail risks, and the chance of hitting a specific level within a horizon.
• Core strengths in quant finance .
– Path-dependent questions : “What is the probability we touch a stop before a target?” “What is the expected drawdown on the way to my objective?”
– Pricing and risk : Useful for path-dependent options, Value-at-Risk (VaR), expected shortfall (CVaR), stress paths, and scenario analysis when closed-form formulas are unrealistic.
– Planning under uncertainty : Portfolio construction and rebalancing rules can be tested against a cloud of plausible futures rather than a single guess.
• Why it fits trading workflows . It turns gut feel like “seasonality is supportive here” into quantitative ranges: “median path suggests +X% with a 68% band of ±Y%; stop at Z has only ~16% odds of being tagged in N days.”
How this indicator builds its probability cone
1) Seasonal pattern discovery
The script builds two day-of-year maps as new data arrives:
• A return map where each calendar day stores an exponentially smoothed average of that day’s log return (yesterday→today). The smoothing (90% old, 10% new) behaves like an EWMA, letting older seasons matter while adapting to new information.
• A volatility map that tracks the typical absolute return for the same calendar day.
It calculates the day-of-year carefully (with leap-year adjustment) and indexes into a 365-slot seasonal array so “March 18” is compared with past March 18ths. This becomes the seasonal bias that gently nudges simulations up or down on each forecast day.
2) Choice of randomness engine
You can pick how the future shocks are generated:
• Daily mode uses a Gaussian draw with the seasonal bias as the mean and a volatility that comes from realized returns, scaled down to avoid over-fitting. It relies on the Box–Muller transform internally to turn two uniform random numbers into one normal shock.
• Weekly mode uses bootstrap sampling from the seasonal return history (resampling actual historical daily drifts and then blending in a fraction of the seasonal bias). Bootstrapping is robust when the empirical distribution has asymmetry or fatter tails than a normal distribution.
Both modes seed their random draws deterministically per path and day, which makes plots reproducible bar-to-bar and avoids flickering bands.
3) Volatility scaling to current conditions
Markets do not always live in average volatility. The engine computes a simple volatility factor from ATR(20)/price and scales the simulated shocks up or down within sensible bounds (clamped between 0.5× and 2.0×). When the current regime is quiet, the cone narrows; when ranges expand, the cone widens. This prevents the classic mistake of projecting calm markets into a storm or vice versa.
4) Many futures, summarized by percentiles
The model generates a matrix of price paths (capped at 100 runs for performance inside TradingView), each path stepping forward for your selected horizon. For each forecast day it sorts the simulated prices and pulls key percentiles:
• 5th and 95th → approximate 95% band (outer cone).
• 16th and 84th → approximate 68% band (inner cone).
• 50th → the median or “expected path.”
These are drawn as polylines so you can immediately see central tendency and dispersion.
5) A historical overlay (optional)
Turn on the overlay to sketch a dotted path of what a purely seasonal projection would look like for the next ~30 days using only the return map, no randomness. This is not a forecast; it is a visual reminder of the seasonal drift you are biasing toward.
Inputs you control and how to think about them
Monte Carlo Simulation
• Price Series for Calculation . The source series, typically close.
• Enable Probability Forecasts . Master switch for simulation and drawing.
• Simulation Iterations . Requested number of paths to run. Internally capped at 100 to protect performance, which is generally enough to estimate the percentiles for a trading chart. If you need ultra-smooth bands, shorten the horizon.
• Forecast Days Ahead . The length of the cone. Longer horizons dilute seasonal signal and widen uncertainty.
• Probability Bands . Draw all bands, just 95%, just 68%, or a custom level (display logic remains 68/95 internally; the custom number is for labeling and color choice).
• Pattern Resolution . Daily leans on day-of-year effects like “turn-of-month” or holiday patterns. Weekly biases toward day-of-week tendencies and bootstraps from history.
• Volatility Scaling . On by default so the cone respects today’s range context.
Plotting & UI
• Probability Cone . Plots the outer and inner percentile envelopes.
• Expected Path . Plots the median line through the cone.
• Historical Overlay . Dotted seasonal-only projection for context.
• Band Transparency/Colors . Customize primary (outer) and secondary (inner) band colors and the mean path color. Use higher transparency for cleaner charts.
What appears on your chart
• A cone starting at the most recent bar, fanning outward. The outer lines are the ~95% band; the inner lines are the ~68% band.
• A median path (default blue) running through the center of the cone.
• An info panel on the final historical bar that summarizes simulation count, forecast days, number of seasonal patterns learned, the current day-of-year, expected percentage return to the median, and the approximate 95% half-range in percent.
• Optional historical seasonal path drawn as dotted segments for the next 30 bars.
How to use it in trading
1) Position sizing and stop logic
The cone translates “volatility plus seasonality” into distances.
• Put stops outside the inner band if you want only ~16% odds of a stop-out due to noise before your thesis can play.
• Size positions so that a test of the inner band is survivable and a test of the outer band is rare but acceptable.
• If your target sits inside the 68% band at your horizon, the payoff is likely modest; outside the 68% but inside the 95% can justify “one-good-push” trades; beyond the 95% band is a low-probability flyer—consider scaling plans or optionality.
2) Entry timing with seasonal bias
When the median path slopes up from this calendar date and the cone is relatively narrow, a pullback toward the lower inner band can be a high-quality entry with a tight invalidation. If the median slopes down, fade rallies toward the upper band or step aside if it clashes with your system.
3) Target selection
Project your time horizon to N bars ahead, then pick targets around the median or the opposite inner band depending on your style. You can also anchor dynamic take-profits to the moving median as new bars arrive.
4) Scenario planning & “what-ifs”
Before events, glance at the cone: if the 95% band already spans a huge range, trade smaller, expect whips, and avoid placing stops at obvious band edges. If the cone is unusually tight, consider breakout tactics and be ready to add if volatility expands beyond the inner band with follow-through.
5) Options and vol tactics
• When the cone is tight : Prefer long gamma structures (debit spreads) only if you expect a regime shift; otherwise premium selling may dominate.
• When the cone is wide : Debit structures benefit from range; credit spreads need wider wings or smaller size. Align with your separate IV metrics.
Reading the probability cone like a pro
• Cone slope = seasonal drift. Upward slope means the calendar has historically favored positive drift from this date, downward slope the opposite.
• Cone width = regime volatility. A widening fan tells you that uncertainty grows fast; a narrow cone says the market typically stays contained.
• Mean vs. price gap . If spot trades well above the median path and the upper band, mean-reversion risk is high. If spot presses the lower inner band in an up-sloping cone, you are in the “buy fear” zone.
• Touches and pierces . Touching the inner band is common noise; piercing it with momentum signals potential regime change; the outer band should be rare and often brings snap-backs unless there is a structural catalyst.
Methodological notes (what the code actually does)
• Log returns are used for additivity and better statistical behavior: sim_ret is applied via exp(sim_ret) to evolve price.
• Seasonal arrays are updated online with EWMA (90/10) so the model keeps learning as each bar arrives.
• Leap years are handled; indexing still normalizes into a 365-slot map so the seasonal pattern remains stable.
• Gaussian engine (Daily mode) centers shocks on the seasonal bias with a conservative standard deviation.
• Bootstrap engine (Weekly mode) resamples from observed seasonal returns and adds a fraction of the bias, which captures skew and fat tails better.
• Volatility adjustment multiplies each daily shock by a factor derived from ATR(20)/price, clamped between 0.5 and 2.0 to avoid extreme cones.
• Performance guardrails : simulations are capped at 100 paths; the probability cone uses polylines (no heavy fills) and only draws on the last confirmed bar to keep charts responsive.
• Prerequisite data : at least ~30 seasonal entries are required before the model will draw a cone; otherwise it waits for more history.
Strengths and limitations
• Strengths :
– Probabilistic thinking replaces single-point guessing.
– Seasonality adds a small but meaningful directional bias that many markets exhibit.
– Volatility scaling adapts to the current regime so the cone stays realistic.
• Limitations :
– Seasonality can break around structural changes, policy shifts, or one-off events.
– The number of paths is performance-limited; percentile estimates are good for trading, not for academic precision.
– The model assumes tomorrow’s randomness resembles recent randomness; if regime shifts violently, the cone will lag until the EWMA adapts.
– Holidays and missing sessions can thin the seasonal sample for some assets; be cautious with very short histories.
Tuning guide
• Horizon : 10–20 bars for tactical trades; 30+ for swing planning when you care more about broad ranges than precise targets.
• Iterations : The default 100 is enough for stable 5/16/50/84/95 percentiles. If you crave smoother lines, shorten the horizon or run on higher timeframes.
• Daily vs. Weekly : Daily for equities and crypto where month-end and turn-of-month effects matter; Weekly for futures and FX where day-of-week behavior is strong.
• Volatility scaling : Keep it on. Turn off only when you intentionally want a “pure seasonality” cone unaffected by current turbulence.
Workflow examples
• Swing continuation : Cone slopes up, price pulls into the lower inner band, your system fires. Enter near the band, stop just outside the outer line for the next 3–5 bars, target near the median or the opposite inner band.
• Fade extremes : Cone is flat or down, price gaps to the upper outer band on news, then stalls. Favor mean-reversion toward the median, size small if volatility scaling is elevated.
• Event play : Before CPI or earnings on a proxy index, check cone width. If the inner band is already wide, cut size or prefer options structures that benefit from range.
Good habits
• Pair the cone with your entry engine (breakout, pullback, order flow). Let Monte Carlo do range math; let your system do signal quality.
• Do not anchor blindly to the median; recalc after each bar. When the cone’s slope flips or width jumps, the plan should adapt.
• Validate seasonality for your symbol and timeframe; not every market has strong calendar effects.
Summary
The Seasonality Monte Carlo Forecaster wraps institutional risk planning into a single overlay: a data-driven seasonal drift, realistic volatility scaling, and a probabilistic cone that answers “where could we be, with what odds?” within your trading horizon. Use it to place stops where randomness is less likely to take you out, to set targets aligned with realistic travel, and to size positions with confidence born from distributions rather than hunches. It will not predict the future, but it will keep your decisions anchored to probabilities—the language markets actually speak.
Markov Chain Trend ProbabilityA Markov Chain is a mathematical model that predicts future states based on the current state, assuming that the future depends only on the present (not the past). Originally developed by Russian mathematician Andrey Markov, this concept is widely used in:
Finance: Risk modeling, portfolio optimization, credit scoring, algorithmic trading
Weather Forecasting: Predicting sunny/rainy days, temperature patterns, storm tracking
Here's an example of a Markov chain: If the weather is sunny, the probability that will be sunny 30 min later is say 90%. However, if the state changes, i.e. it starts raining, how the probability that will be raining 30 min later is say 70% and only 30% sunny.
Similar concept can be applied to markets price action and trends.
Mathematical Foundation
The core principle follows the Markov Property: P(X_{t+1}|X_t, X_{t-1}, ..., X_0) = P(X_{t+1}|X_t)
Transition Matrix :
-------------Next State
Current----
--------P11 P12
-----P21 P22
Probability Calculations:
P(Up→Up) = Count(Up→Up) / Count(Up states)
P(Down→Down) = Count(Down→Down) / Count(Down states)
Steady-state probability: π = πP (where π is the stationary distribution)
State Definition:
State = UPTREND if (Price_t - Price_{t-n})/ATR > threshold
State = DOWNTREND if (Price_t - Price_{t-n})/ATR < -threshold
How It Works in Trading
This indicator applies Markov Chain theory to market trends by:
Defining States: Classifies market conditions as UPTREND or DOWNTREND based on price movement relative to ATR (Average True Range)
Learning Transitions: Analyzes historical data to calculate probabilities of moving from one state to another
Predicting Probabilities: Estimates the likelihood of future trend continuation or reversal
How to Use
Parameters:
Lookback Period: Number of bars to analyze for trend detection (default: 14)
ATR Threshold: Sensitivity multiplier for state changes (default: 0.5)
Historical Periods: Sample size for probability calculations (default: 33)
Trading Applications:
Trend confirmation for entry/exit decisions
Risk assessment through probability analysis
Market regime identification
Early warning system for potential trend reversals
The indicator works on any timeframe and asset class. Enjoy!

Risk Distribution HistogramStatistical risk visualization and analysis tool for any ticker 📊
The Risk Distribution Histogram visualizes the statistical distribution of different risk metrics for any financial instrument. It converts risk data into histograms with quartile-based color coding, so that traders can understand their risk, tail-risks, exposure patterns and make data-driven decisions based on empirical evidence rather than assumptions.
The indicator supports multiple risk calculation methods, each designed for different aspects of market analysis, from general volatility assessment to tail risk analysis.
Risk Measurement Methods
Standard Deviation
Captures raw daily price volatility by measuring the dispersion of price movements. Ideal for understanding overall market conditions and timing volatility-based strategies.
Use case: Options trading and volatility analysis.
Average True Range (ATR)
Measures true range as a percentage of price, accounting for gaps and limit moves. Valuable for position sizing across different price levels.
Use case: Position sizing and stop-loss placement.
The chart above illustrates how ATR statistical distribution can be used by looking at the ATR % of price distribution. For example, 90% of the movements are below 5%.
Downside Deviation
Only considers negative price movements, making it ideal for checking downside risk and capital protection rather than capturing upside volatility.
Use case: Downside protection strategies and stop losses.
Drawdown Analysis
Tracks peak-to-trough declines, providing insight into maximum loss potential during different market conditions.
Use case: Risk management and capital preservation.
The chart above illustrates tale risk for the asset (TQQQ), showing that it is possible to have drawdowns higher than 20%.
Entropy-Based Risk (EVaR)
Uses information theory to quantify market uncertainty. Higher entropy values indicate more unpredictable price action, valuable for detecting regime changes.
Use case: Advanced risk modeling and tail-risk.
VIX Histogram
Incorporates the market's fear index directly into analysis, showing how current volatility expectations compare to historical patterns. The CAPITALCOM:VIX histogram is independent from the ticker on the chart.
Use case: Volatility trading and market timing.
Visual Features
The histogram uses quartile-based color coding that immediately shows where current risk levels stand relative to historical patterns:
Green (Q1): Low Risk (0-25th percentile)
Yellow (Q2): Medium-Low Risk (25-50th percentile)
Orange (Q3): Medium-High Risk (50-75th percentile)
Red (Q4): High Risk (75-100th percentile)
The data table provides detailed statistics, including:
Count Distribution: Historical observations in each bin
PMF: Percentage probability for each risk level
CDF: Cumulative probability up to each level
Current Risk Marker: Shows your current position in the distribution
Trading Applications
When current risk falls into upper quartiles (Q3 or Q4), it signals conditions are riskier than 50-75% of historical observations. This guides position sizing and portfolio adjustments.
Key applications:
Position sizing based on empirical risk distributions
Monitoring risk regime changes over time
Comparing risk patterns across timeframes
Risk distribution analysis improves trade timing by identifying when market conditions favor specific strategies.
Enter positions during low-risk periods (Q1)
Reduce exposure in high-risk periods (Q4)
Use percentile rankings for dynamic stop-loss placement
Time volatility strategies using distribution patterns
Detect regime shifts through distribution changes
Compare current conditions to historical benchmarks
Identify outlier events in tail regions
Validate quantitative models with empirical data
Configuration Options
Data Collection
Lookback Period: Control amount of historical data analyzed
Date Range Filtering: Focus on specific market periods
Sample Size Validation: Automatic reliability warnings
Histogram Customization
Bin Count: 10-50 bins for different detail levels
Auto/Manual Bin Width: Optimize for your data range
Visual Preferences: Custom colors and font sizes
Implementation Guide
Start with Standard Deviation on daily charts for the most intuitive introduction to distribution-based risk analysis.
Method Selection: Begin with Standard Deviation
Setup: Use daily charts with 20-30 bins
Interpretation: Focus on quartile transitions as signals
Monitoring: Track distribution changes for regime detection
The tool provides comprehensive statistics including mean, standard deviation, quartiles, and current position metrics like Z-score and percentile ranking.
Enjoy, and please let me know your feedback! 😊🥂

Liquidity Break Probability [PhenLabs]📊 Liquidity Break Probability
Version: PineScript™ v6
The Liquidity Break Probability indicator revolutionizes how traders approach liquidity levels by providing real-time probability calculations for level breaks. This advanced indicator combines sophisticated market analysis with machine learning inspired probability models to predict the likelihood of high/low breaks before they happen.
Unlike traditional liquidity indicators that simply draw lines, LBP analyzes market structure, volume profiles, momentum, volatility, and sentiment to generate dynamic break probabilities ranging from 5% to 95%. This gives traders unprecedented insight into which levels are most likely to hold or break, enabling more confident trading decisions.
🚀 Points of Innovation
Advanced 6-factor probability model weighing market structure, volatility, volume, momentum, patterns, and sentiment
Real-time probability updates that adjust as market conditions change
Intelligent trading style presets (Scalping, Day Trading, Swing Trading) with optimized parameters
Dynamic color-coded probability labels showing break likelihood percentages
Professional tiered input system - from quick setup to expert-level customization
Smart volume filtering that only highlights levels with significant institutional interest
🔧 Core Components
Market Structure Analysis: Evaluates trend alignment, level strength, and momentum buildup using EMA crossovers and price action
Volatility Engine: Incorporates ATR expansion, Bollinger Band positioning, and price distance calculations
Volume Profile System: Analyzes current volume strength, smart money proxies, and level creation volume ratios
Momentum Calculator: Combines RSI positioning, MACD strength, and momentum divergence detection
Pattern Recognition: Identifies reversal patterns (doji, hammer, engulfing) near key levels
Sentiment Analysis: Processes fear/greed indicators and market breadth measurements
🔥 Key Features
Dynamic Probability Labels: Real-time percentage displays showing break probability with color coding (red >70%, orange >50%, white <50%)
Trading Style Optimization: One-click presets automatically configure sensitivity and parameters for your trading timeframe
Professional Dashboard: Live market state monitoring with nearest level tracking and active level counts
Smart Alert System: Customizable proximity alerts and high-probability break notifications
Advanced Level Management: Intelligent line cleanup and historical analysis options
Volume-Validated Levels: Only displays levels backed by significant volume for institutional-grade analysis
🎨 Visualization
Recent Low Lines: Red lines marking validated support levels with probability percentages
Recent High Lines: Blue lines showing resistance zones with break likelihood indicators
Probability Labels: Color-coded percentage labels that update in real-time
Professional Dashboard: Customizable panel showing market state, active levels, and current price
Clean Display Modes: Toggle between active-only view for clean charts or historical view for analysis
📖 Usage Guidelines
Quick Setup
Trading Style Preset
Default: Day Trading
Options: Scalping, Day Trading, Swing Trading, Custom
Description: Automatically optimizes all parameters for your preferred trading timeframe and style
Show Break Probability %
Default: True
Description: Displays percentage labels next to each level showing break probability
Line Display
Default: Active Only
Options: Active Only, All Levels
Description: Choose between clean active-only view or comprehensive historical analysis
Level Detection Settings
Level Sensitivity
Default: 5
Range: 1-20
Description: Lower values show more levels (sensitive), higher values show fewer levels (selective)
Volume Filter Strength
Default: 2.0
Range: 0.5-5.0
Description: Controls minimum volume threshold for level validation
Advanced Probability Model
Market Trend Influence
Default: 25%
Range: 0-50%
Description: Weight given to overall market trend in probability calculations
Volume Influence
Default: 20%
Range: 0-50%
Description: Impact of volume analysis on break probability
✅ Best Use Cases
Identifying high-probability breakout setups before they occur
Determining optimal entry and exit points near key levels
Risk management through probability-based position sizing
Confluence trading when multiple high-probability levels align
Scalping opportunities at levels with low break probability
Swing trading setups using high-probability level breaks
⚠️ Limitations
Probability calculations are estimations based on historical patterns and current market conditions
High-probability setups do not guarantee successful trades - risk management is essential
Performance may vary significantly across different market conditions and asset classes
Requires understanding of support/resistance concepts and probability-based trading
Best used in conjunction with other analysis methods and proper risk management
💡 What Makes This Unique
Probability-Based Approach: First indicator to provide quantitative break probabilities rather than simple S/R lines
Multi-Factor Analysis: Combines 6 different market factors into a comprehensive probability model
Adaptive Intelligence: Probabilities update in real-time as market conditions change
Professional Interface: Tiered input system from beginner-friendly to expert-level customization
Institutional-Grade Filtering: Volume validation ensures only significant levels are displayed
🔬 How It Works
1. Level Detection:
Identifies pivot highs and lows using configurable sensitivity settings
Validates levels with volume analysis to ensure institutional significance
2. Probability Calculation:
Analyzes 6 key market factors: structure, volatility, volume, momentum, patterns, sentiment
Applies weighted scoring system based on user-defined factor importance
Generates probability score from 5% to 95% for each level
3. Real-Time Updates:
Continuously monitors price action and market conditions
Updates probability calculations as new data becomes available
Adjusts for level touches and changing market dynamics
💡 Note: This indicator works best on timeframes from 1-minute to 4-hour charts. For optimal results, combine with proper risk management and consider multiple timeframe analysis. The probability calculations are most accurate in trending markets with normal to high volatility conditions.
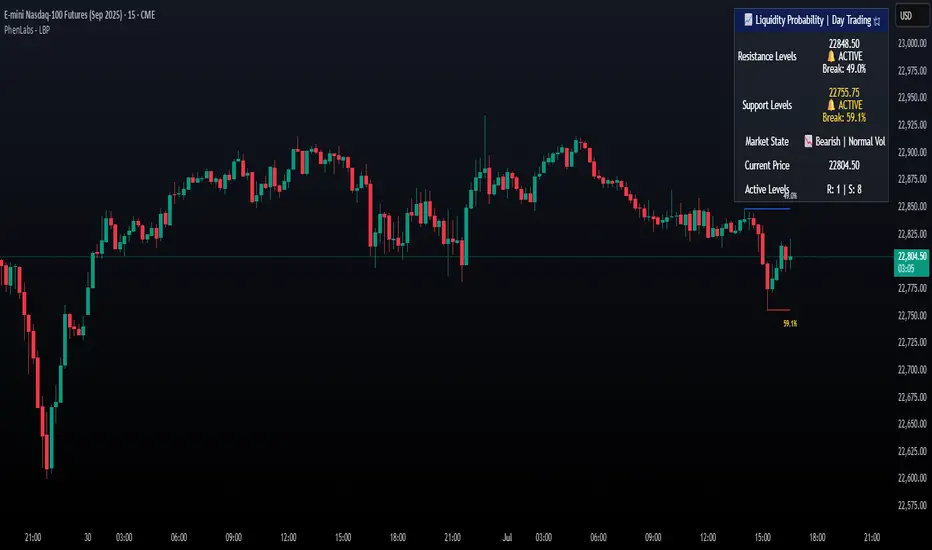
Leavitt Convolution ProbabilityTechnical Analysis of Markets with Leavitt Market Projections and Associated Convolution Probability
The aim of this study is to present an innovative approach to market analysis based on the research "Leavitt Market Projections." This technical tool combines one indicator and a probability function to enhance the accuracy and speed of market forecasts.
Key Features
Advanced Indicators : the script includes the Convolution line and a probability oscillator, designed to anticipate market changes. These indicators provide timely signals and offer a clear view of price dynamics.
Convolution Probability Function : The Convolution Probability (CP) is a key element of the script. A significant increase in this probability often precedes a market decline, while a decrease in probability can signal a bullish move. The Convolution Probability Function:
At each bar, i, the linear regression routine finds the two parameters for the straight line: y=mix+bi.
Standard deviations can be calculated from the sequence of slopes, {mi}, and intercepts, {bi}.
Each standard deviation has a corresponding probability.
Their adjusted product is the Convolution Probability, CP. The construction of the Convolution Probability is straightforward. The adjusted product is the probability of one times 1− the probability of the other.
Customizable Settings : Users can define oversold and overbought levels, as well as set an offset for the linear regression calculation. These options allow for tailoring the script to individual trading strategies and market conditions.
Statistical Analysis : Each analyzed bar generates regression parameters that allow for the calculation of standard deviations and associated probabilities, providing an in-depth view of market dynamics.
The results from applying this technical tool show increased accuracy and speed in market forecasts. The combination of Convolution indicator and the probability function enables the identification of turning points and the anticipation of market changes.
Additional information:
Leavitt, in his study, considers the SPY chart.
When the Convolution Probability (CP) is high, it indicates that the probability P1 (related to the slope) is high, and conversely, when CP is low, P1 is low and P2 is high.
For the calculation of probability, an approximate formula of the Cumulative Distribution Function (CDF) has been used, which is given by: CDF(x)=21(1+erf(σ2x−μ)) where μ is the mean and σ is the standard deviation.
For the calculation of probability, the formula used in this script is: 0.5 * (1 + (math.sign(zSlope) * math.sqrt(1 - math.exp(-0.5 * zSlope * zSlope))))
Conclusions
This study presents the approach to market analysis based on the research "Leavitt Market Projections." The script combines Convolution indicator and a Probability function to provide more precise trading signals. The results demonstrate greater accuracy and speed in market forecasts, making this technical tool a valuable asset for market participants.
Probability Grid [LuxAlgo]The Probability Grid tool allows traders to see the probability of where and when the next reversal would occur, it displays a 10x10 grid and/or dashboard with the probability of the next reversal occurring beyond each cell or within each cell.
🔶 USAGE
By default, the tool displays deciles (percentiles from 0 to 90), users can enable, disable and modify each percentile, but two of them must always be enabled or the tool will display an error message alerting of it.
The use of the tool is quite simple, as shown in the chart above, the further the price moves on the grid, the higher the probability of a reversal.
In this case, the reversal took place on the cell with a probability of 9%, which means that there is a probability of 91% within the square defined by the last reversal and this cell.
🔹 Grid vs Dashboard
The tool can display a grid starting from the last reversal and/or a dashboard at three predefined locations, as shown in the chart above.
🔶 DETAILS
🔹 Raw Data vs Normalized Data
By default the tool displays the normalized data, this means that instead of using the raw data (price delta between reversals) it uses the returns between each reversal, this is useful to make an apples to apples comparison of all the data in the dataset.
This can be seen in the left side of the chart above (BTCUSD Daily chart) where normalize data is disabled, the percentiles from 0 to 40 overlap and are indistinguishable from each other because the tool uses the raw price delta over the entire bitcoin history, with normalize data enabled as we can see in the right side of the chart we can have a fair comparison of the data over the entire history.
🔹 Probability Beyond or Within Each Cell
Two different probability modes are available, the default mode is Probability Beyond Each Cell, the number displayed in each cell is the probability of the next reversal to be located in the area beyond the cell, for example, if the cell displays 20%, it means that in the area formed by the square starting from the last reversal and ending at the cell, there is an 80% probability and outside that square there is a 20% probability for the location of the next reversal.
The second probability mode is the probability within each cell, this outlines the chance that the next reversal will be within the cell, as we can see on the right chart above, when using deciles as percentiles (default settings), each cell has the same 1% probability for the 10x10 grid.
🔶 SETTINGS
Swing Length: The maximum length in bars used to identify a swing
Maximum Reversals: Maximum number of reversals included in calculations
Normalize Data: Use returns between swings instead of raw price
Probability: Choose between two different probability modes: beyond and inside each cell
Percentiles: Enable/disable each of the ten percentiles and select the percentile number and line style
🔹 Dashboard
Show Dashboard: Enable or disable the dashboard
Position: Choose dashboard location
Size: Choose dashboard size
🔹 Style
Show Grid: Enable or disable the grid
Size: Choose grid text size
Colors: Choose grid background colors
Show Marks: Enable/disable reversal markers

SuperTrend + Relative Volume (Kernel Optimized)Introducing our new KDE Optimized Supertrend + Relative Volume Indicator!
This innovative indicator combines the power of the Supertrend indicator along with Relative Volume. It utilizes the Kernel Density Estimation (KDE) to estimate the probability of a candlestick marking a significant trend break or reversal.
❓How to Interpret the KDE %:
The KDE % is a crucial metric that reflects the likelihood that the current candlestick represents a true break in the SuperTrend line, supported by an increase in relative volume. It estimates the probability of a trend shift or continuation based on historical SuperTrend breaks and volume patterns:
Low KDE %: A lower probability that the current break is significant. Price action is less likely to reverse, and the trend may continue.
Moderate KDE - High KDE %: An increased possibility that a trend reversal or consolidation could occur. Traders should start watching for confirmation signals.
📌How Does It Work?
The SuperTrend indicator uses the Average True Range (ATR) to determine the direction of the trend and identifies when the price crosses the SuperTrend line, signaling a potential trend reversal. Here's how the KDE Optimized SuperTrend Indicator works:
SuperTrend Calculation: The SuperTrend indicator is calculated, and when the price breaks above (bullish) or below (bearish) the SuperTrend line, it is logged as a significant event.
Relative Volume: For each break in the SuperTrend line, we calculate the relative volume (current volume vs. the average volume over a defined period). High relative volume can suggest stronger confirmation of the trend break.
KDE Array Calculation: KDE is applied to the break points and relative volume data:
Define the KDE options: Bandwidth, Number of Steps, and Array Range (Array Max - Array Min).
Create a density range array using the defined number of steps, corresponding to potential break points.
Apply a Gaussian kernel function to the break points and volume data to estimate the likelihood of the trend break being significant.
KDE Value and Signal Generation: The KDE array is updated as each break occurs. The KDE % is calculated for the breakout candlestick, representing the likelihood of the trend break being significant. If the KDE value exceeds the defined activation threshold, a darker bullish or bearish arrow is plotted after bar confirmation. If the KDE value falls below the threshold, a more transparent arrow is drawn, indicating a possible but lower probability break.
⚙️Settings:
SuperTrend Settings:
ATR Length: The period over which the Average True Range (ATR) is calculated.
Multiplier: The multiplier applied to the ATR to determine the SuperTrend threshold.
KDE Settings:
Bandwidth: Determines the smoothness of the KDE function and the width of the influence of each break point.
Number of Bins (Steps): Defines the precision of the KDE algorithm, with higher values offering more detailed calculations.
KDE Threshold %: The level at which relative volume is considered significant for confirming a break.
Relative Volume Length: The number of historic candles used in calculating KDE %